 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Pruning with Residual-Connections and Limited-Data
Dec 02, 2019
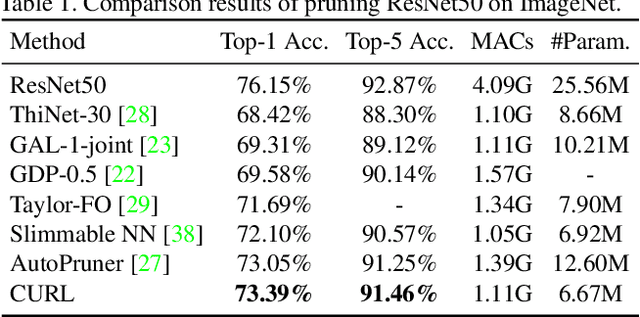
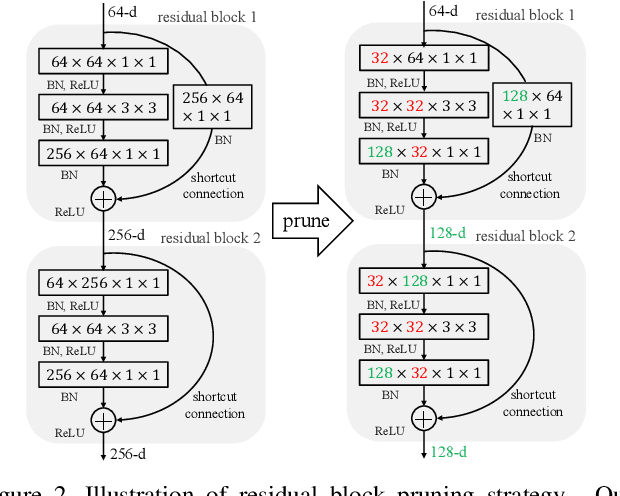
Filter level pruning is an effective method to accelerate the inference speed of deep CNN models. Although numerous pruning algorithms have been proposed, there are still two open issues. The first problem is how to prune residual connections. Most previous filter level pruning algorithms only prune channels inside residual blocks, leaving the number of output channels unchanged. We show that pruning both channels inside and outside the residual connections is crucial to achieve better performance. The second issue is pruning with limited data. We observe an interesting phenomenon: directly pruning on a small dataset is usually worse than fine-tuning a small model which is pruned or trained from scratch on the large dataset. In this paper, we propose a novel method, namely Compression Using Residual-connections and Limited-data (CURL), to tackle these two challenges. Experiments on the large scale dataset demonstrate the effectiveness of CURL. CURL significantly outperforms previous state-of-the-art methods on ImageNet. More importantly, when pruning on small datasets, CURL achieves comparable or much better performance than fine-tuning a pretrained small model.
AutoPruner: An End-to-End Trainable Filter Pruning Method for Efficient Deep Model Inference
May 24, 2018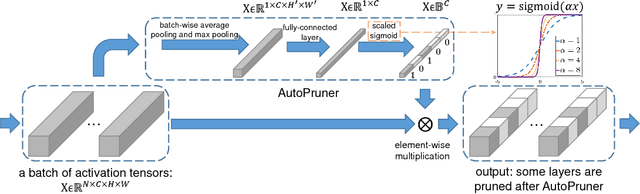
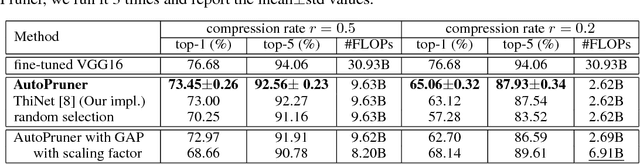
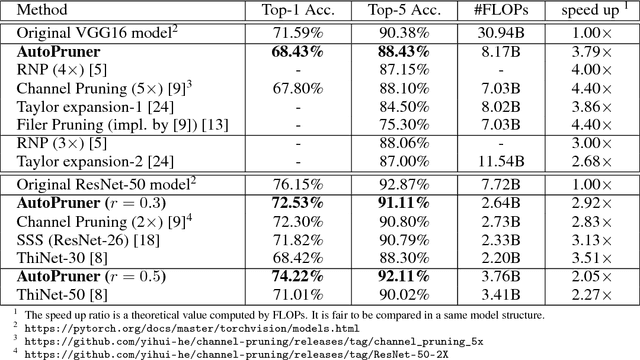
Channel pruning is an important family of methods to speedup deep model's inference. Previous filter pruning algorithms regard channel pruning and model fine-tuning as two independent steps. This paper argues that combining them in a single end-to-end trainable system will lead to better results. We propose an efficient channel selection layer, namely AutoPruner, to find less important filters automatically in a joint training manner. AutoPruner takes previous activation responses as input and generates a true binary index code for pruning. Hence, all the filters corresponding to zero index values can be removed safely after training. We empirically demonstrate that the gradient information of this channel selection layer is also helpful for the whole model training. Compared with previous state-of-the-art pruning algorithms, AutoPruner achieves significantly better performance. Furthermore, ablation experiments show that the proposed novel mini-batch pooling and binarization operations are vital for the success of filter pruning.
Learning Effective Binary Visual Representations with Deep Networks
Mar 08, 2018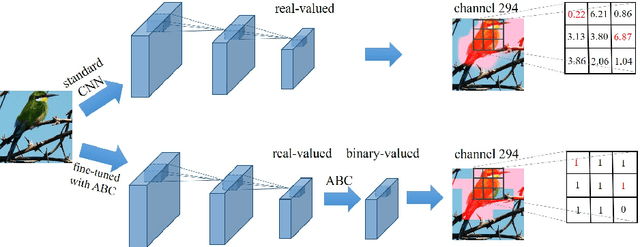
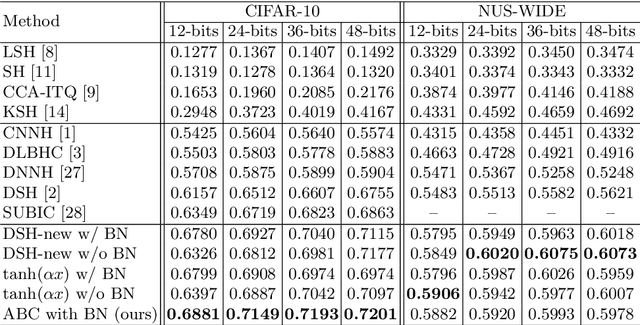
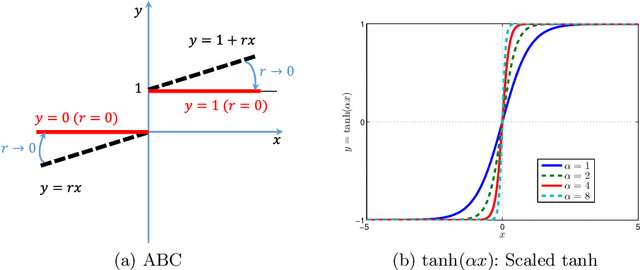
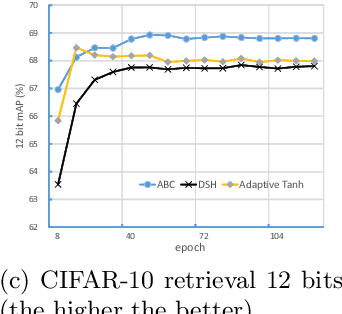
Although traditionally binary visual representations are mainly designed to reduce computational and storage costs in the image retrieval research, this paper argues that binary visual representations can be applied to large scale recognition and detection problems in addition to hashing in retrieval. Furthermore, the binary nature may make it generalize better than its real-valued counterparts. Existing binary hashing methods are either two-stage or hinging on loss term regularization or saturated functions, hence converge slowly and only emit soft binary values. This paper proposes Approximately Binary Clamping (ABC), which is non-saturating, end-to-end trainable, with fast convergence and can output true binary visual representations. ABC achieves comparable accuracy in ImageNet classification as its real-valued counterpart, and even generalizes better in object detection. On benchmark image retrieval datasets, ABC also outperforms existing hashing methods.
ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression
Jul 20, 2017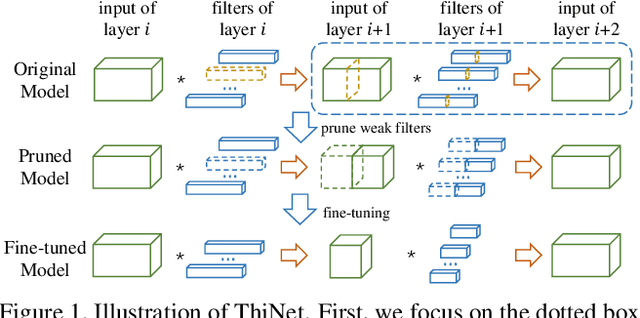
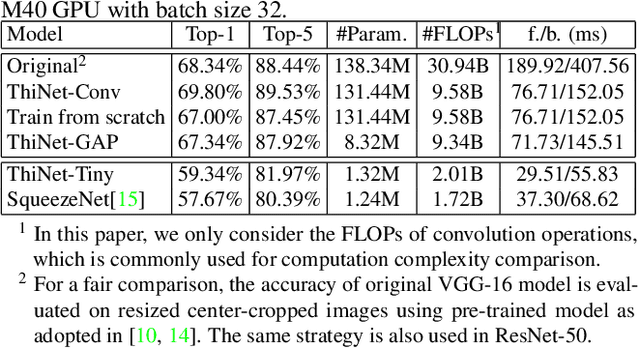
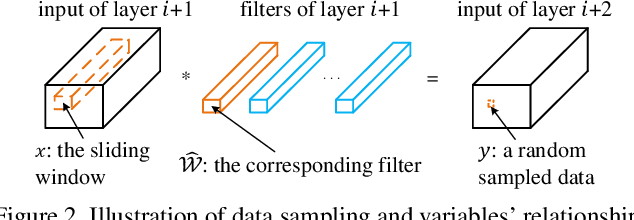
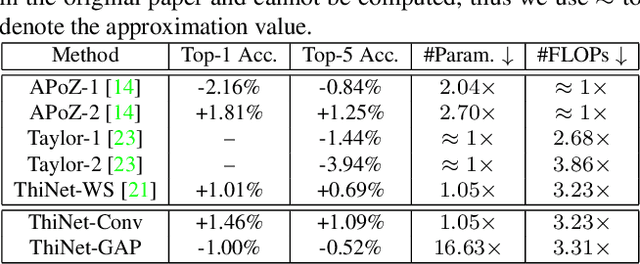
We propose an efficient and unified framework, namely ThiNet, to simultaneously accelerate and compress CNN models in both training and inference stages. We focus on the filter level pruning, i.e., the whole filter would be discarded if it is less important. Our method does not change the original network structure, thus it can be perfectly supported by any off-the-shelf deep learning libraries. We formally establish filter pruning as an optimization problem, and reveal that we need to prune filters based on statistics information computed from its next layer, not the current layer, which differentiates ThiNet from existing methods. Experimental results demonstrate the effectiveness of this strategy, which has advanced the state-of-the-art. We also show the performance of ThiNet on ILSVRC-12 benchmark. ThiNet achieves 3.31$\times$ FLOPs reduction and 16.63$\times$ compression on VGG-16, with only 0.52$\%$ top-5 accuracy drop. Similar experiments with ResNet-50 reveal that even for a compact network, ThiNet can also reduce more than half of the parameters and FLOPs, at the cost of roughly 1$\%$ top-5 accuracy drop. Moreover, the original VGG-16 model can be further pruned into a very small model with only 5.05MB model size, preserving AlexNet level accuracy but showing much stronger generalization ability.
Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval
Jul 13, 2017
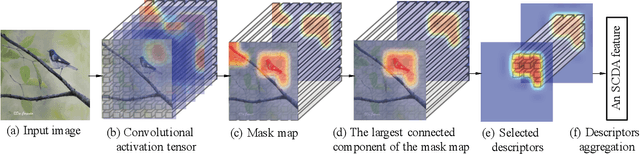


Deep convolutional neural network models pre-trained for the ImageNet classification task have been successfully adopted to tasks in other domains, such as texture description and object proposal generation, but these tasks require annotations for images in the new domain. In this paper, we focus on a novel and challenging task in the pure unsupervised setting: fine-grained image retrieval. Even with image labels, fine-grained images are difficult to classify, let alone the unsupervised retrieval task. We propose the Selective Convolutional Descriptor Aggregation (SCDA) method. SCDA firstly localizes the main object in fine-grained images, a step that discards the noisy background and keeps useful deep descriptors. The selected descriptors are then aggregated and dimensionality reduced into a short feature vector using the best practices we found. SCDA is unsupervised, using no image label or bounding box annotation. Experiments on six fine-grained datasets confirm the effectiveness of SCDA for fine-grained image retrieval. Besides, visualization of the SCDA features shows that they correspond to visual attributes (even subtle ones), which might explain SCDA's high mean average precision in fine-grained retrieval. Moreover, on general image retrieval datasets, SCDA achieves comparable retrieval results with state-of-the-art general image retrieval approaches.
An Entropy-based Pruning Method for CNN Compression
Jun 19, 2017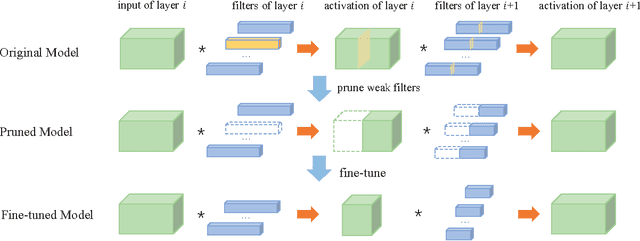
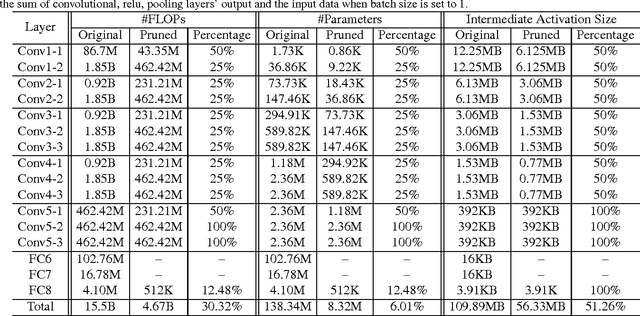
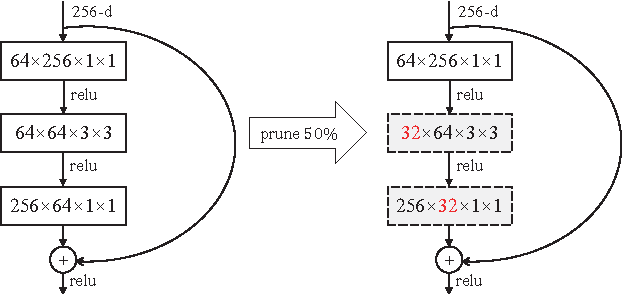
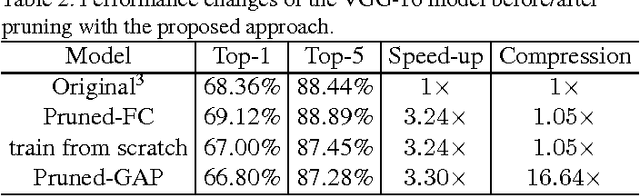
This paper aims to simultaneously accelerate and compress off-the-shelf CNN models via filter pruning strategy. The importance of each filter is evaluated by the proposed entropy-based method first. Then several unimportant filters are discarded to get a smaller CNN model. Finally, fine-tuning is adopted to recover its generalization ability which is damaged during filter pruning. Our method can reduce the size of intermediate activations, which would dominate most memory footprint during model training stage but is less concerned in previous compression methods. Experiments on the ILSVRC-12 benchmark demonstrate the effectiveness of our method. Compared with previous filter importance evaluation criteria, our entropy-based method obtains better performance. We achieve 3.3x speed-up and 16.64x compression on VGG-16, 1.54x acceleration and 1.47x compression on ResNet-50, both with about 1% top-5 accuracy decrease.
Dense CNN Learning with Equivalent Mappings
May 24, 2016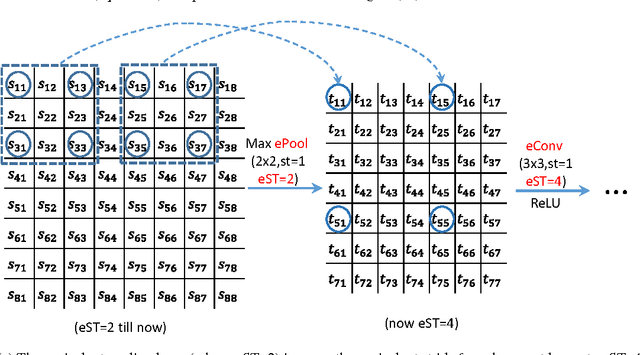
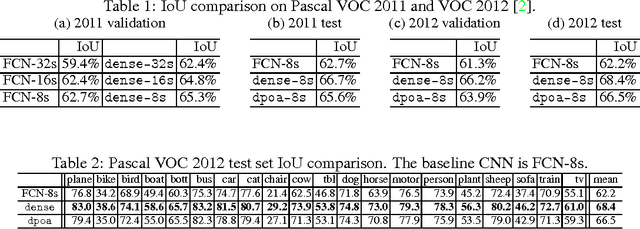
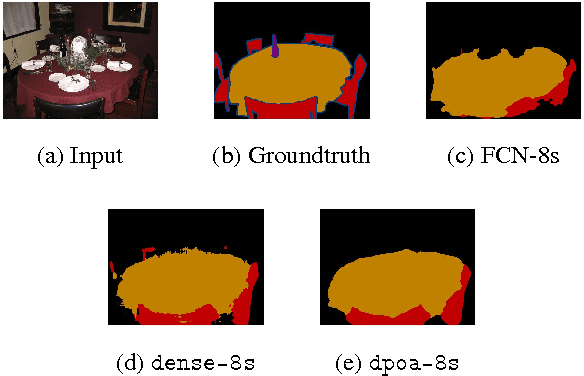

Large receptive field and dense prediction are both important for achieving high accuracy in pixel labeling tasks such as semantic segmentation. These two properties, however, contradict with each other. A pooling layer (with stride 2) quadruples the receptive field size but reduces the number of predictions to 25\%. Some existing methods lead to dense predictions using computations that are not equivalent to the original model. In this paper, we propose the equivalent convolution (eConv) and equivalent pooling (ePool) layers, leading to predictions that are both dense and equivalent to the baseline CNN model. Dense prediction models learned using eConv and ePool can transfer the baseline CNN's parameters as a starting point, and can inverse transfer the learned parameters in a dense model back to the original one, which has both fast testing speed and high accuracy. The proposed eConv and ePool layers have achieved higher accuracy than baseline CNN in various tasks, including semantic segmentation, object localization, image categorization and apparent age estimation, not only in those tasks requiring dense pixel labeling.