 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Lin-Kernighan-Helsgaun Algorithms for the Traveling Salesman Problems
Paper and Code
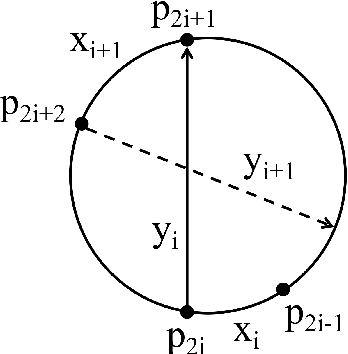
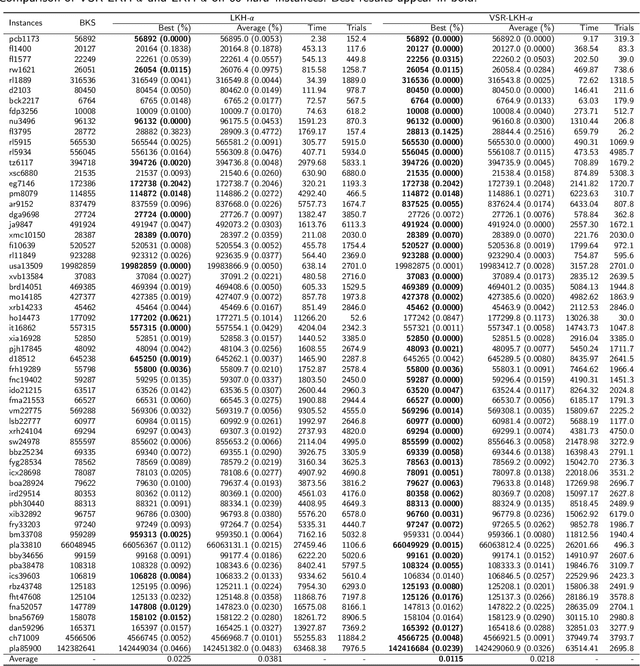

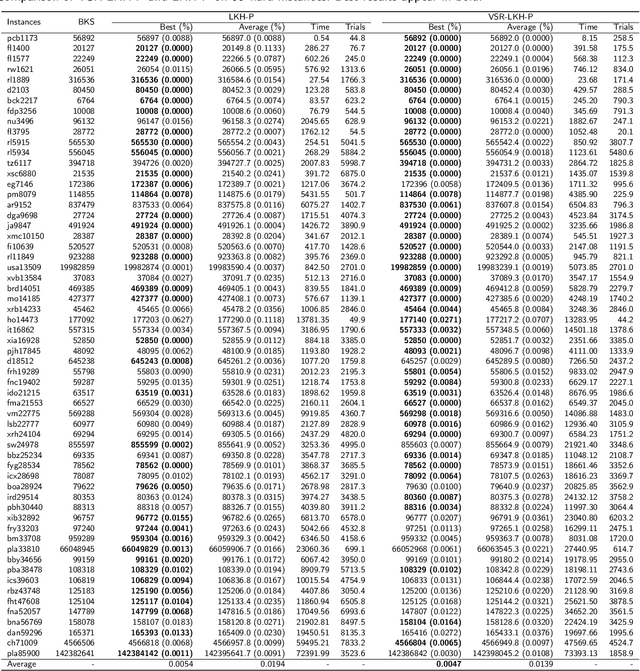
TSP is a classical NP-hard combinatorial optimization problem with many practical variants. LKH is one of the state-of-the-art local search algorithms for the TSP. LKH-3 is a powerful extension of LKH that can solve many TSP variants. Both LKH and LKH-3 associate a candidate set to each city to improve the efficiency, and have two different methods, $\alpha$-measure and POPMUSIC, to decide the candidate sets. In this work, we first propose a Variable Strategy Reinforced LKH (VSR-LKH) algorithm, which incorporates three reinforcement learning methods (Q-learning, Sarsa, Monte Carlo) with LKH, for the TSP. We further propose a new algorithm called VSR-LKH-3 that combines the variable strategy reinforcement learning method with LKH-3 for typical TSP variants, including the TSP with time windows (TSPTW) and Colored TSP (CTSP). The proposed algorithms replace the inflexible traversal operations in LKH and LKH-3 and let the algorithms learn to make a choice at each search step by reinforcement learning. Both LKH and LKH-3, with either $\alpha$-measure or POPMUSIC, can be significantly improved by our methods. Extensive experiments on 236 widely-used TSP benchmarks with up to 85,900 cities demonstrate the excellent performance of VSR-LKH. VSR-LKH-3 also significantly outperforms the state-of-the-art heuristics for TSPTW and CTSP.