 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Effectiveness of Skip-Tuning in Diffusion Sampling
Feb 23, 2024



With the incorporation of the UNet architecture, diffusion probabilistic models have become a dominant force in image generation tasks. One key design in UNet is the skip connections between the encoder and decoder blocks. Although skip connections have been shown to improve training stability and model performance, we reveal that such shortcuts can be a limiting factor for the complexity of the transformation. As the sampling steps decrease, the generation process and the role of the UNet get closer to the push-forward transformations from Gaussian distribution to the target, posing a challenge for the network's complexity. To address this challenge, we propose Skip-Tuning, a simple yet surprisingly effective training-free tuning method on the skip connections. Our method can achieve 100% FID improvement for pretrained EDM on ImageNet 64 with only 19 NFEs (1.75), breaking the limit of ODE samplers regardless of sampling steps. Surprisingly, the improvement persists when we increase the number of sampling steps and can even surpass the best result from EDM-2 (1.58) with only 39 NFEs (1.57). Comprehensive exploratory experiments are conducted to shed light on the surprising effectiveness. We observe that while Skip-Tuning increases the score-matching losses in the pixel space, the losses in the feature space are reduced, particularly at intermediate noise levels, which coincide with the most effective range accounting for image quality improvement.
Elucidating The Design Space of Classifier-Guided Diffusion Generation
Oct 17, 2023Guidance in conditional diffusion generation is of great importance for sample quality and controllability. However, existing guidance schemes are to be desired. On one hand, mainstream methods such as classifier guidance and classifier-free guidance both require extra training with labeled data, which is time-consuming and unable to adapt to new conditions. On the other hand, training-free methods such as universal guidance, though more flexible, have yet to demonstrate comparable performance. In this work, through a comprehensive investigation into the design space, we show that it is possible to achieve significant performance improvements over existing guidance schemes by leveraging off-the-shelf classifiers in a training-free fashion, enjoying the best of both worlds. Employing calibration as a general guideline, we propose several pre-conditioning techniques to better exploit pretrained off-the-shelf classifiers for guiding diffusion generation. Extensive experiments on ImageNet validate our proposed method, showing that state-of-the-art diffusion models (DDPM, EDM, DiT) can be further improved (up to 20%) using off-the-shelf classifiers with barely any extra computational cost. With the proliferation of publicly available pretrained classifiers, our proposed approach has great potential and can be readily scaled up to text-to-image generation tasks. The code is available at https://github.com/AlexMaOLS/EluCD/tree/main.
Deciphering the Projection Head: Representation Evaluation Self-supervised Learning
Jan 28, 2023Self-supervised learning (SSL) aims to learn intrinsic features without labels. Despite the diverse architectures of SSL methods, the projection head always plays an important role in improving the performance of the downstream task. In this work, we systematically investigate the role of the projection head in SSL. Specifically, the projection head targets the uniformity part of SSL, which pushes the dissimilar samples away from each other, thus enabling the encoder to focus on extracting semantic features. Based on this understanding, we propose a Representation Evaluation Design (RED) in SSL models in which a shortcut connection between the representation and the projection vectors is built. Extensive experiments with different architectures, including SimCLR, MoCo-V2, and SimSiam, on various datasets, demonstrate that the representation evaluation design can consistently improve the baseline models in the downstream tasks. The learned representation from the RED-SSL models shows superior robustness to unseen augmentations and out-of-distribution data.
Fast Kernel k-means Clustering Using Incomplete Cholesky Factorization
Feb 07, 2020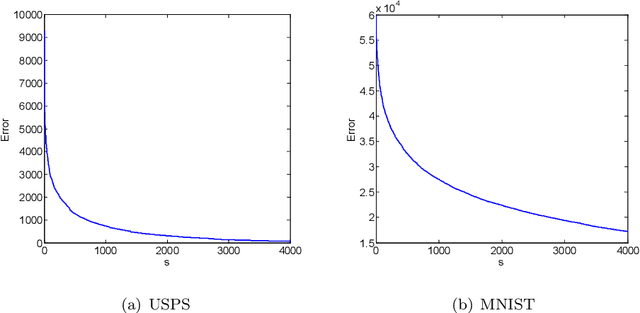
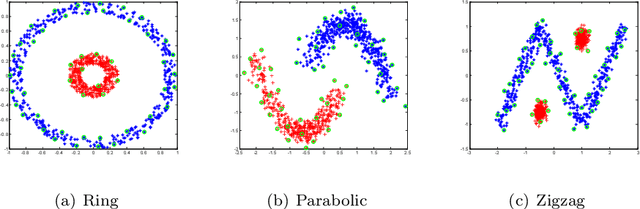
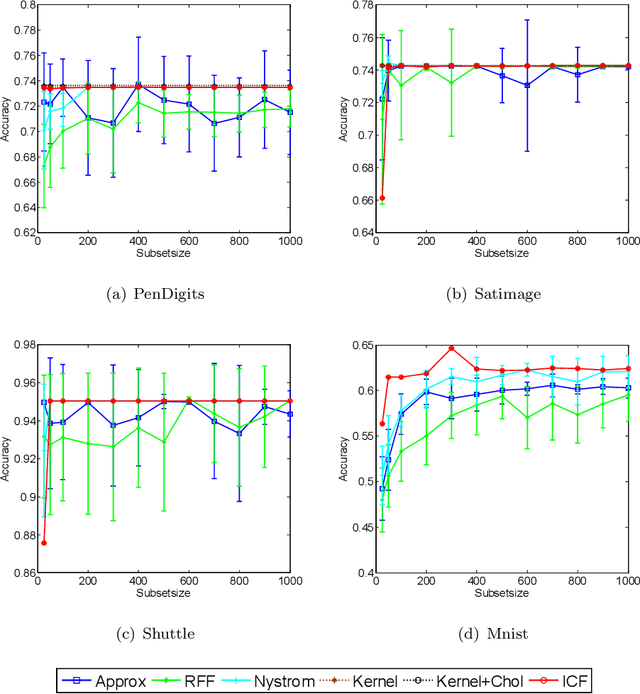
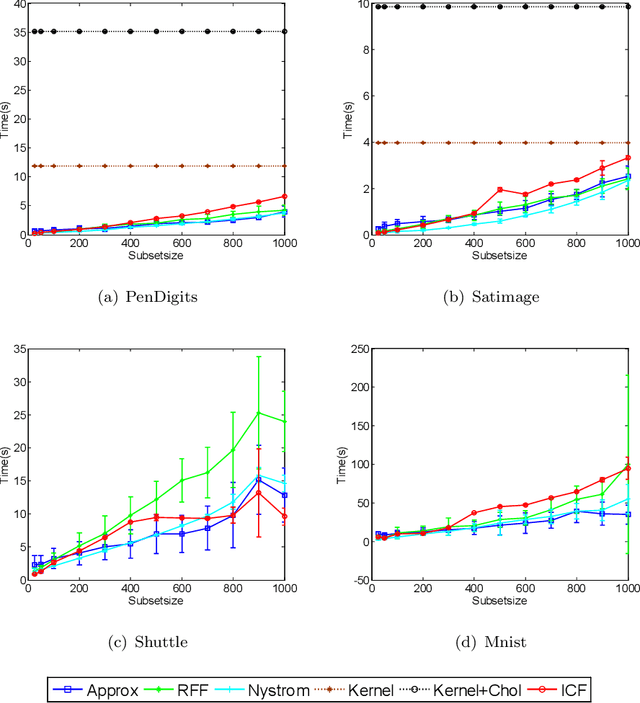
Kernel-based clustering algorithm can identify and capture the non-linear structure in datasets, and thereby it can achieve better performance than linear clustering. However, computing and storing the entire kernel matrix occupy so large memory that it is difficult for kernel-based clustering to deal with large-scale datasets. In this paper, we employ incomplete Cholesky factorization to accelerate kernel clustering and save memory space. The key idea of the proposed kernel $k$-means clustering using incomplete Cholesky factorization is that we approximate the entire kernel matrix by the product of a low-rank matrix and its transposition. Then linear $k$-means clustering is applied to columns of the transpose of the low-rank matrix. We show both analytically and empirically that the performance of the proposed algorithm is similar to that of the kernel $k$-means clustering algorithm, but our method can deal with large-scale datasets.
Stable Sparse Subspace Embedding for Dimensionality Reduction
Feb 07, 2020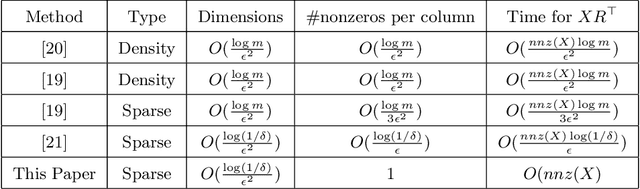


Sparse random projection (RP) is a popular tool for dimensionality reduction that shows promising performance with low computational complexity. However, in the existing sparse RP matrices, the positions of non-zero entries are usually randomly selected. Although they adopt uniform sampling with replacement, due to large sampling variance, the number of non-zeros is uneven among rows of the projection matrix which is generated in one trial, and more data information may be lost after dimension reduction. To break this bottleneck, based on random sampling without replacement in statistics, this paper builds a stable sparse subspace embedded matrix (S-SSE), in which non-zeros are uniformly distributed. It is proved that the S-SSE is stabler than the existing matrix, and it can maintain Euclidean distance between points well after dimension reduction. Our empirical studies corroborate our theoretical findings and demonstrate that our approach can indeed achieve satisfactory performance.