 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Database for Research on Detection and Enhancement of Speech Transmitted over HF links
Jun 16, 2021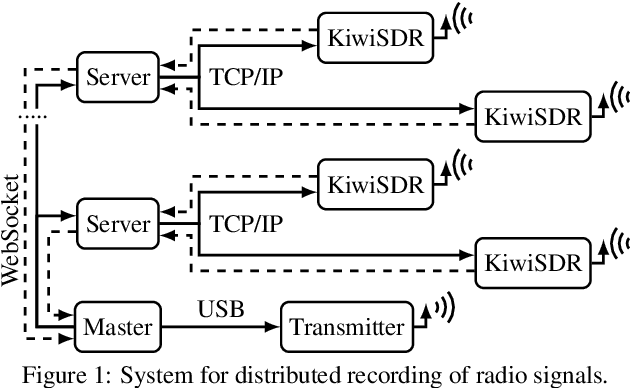
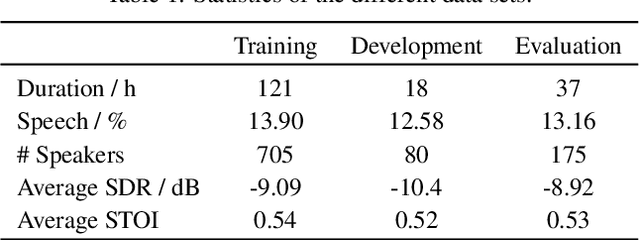

In this paper we present an open database for the development of detection and enhancement algorithms of speech transmitted over HF radio channels. It consists of audio samples recorded by various receivers at different locations across Europe, all monitoring the same single-sideband modulated transmission from a base station in Paderborn, Germany. Transmitted and received speech signals are precisely time aligned to offer parallel data for supervised training of deep learning based detection and enhancement algorithms. For the task of speech activity detection two exemplary baseline systems are presented, one based on statistical methods employing a multi-stage Wiener filter with minimum statistics noise floor estimation, and the other relying on a deep learning approach.
Open Range Pitch Tracking for Carrier Frequency Difference Estimation from HF Transmitted Speech
Mar 03, 2021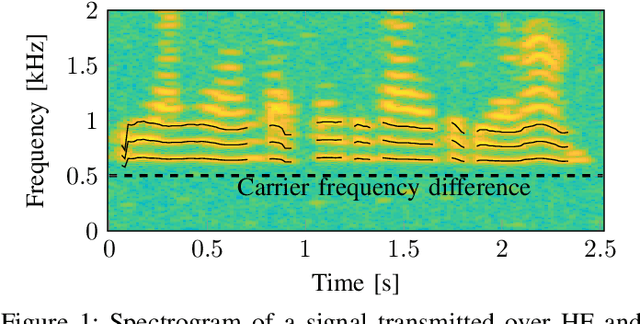
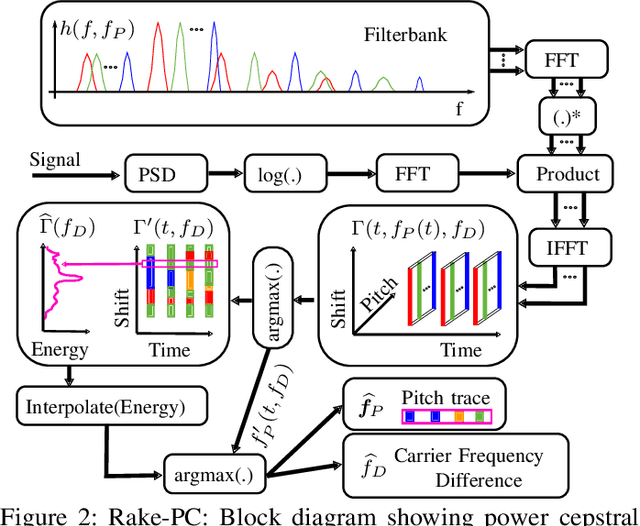
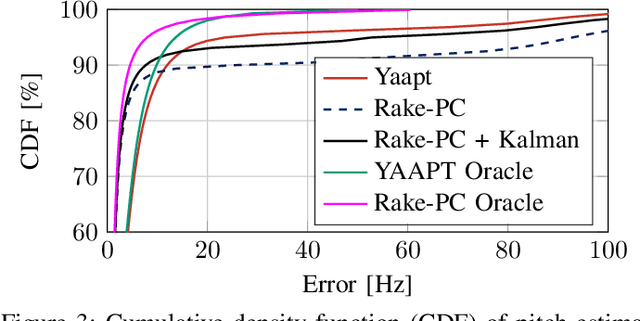
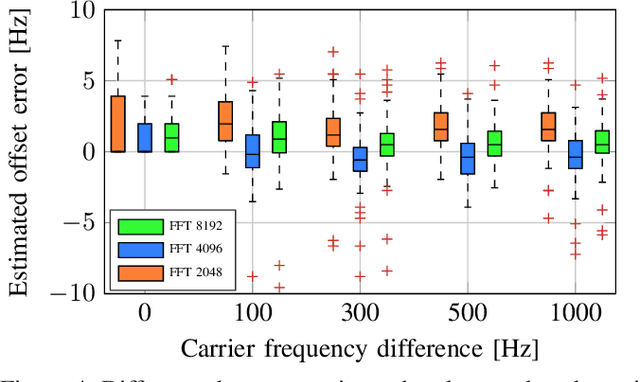
In this paper we investigate the task of detecting carrier frequency differences from demodulated single sideband signals by examining the pitch contours of the received baseband speech signal in the short-time spectral domain. From the detected pitch frequency trajectory and its harmonics a carrier frequency difference, which is caused by demodulating the radio signal with the wrong carrier frequency, can be deduced. A computationally efficient realization in the power cepstral domain is presented. The core component, i.e., the pitch tracking algorithm, is shown to perform comparably to a state of the art algorithm. The full carrier frequency difference estimation system is tested on recordings of real transmissions over HF links. A comparison with an existing approach shows improved estimation accuracy, both on short and longer speech utterances
Demystifying TasNet: A Dissecting Approach
Nov 20, 2019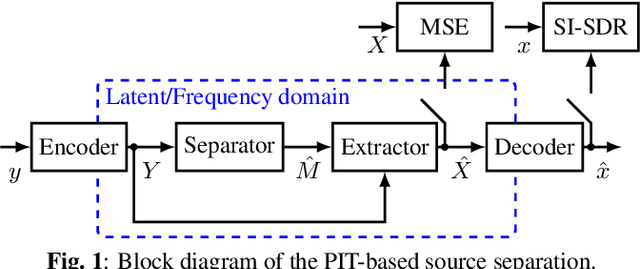

In recent years time domain speech separation has excelled over frequency domain separation in single channel scenarios and noise-free environments. In this paper we dissect the gains of the time-domain audio separation network (TasNet) approach by gradually replacing components of an utterance-level permutation invariant training (u-PIT) based separation system in the frequency domain until the TasNet system is reached, thus blending components of frequency domain approaches with those of time domain approaches. Some of the intermediate variants achieve comparable signal-to-distortion ratio (SDR) gains to TasNet, but retain the advantage of frequency domain processing: compatibility with classic signal processing tools such as frequency-domain beamforming and the human interpretability of the masks. Furthermore, we show that the scale invariant signal-to-distortion ratio (si-SDR) criterion used as loss function in TasNet is related to a logarithmic mean square error criterion and that it is this criterion which contributes most reliable to the performance advantage of TasNet. Finally, we critically assess which gains in a noise-free single channel environment generalize to more realistic reverberant conditions.
SMS-WSJ: Database, performance measures, and baseline recipe for multi-channel source separation and recognition
Oct 30, 2019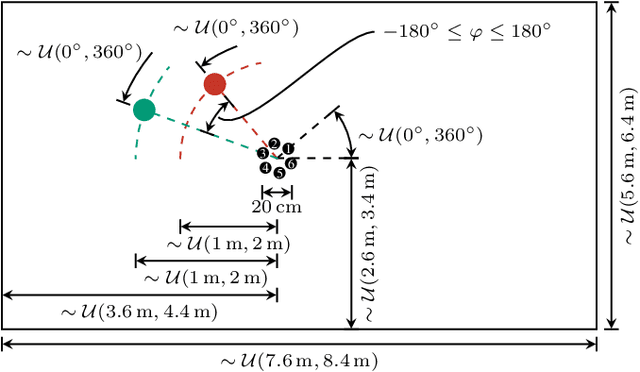
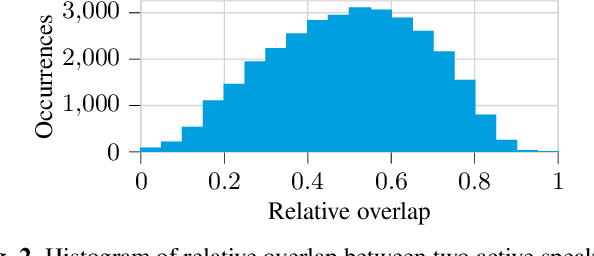

We present a multi-channel database of overlapping speech for training, evaluation, and detailed analysis of source separation and extraction algorithms: SMS-WSJ -- Spatialized Multi-Speaker Wall Street Journal. It consists of artificially mixed speech taken from the WSJ database, but unlike earlier databases we consider all WSJ0+1 utterances and take care of strictly separating the speaker sets present in the training, validation and test sets. When spatializing the data we ensure a high degree of randomness w.r.t. room size, array center and rotation, as well as speaker position. Furthermore, this paper offers a critical assessment of recently proposed measures of source separation performance. Alongside the code to generate the database we provide a source separation baseline and a Kaldi recipe with competitive word error rates to provide common ground for evaluation.
Guided Source Separation Meets a Strong ASR Backend: Hitachi/Paderborn University Joint Investigation for Dinner Party ASR
May 29, 2019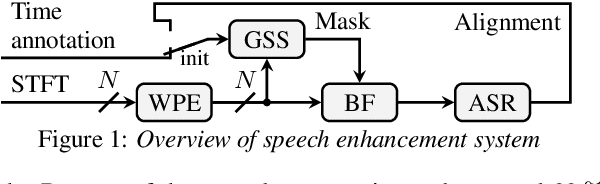
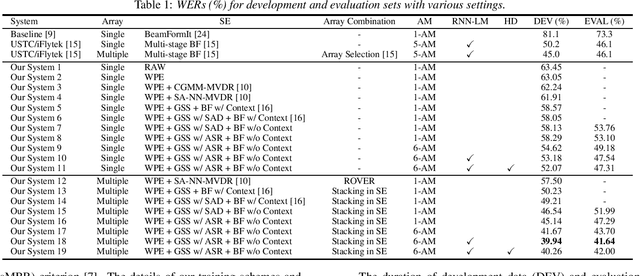
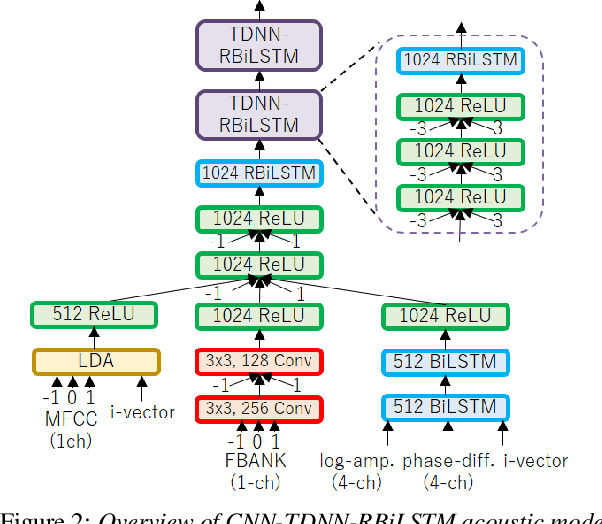
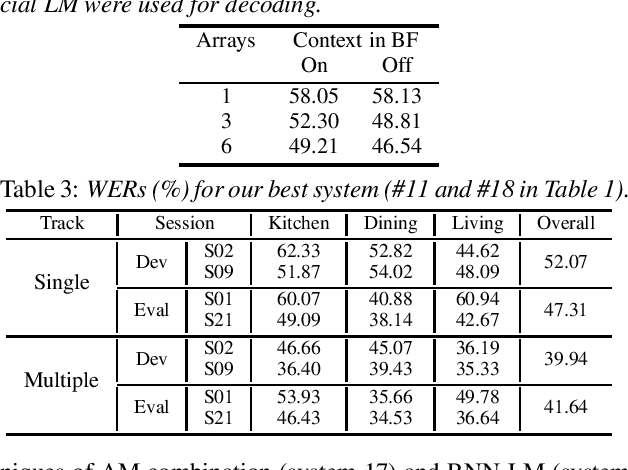
In this paper, we present Hitachi and Paderborn University's joint effort for automatic speech recognition (ASR) in a dinner party scenario. The main challenges of ASR systems for dinner party recordings obtained by multiple microphone arrays are (1) heavy speech overlaps, (2) severe noise and reverberation, (3) very natural conversational content, and possibly (4) insufficient training data. As an example of a dinner party scenario, we have chosen the data presented during the CHiME-5 speech recognition challenge, where the baseline ASR had a 73.3% word error rate (WER), and even the best performing system at the CHiME-5 challenge had a 46.1% WER. We extensively investigated a combination of the guided source separation-based speech enhancement technique and an already proposed strong ASR backend and found that a tight combination of these techniques provided substantial accuracy improvements. Our final system achieved WERs of 39.94% and 41.64% for the development and evaluation data, respectively, both of which are the best published results for the dataset. We also investigated with additional training data on the official small data in the CHiME-5 corpus to assess the intrinsic difficulty of this ASR task.