 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Are deep learning models superior for missing data imputation in large surveys? Evidence from an empirical comparison
Mar 14, 2021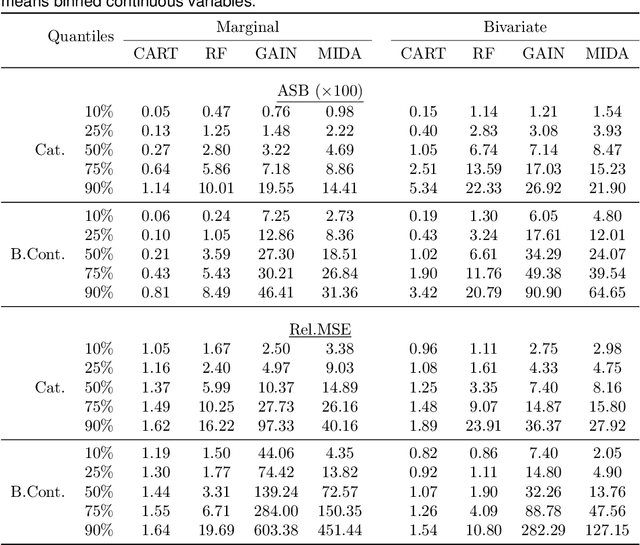
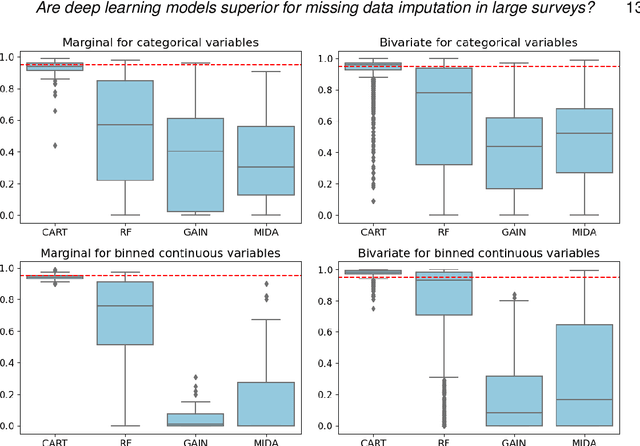

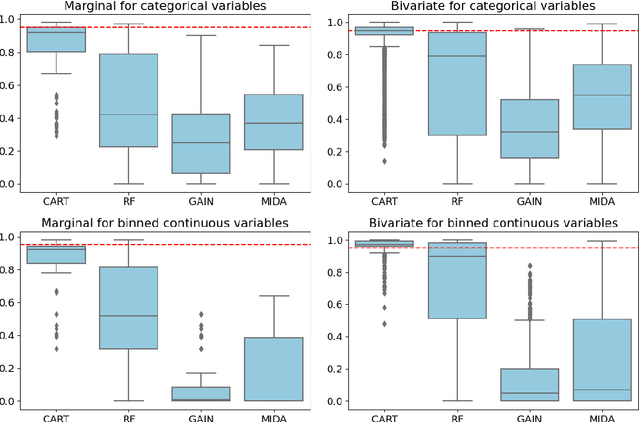
Multiple imputation (MI) is the state-of-the-art approach for dealing with missing data arising from non-response in sample surveys. Multiple imputation by chained equations (MICE) is the most widely used MI method, but it lacks theoretical foundation and is computationally intensive. Recently, MI methods based on deep learning models have been developed with encouraging results in small studies. However, there has been limited research on systematically evaluating their performance in realistic settings comparing to MICE, particularly in large-scale surveys. This paper provides a general framework for using simulations based on real survey data and several performance metrics to compare MI methods. We conduct extensive simulation studies based on the American Community Survey data to compare repeated sampling properties of four machine learning based MI methods: MICE with classification trees, MICE with random forests, generative adversarial imputation network, and multiple imputation using denoising autoencoders. We find the deep learning based MI methods dominate MICE in terms of computational time; however, MICE with classification trees consistently outperforms the deep learning MI methods in terms of bias, mean squared error, and coverage under a range of realistic settings.
Adversarial Machine Learning: Perspectives from Adversarial Risk Analysis
Mar 07, 2020



Adversarial Machine Learning (AML) is emerging as a major field aimed at the protection of automated ML systems against security threats. The majority of work in this area has built upon a game-theoretic framework by modelling a conflict between an attacker and a defender. After reviewing game-theoretic approaches to AML, we discuss the benefits that a Bayesian Adversarial Risk Analysis perspective brings when defending ML based systems. A research agenda is included.
Missing Data Imputation for Supervised Learning
Aug 07, 2018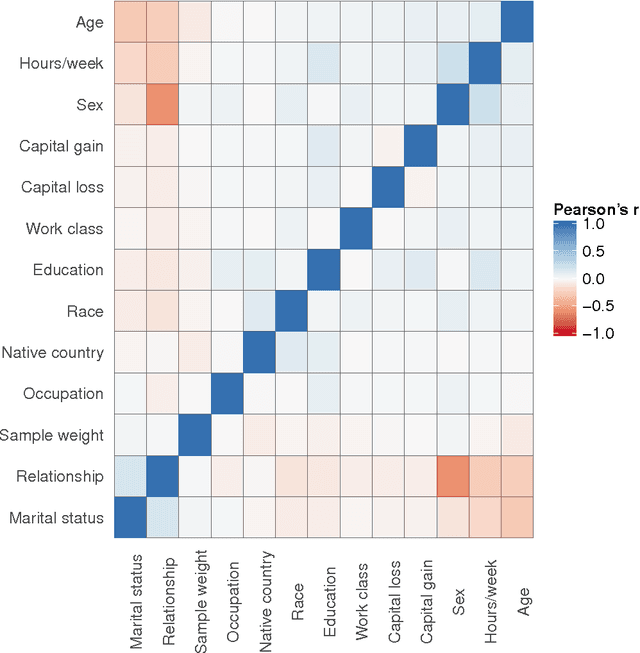

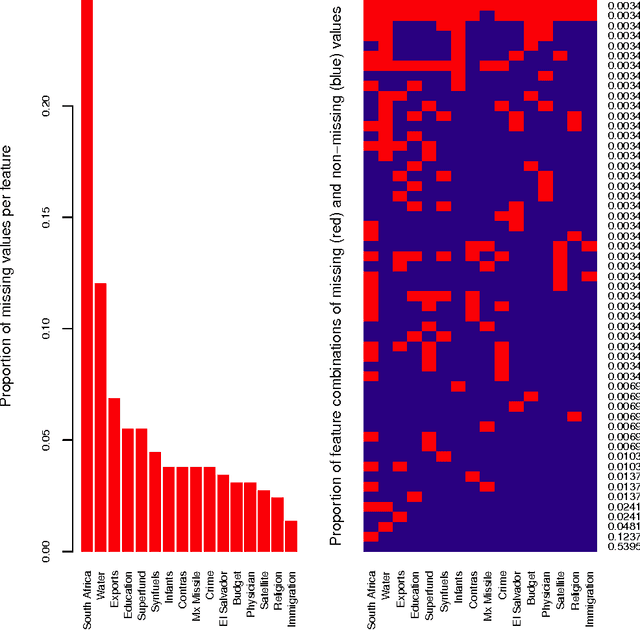
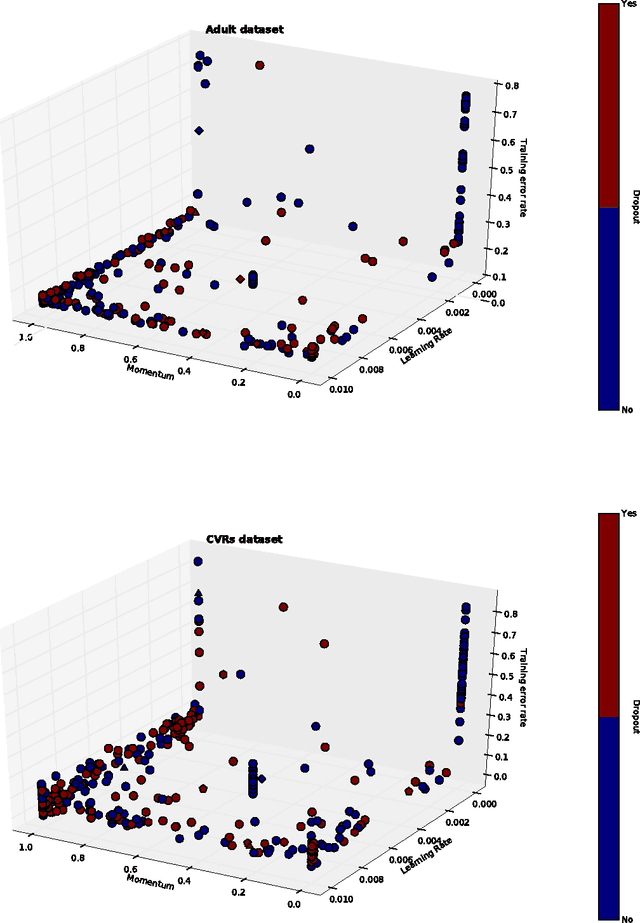
Missing data imputation can help improve the performance of prediction models in situations where missing data hide useful information. This paper compares methods for imputing missing categorical data for supervised classification tasks. We experiment on two machine learning benchmark datasets with missing categorical data, comparing classifiers trained on non-imputed (i.e., one-hot encoded) or imputed data with different levels of additional missing-data perturbation. We show imputation methods can increase predictive accuracy in the presence of missing-data perturbation, which can actually improve prediction accuracy by regularizing the classifier. We achieve the state-of-the-art on the Adult dataset with missing-data perturbation and k-nearest-neighbors (k-NN) imputation.
RNN-based counterfactual time-series prediction
May 11, 2018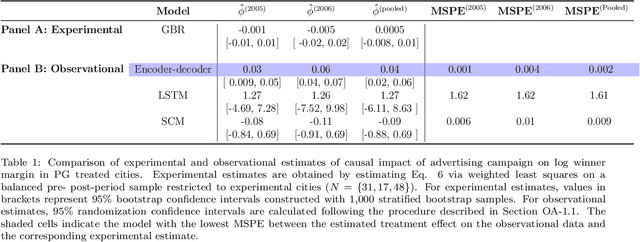
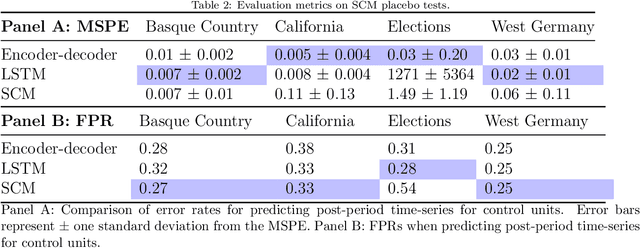
This paper proposes an alternative to the synthetic control method (SCM) for estimating the effect of a policy intervention on an outcome over time. Recurrent neural networks (RNNs) are used to predict counterfactual time-series of treated unit outcomes using only the outcomes of control units as inputs. Unlike SCM, the proposed method does not rely on pre-intervention covariates, allows for nonconvex combinations of control units, can handle multiple treated units, and can share model parameters across time-steps. RNNs outperform SCM in terms of recovering experimental estimates from a field experiment extended to a time-series observational setting. In placebo tests run on three different benchmark datasets, RNNs are more accurate than SCM in predicting the post-intervention time-series of control units, while yielding a comparable proportion of false positives. The proposed method contributes to a new literature that uses machine learning techniques for data-driven counterfactual prediction.
Attention networks for image-to-text
Dec 11, 2017
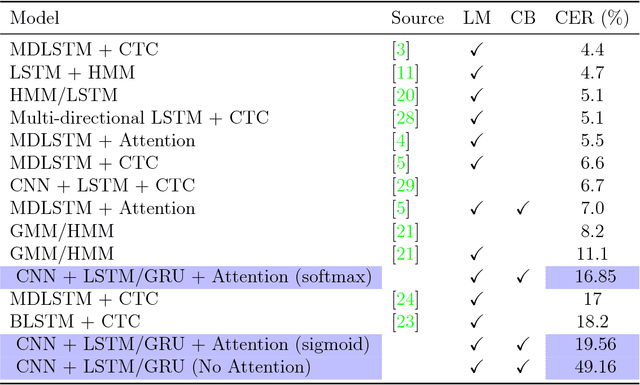
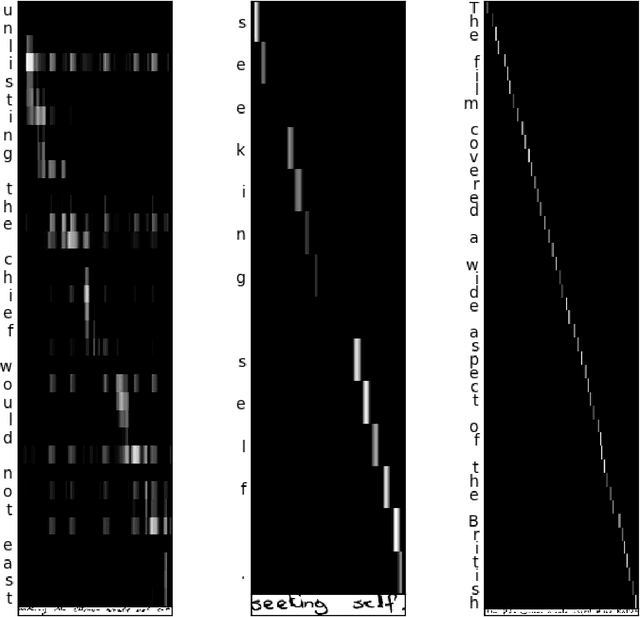

The paper approaches the problem of image-to-text with attention-based encoder-decoder networks that are trained to handle sequences of characters rather than words. We experiment on lines of text from a popular handwriting database with different attention mechanisms for the decoder. The model trained with softmax attention achieves the lowest test error, outperforming several other RNN-based models. Our results show that softmax attention is able to learn a linear alignment whereas the alignment generated by sigmoid attention is linear but much less precise.