 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval
Paper and Code
Jul 13, 2017
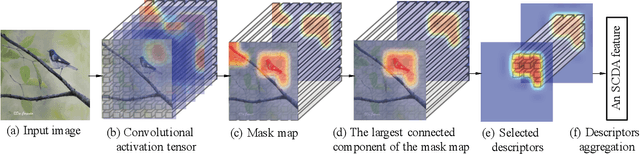


Deep convolutional neural network models pre-trained for the ImageNet classification task have been successfully adopted to tasks in other domains, such as texture description and object proposal generation, but these tasks require annotations for images in the new domain. In this paper, we focus on a novel and challenging task in the pure unsupervised setting: fine-grained image retrieval. Even with image labels, fine-grained images are difficult to classify, let alone the unsupervised retrieval task. We propose the Selective Convolutional Descriptor Aggregation (SCDA) method. SCDA firstly localizes the main object in fine-grained images, a step that discards the noisy background and keeps useful deep descriptors. The selected descriptors are then aggregated and dimensionality reduced into a short feature vector using the best practices we found. SCDA is unsupervised, using no image label or bounding box annotation. Experiments on six fine-grained datasets confirm the effectiveness of SCDA for fine-grained image retrieval. Besides, visualization of the SCDA features shows that they correspond to visual attributes (even subtle ones), which might explain SCDA's high mean average precision in fine-grained retrieval. Moreover, on general image retrieval datasets, SCDA achieves comparable retrieval results with state-of-the-art general image retrieval approaches.