 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMS-WSJ: Database, performance measures, and baseline recipe for multi-channel source separation and recognition
Paper and Code
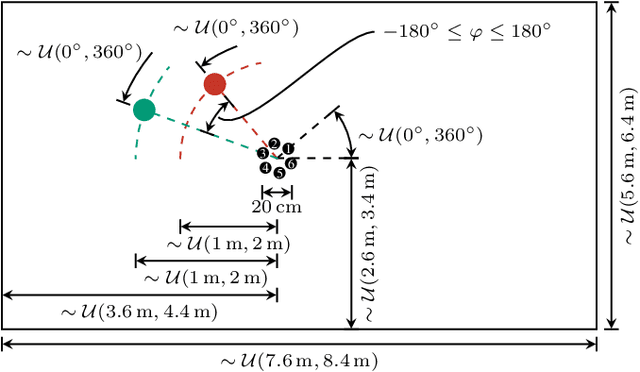
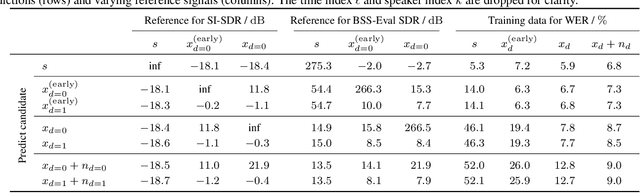
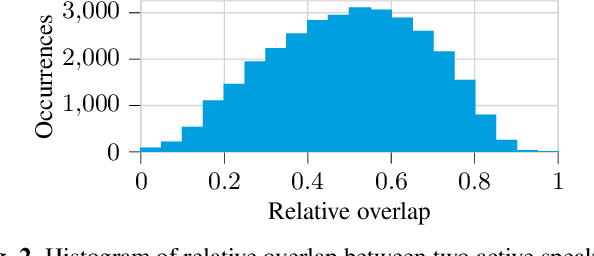

We present a multi-channel database of overlapping speech for training, evaluation, and detailed analysis of source separation and extraction algorithms: SMS-WSJ -- Spatialized Multi-Speaker Wall Street Journal. It consists of artificially mixed speech taken from the WSJ database, but unlike earlier databases we consider all WSJ0+1 utterances and take care of strictly separating the speaker sets present in the training, validation and test sets. When spatializing the data we ensure a high degree of randomness w.r.t. room size, array center and rotation, as well as speaker position. Furthermore, this paper offers a critical assessment of recently proposed measures of source separation performance. Alongside the code to generate the database we provide a source separation baseline and a Kaldi recipe with competitive word error rates to provide common ground for evaluation.