 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Predictive Coding Networks Generative
Paper and Code
Oct 26, 2019


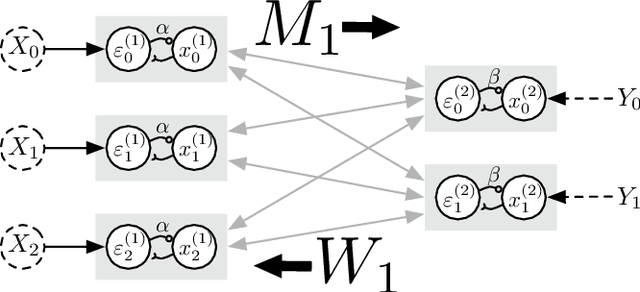
Predictive coding (PC) networks are a biologically interesting class of neural networks. Their layered hierarchy mimics the reciprocal connectivity pattern observed in the mammalian cortex, and they can be trained using local learning rules that approximate backpropagation [Bogacz, 2017]. However, despite having feedback connections that enable information to flow down the network hierarchy, discriminative PC networks are not generative. Clamping the output class and running the network to equilibrium yields an input sample that typically does not resemble the training input. This paper studies this phenomenon, and proposes a simple solution that promotes the generation of input samples that resemble the training inputs. Simple decay, a technique already in wide use in neural networks, pushes the PC network toward a unique minimum 2-norm solution, and that unique solution provably (for linear networks) matches the training inputs. The method also vastly improves the samples generated for nonlinear networks, as we demonstrate on MNIST.