 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying TasNet: A Dissecting Approach
Paper and Code
Nov 20, 2019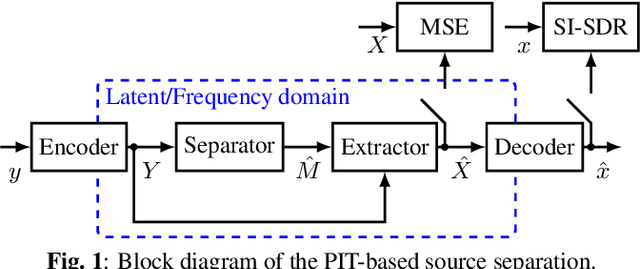

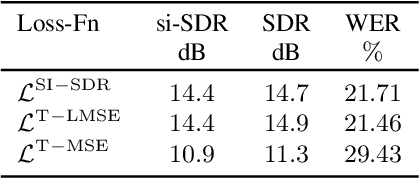
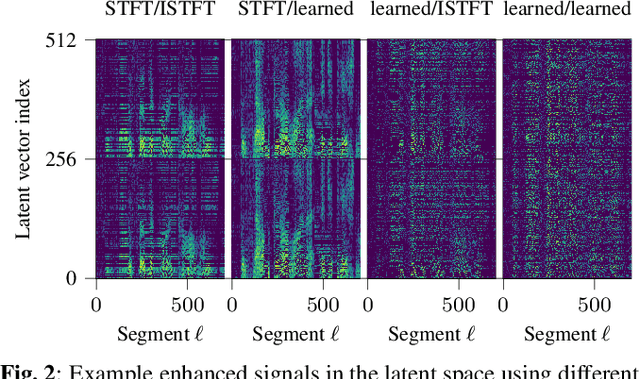
In recent years time domain speech separation has excelled over frequency domain separation in single channel scenarios and noise-free environments. In this paper we dissect the gains of the time-domain audio separation network (TasNet) approach by gradually replacing components of an utterance-level permutation invariant training (u-PIT) based separation system in the frequency domain until the TasNet system is reached, thus blending components of frequency domain approaches with those of time domain approaches. Some of the intermediate variants achieve comparable signal-to-distortion ratio (SDR) gains to TasNet, but retain the advantage of frequency domain processing: compatibility with classic signal processing tools such as frequency-domain beamforming and the human interpretability of the masks. Furthermore, we show that the scale invariant signal-to-distortion ratio (si-SDR) criterion used as loss function in TasNet is related to a logarithmic mean square error criterion and that it is this criterion which contributes most reliable to the performance advantage of TasNet. Finally, we critically assess which gains in a noise-free single channel environment generalize to more realistic reverberant conditions.