 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Entropy-based Pruning Method for CNN Compression
Paper and Code
Jun 19, 2017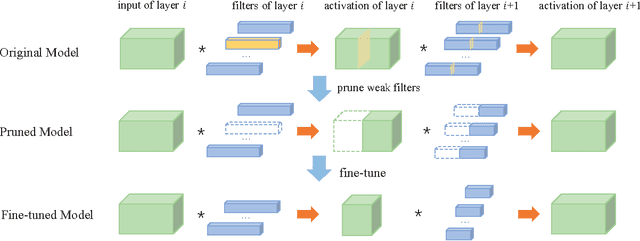
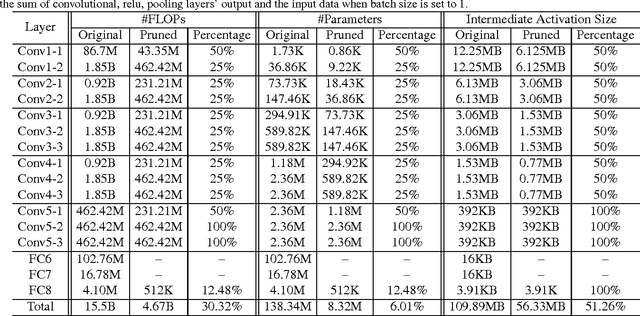
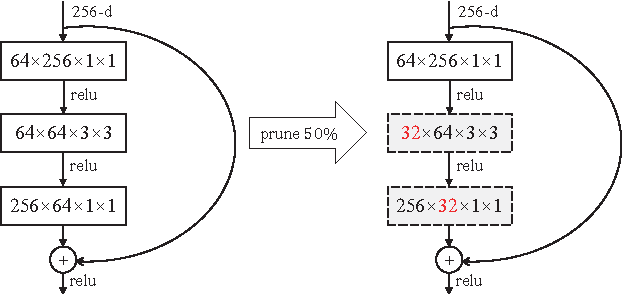
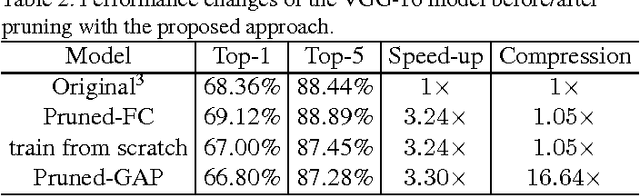
This paper aims to simultaneously accelerate and compress off-the-shelf CNN models via filter pruning strategy. The importance of each filter is evaluated by the proposed entropy-based method first. Then several unimportant filters are discarded to get a smaller CNN model. Finally, fine-tuning is adopted to recover its generalization ability which is damaged during filter pruning. Our method can reduce the size of intermediate activations, which would dominate most memory footprint during model training stage but is less concerned in previous compression methods. Experiments on the ILSVRC-12 benchmark demonstrate the effectiveness of our method. Compared with previous filter importance evaluation criteria, our entropy-based method obtains better performance. We achieve 3.3x speed-up and 16.64x compression on VGG-16, 1.54x acceleration and 1.47x compression on ResNet-50, both with about 1% top-5 accuracy decrease.