 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a Foundation of Vector Symbolic Architectures Using Category Theory
Jan 09, 2025

At the risk of overstating the case, connectionist approaches to machine learning, i.e. neural networks, are enjoying a small vogue right now. However, these methods require large volumes of data and produce models that are uninterpretable to humans. An alternative framework that is compatible with neural networks and gradient-based learning, but explicitly models compositionality, is Vector Symbolic Architectures (VSAs). VSAs are a family of algebras on high-dimensional vector representations. They arose in cognitive science from the need to unify neural processing and the kind of symbolic reasoning that humans perform. While machine learning methods have benefited from category theoretical analyses, VSAs have not yet received similar treatment. In this paper, we present a first attempt at applying category theory to VSAs. Specifically, we conduct a brief literature survey demonstrating the lacking intersection of these two topics, provide a list of desiderata for VSAs, and propose that VSAs may be understood as a (division) rig in a category enriched over a monoid in Met (the category of Lawvere metric spaces). This final contribution suggests that VSAs may be generalised beyond current implementations. It is our hope that grounding VSAs in category theory will lead to more rigorous connections with other research, both within and beyond, learning and cognition.
Improved Cleanup and Decoding of Fractional Power Encodings
Nov 30, 2024



High-dimensional vectors have been proposed as a neural method for representing information in the brain using Vector Symbolic Algebras (VSAs). While previous work has explored decoding and cleaning up these vectors under the noise that arises during computation, existing methods are limited. Cleanup methods are essential for robust computation within a VSA. However, cleanup methods for continuous-value encodings are not as effective. In this paper, we present an iterative optimization method to decode and clean up Fourier Holographic Reduced Representation (FHRR) vectors that are encoding continuous values. We combine composite likelihood estimation (CLE) and maximum likelihood estimation (MLE) to ensure convergence to the global optimum. We also demonstrate that this method can effectively decode FHRR vectors under different noise conditions, and show that it outperforms existing methods.
Protecting Feed-Forward Networks from Adversarial Attacks Using Predictive Coding
Oct 31, 2024



An adversarial example is a modified input image designed to cause a Machine Learning (ML) model to make a mistake; these perturbations are often invisible or subtle to human observers and highlight vulnerabilities in a model's ability to generalize from its training data. Several adversarial attacks can create such examples, each with a different perspective, effectiveness, and perceptibility of changes. Conversely, defending against such adversarial attacks improves the robustness of ML models in image processing and other domains of deep learning. Most defence mechanisms require either a level of model awareness, changes to the model, or access to a comprehensive set of adversarial examples during training, which is impractical. Another option is to use an auxiliary model in a preprocessing manner without changing the primary model. This study presents a practical and effective solution -- using predictive coding networks (PCnets) as an auxiliary step for adversarial defence. By seamlessly integrating PCnets into feed-forward networks as a preprocessing step, we substantially bolster resilience to adversarial perturbations. Our experiments on MNIST and CIFAR10 demonstrate the remarkable effectiveness of PCnets in mitigating adversarial examples with about 82% and 65% improvements in robustness, respectively. The PCnet, trained on a small subset of the dataset, leverages its generative nature to effectively counter adversarial efforts, reverting perturbed images closer to their original forms. This innovative approach holds promise for enhancing the security and reliability of neural network classifiers in the face of the escalating threat of adversarial attacks.
Online Training of Hopfield Networks using Predictive Coding
Jun 20, 2024



Neuroscience and Artificial Intelligence (AI) have progressed in tandem, each contributing to our understanding of the brain, and inspiring recent developments in biologically-plausible neural networks (NNs) and learning rules. Predictive coding (PC), and its learning rule, have been shown to approximate error backpropagation in a biologically relevant manner, with local weight updates that depend only on the activity of the pre- and post-synaptic neurons. Unlike traditional feedforward NNs where the flow of information goes in one direction, PC models mimic the brain more accurately by passing information bidirectionally: prediction in one direction, and correction/error in the other. PC models learn by clamping some neurons to target values and running the network to equilibrium. At equilibrium, the network calculates its own error gradients right at the location where they are used for weight updates. Traditional backprop requires the computation graph to be feedforward. However, the PC version of backprop does not have this requirement. Amazingly, no one has demonstrated the application of PC learning directly to recurrent neural networks (RNNs). Hopfield networks (HNs) are RNNs that implement a content-addressable memory, learning patterns (or ``memories'') that can be retrieved from partial or corrupted patterns. In this paper, we show that a HN can be trained using the PC learning rules without modification. To our knowledge, this is the first time PC learning has been applied directly to train a RNN, without the need to unroll it in time. Our results indicate that the PC-trained HNs behave like classical HNs.
Hyperdimensional Computing with Spiking-Phasor Neurons
Feb 28, 2023



Vector Symbolic Architectures (VSAs) are a powerful framework for representing compositional reasoning. They lend themselves to neural-network implementations, allowing us to create neural networks that can perform cognitive functions, like spatial reasoning, arithmetic, symbol binding, and logic. But the vectors involved can be quite large, hence the alternative label Hyperdimensional (HD) computing. Advances in neuromorphic hardware hold the promise of reducing the running time and energy footprint of neural networks by orders of magnitude. In this paper, we extend some pioneering work to run VSA algorithms on a substrate of spiking neurons that could be run efficiently on neuromorphic hardware.
Deconvolutional Density Network: Free-Form Conditional Density Estimation
May 29, 2021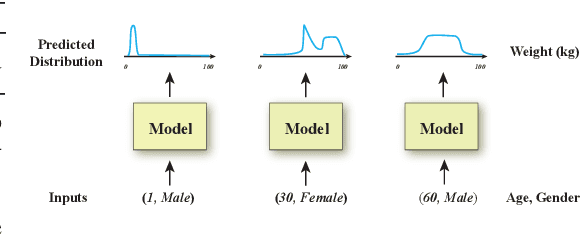
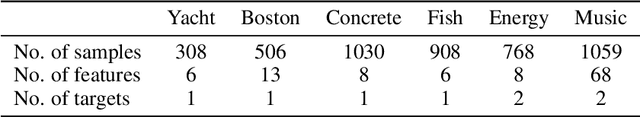
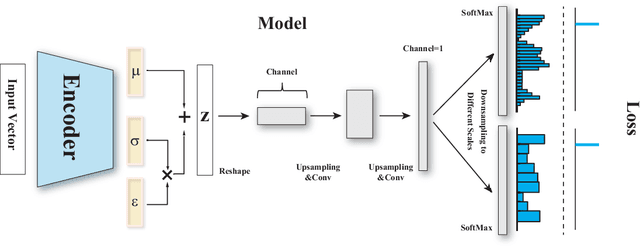
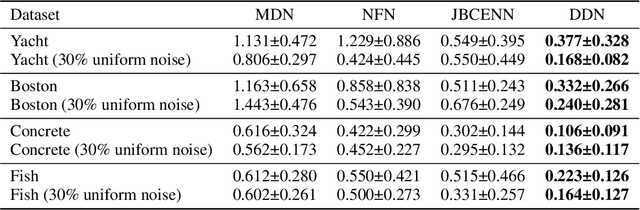
Conditional density estimation is the task of estimating the probability of an event, conditioned on some inputs. A neural network can be used to compute the output distribution explicitly. For such a task, there are many ways to represent a continuous-domain distribution using the output of a neural network, but each comes with its own limitations for what distributions it can accurately render. If the family of functions is too restrictive, it will not be appropriate for many datasets. In this paper, we demonstrate the benefits of modeling free-form distributions using deconvolution. It has the advantage of being flexible, but also takes advantage of the topological smoothness offered by the deconvolution layers. We compare our method to a number of other density-estimation approaches, and show that our Deconvolutional Density Network (DDN) outperforms the competing methods on many artificial and real tasks, without committing to a restrictive parametric model.
Making Predictive Coding Networks Generative
Oct 26, 2019


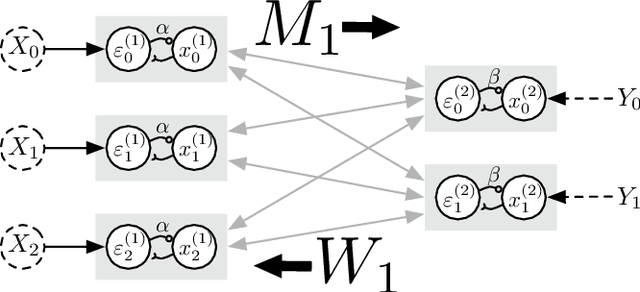
Predictive coding (PC) networks are a biologically interesting class of neural networks. Their layered hierarchy mimics the reciprocal connectivity pattern observed in the mammalian cortex, and they can be trained using local learning rules that approximate backpropagation [Bogacz, 2017]. However, despite having feedback connections that enable information to flow down the network hierarchy, discriminative PC networks are not generative. Clamping the output class and running the network to equilibrium yields an input sample that typically does not resemble the training input. This paper studies this phenomenon, and proposes a simple solution that promotes the generation of input samples that resemble the training inputs. Simple decay, a technique already in wide use in neural networks, pushes the PC network toward a unique minimum 2-norm solution, and that unique solution provably (for linear networks) matches the training inputs. The method also vastly improves the samples generated for nonlinear networks, as we demonstrate on MNIST.
A Novel Continuous Representation of Genetic Programmings using Recurrent Neural Networks for Symbolic Regression
Apr 06, 2019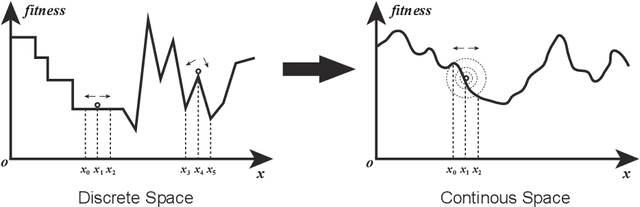
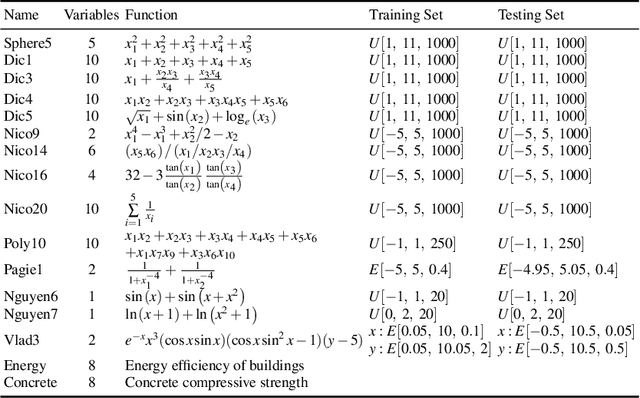
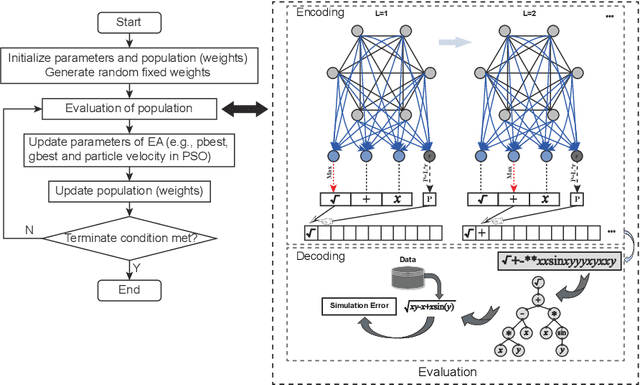
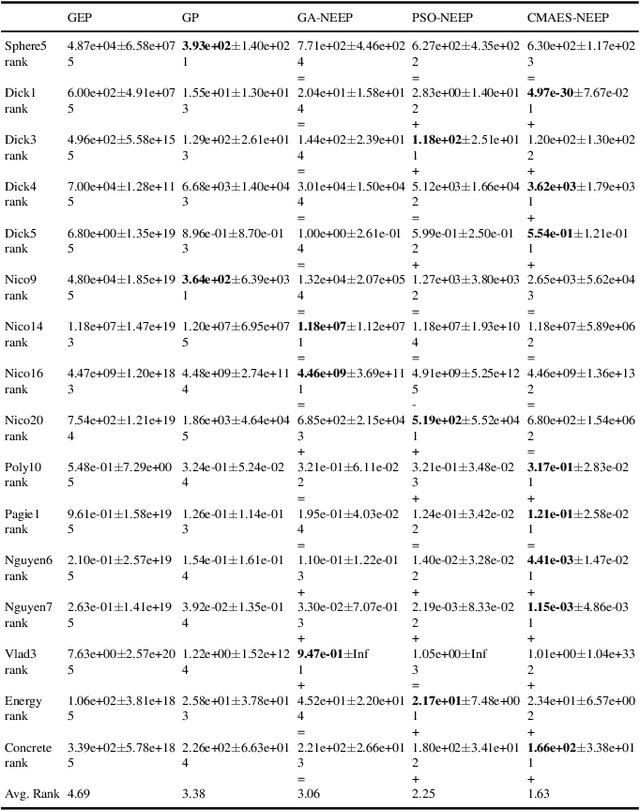
Neuro-encoded expression programming that aims to offer a novel continuous representation of combinatorial encoding for genetic programming methods is proposed in this paper. Genetic programming with linear representation uses nature-inspired operators to tune expressions and finally search out the best explicit function to simulate data. The encoding mechanism is essential for genetic programmings to find a desirable solution efficiently. However, the linear representation methods manipulate the expression tree in discrete solution space, where a small change of the input can cause a large change of the output. The unsmooth landscapes destroy the local information and make difficulty in searching. The neuro-encoded expression programming constructs the gene string with recurrent neural network (RNN) and the weights of the network are optimized by powerful continuous evolutionary algorithms. The neural network mappings smoothen the sharp fitness landscape and provide rich neighborhood information to find the best expression. The experiments indicate that the novel approach improves test accuracy and efficiency on several well-known symbolic regression problems.
Style Memory: Making a Classifier Network Generative
Mar 05, 2018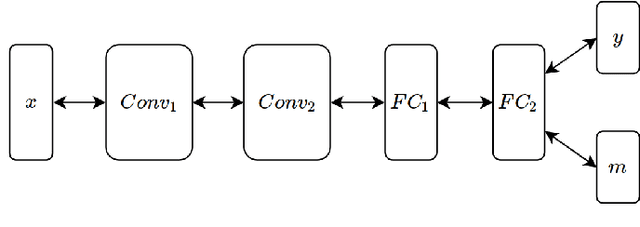



Deep networks have shown great performance in classification tasks. However, the parameters learned by the classifier networks usually discard stylistic information of the input, in favour of information strictly relevant to classification. We introduce a network that has the capacity to do both classification and reconstruction by adding a "style memory" to the output layer of the network. We also show how to train such a neural network as a deep multi-layer autoencoder, jointly minimizing both classification and reconstruction losses. The generative capacity of our network demonstrates that the combination of style-memory neurons with the classifier neurons yield good reconstructions of the inputs when the classification is correct. We further investigate the nature of the style memory, and how it relates to composing digits and letters. Finally, we propose that this architecture enables the bidirectional flow of information used in predictive coding, and that such bidirectional networks can help mitigate against being fooled by ambiguous or adversarial input.
PixelBNN: Augmenting the PixelCNN with batch normalization and the presentation of a fast architecture for retinal vessel segmentation
Dec 19, 2017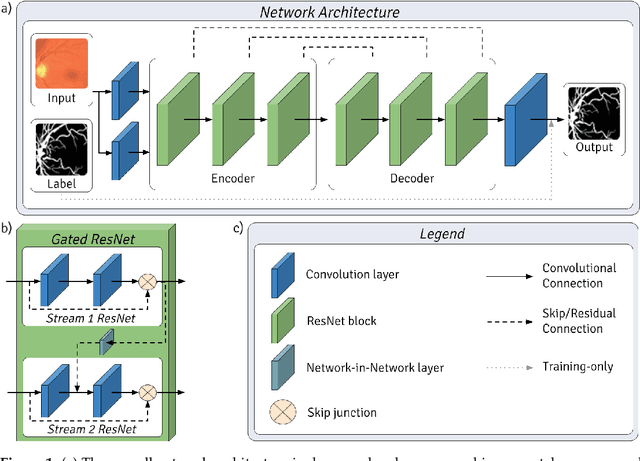
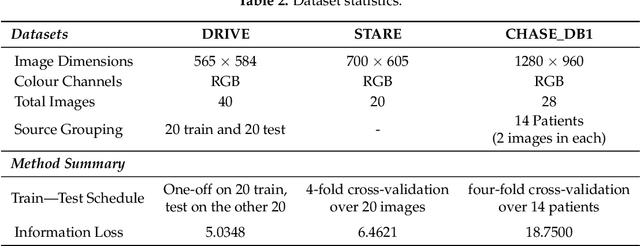
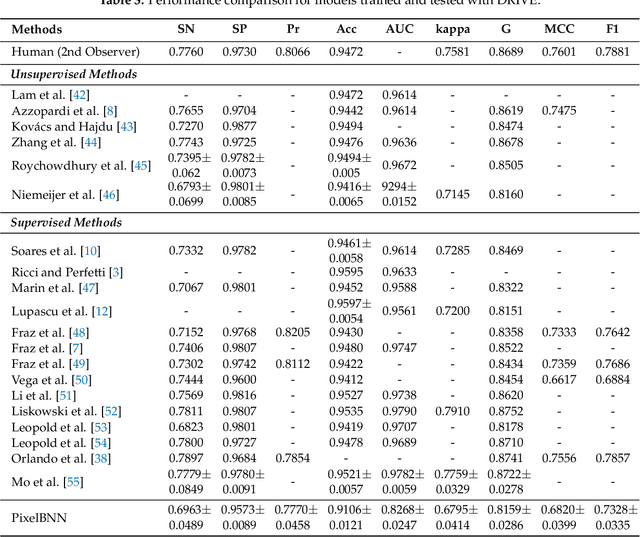
Analysis of retinal fundus images is essential for eye-care physicians in the diagnosis, care and treatment of patients. Accurate fundus and/or retinal vessel maps give rise to longitudinal studies able to utilize multimedia image registration and disease/condition status measurements, as well as applications in surgery preparation and biometrics. The segmentation of retinal morphology has numerous applications in assessing ophthalmologic and cardiovascular disease pathologies. The early detection of many such conditions is often the most effective method for reducing patient risk. Computer aided segmentation of the vasculature has proven to be a challenge, mainly due to inconsistencies such as noise and variations in hue and brightness that can greatly reduce the quality of fundus images. This paper presents PixelBNN, a highly efficient deep method for automating the segmentation of fundus morphologies. The model was trained, tested and cross tested on the DRIVE, STARE and CHASE\_DB1 retinal vessel segmentation datasets. Performance was evaluated using G-mean, Mathews Correlation Coefficient and F1-score. The network was 8.5 times faster than the current state-of-the-art at test time and performed comparatively well, considering a 5 to 19 times reduction in information from resizing images during preprocessing.