 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Improves Self-Critique Against Jailbreak Attacks
Jun 11, 2024



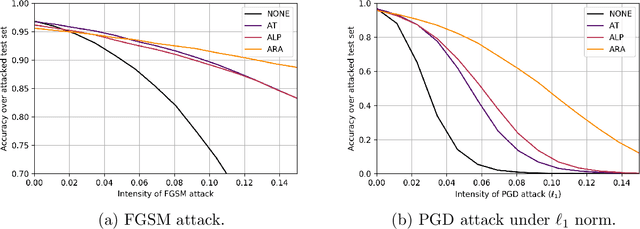
The robustness of large language models (LLMs) against adversarial manipulations, such as jailbreak attacks, remains a significant challenge. In this work, we propose an approach that enhances the self-critique capability of the LLM and further fine-tunes it over sanitized synthetic data. This is done with the addition of an external critic model that can be merged with the original, thus bolstering self-critique capabilities and improving the robustness of the LLMs response to adversarial prompts. Our results demonstrate that the combination of merging and self-critique can reduce the attack success rate of adversaries significantly, thus offering a promising defense mechanism against jailbreak attacks. Code, data and models released at https://github.com/vicgalle/merging-self-critique-jailbreaks .
Configurable Safety Tuning of Language Models with Synthetic Preference Data
Mar 30, 2024State-of-the-art language model fine-tuning techniques, such as Direct Preference Optimization (DPO), restrict user control by hard-coding predefined behaviors into the model. To address this, we propose a novel method, Configurable Safety Tuning (CST), that augments DPO using synthetic preference data to facilitate flexible safety configuration of LLMs at inference time. CST overcomes the constraints of vanilla DPO by introducing a system prompt specifying safety configurations, enabling LLM deployers to disable/enable safety preferences based on their need, just changing the system prompt. Our experimental evaluations indicate that CST successfully manages different safety configurations and retains the original functionality of LLMs, showing it is a robust method for configurable deployment. Data and models available at https://github.com/vicgalle/configurable-safety-tuning
Distilled Self-Critique of LLMs with Synthetic Data: a Bayesian Perspective
Dec 04, 2023This paper proposes an interpretation of RLAIF as Bayesian inference by introducing distilled Self-Critique (dSC), which refines the outputs of a LLM through a Gibbs sampler that is later distilled into a fine-tuned model. Only requiring synthetic data, dSC is exercised in experiments regarding safety, sentiment, and privacy control, showing it can be a viable and cheap alternative to align LLMs. Code released at \url{https://github.com/vicgalle/distilled-self-critique}.
ZYN: Zero-Shot Reward Models with Yes-No Questions
Aug 11, 2023
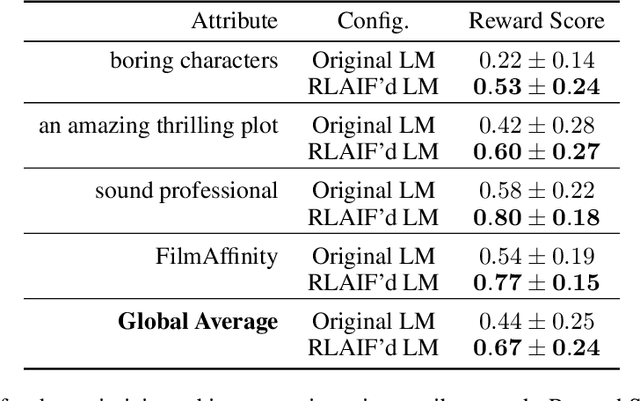

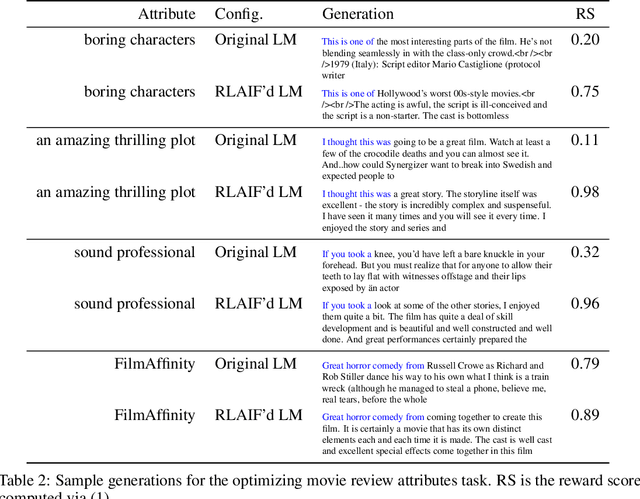
In this work, we address the problem of directing the text generations of a LLM towards a desired behavior, aligning the generated text with the preferences of the human operator. We propose using another language model as a critic, reward model in a zero-shot way thanks to the prompt of a Yes-No question that represents the user preferences, without requiring further labeled data. This zero-shot reward model provides the learning signal to further fine-tune the base LLM using reinforcement learning, as in RLAIF; yet our approach is also compatible in other contexts such as quality-diversity search. Extensive evidence of the capabilities of the proposed ZYN framework is provided through experiments in different domains related to text generation, including detoxification; optimizing sentiment of movie reviews, or any other attribute; steering the opinion about a particular topic the model may have; and personalizing prompt generators for text-to-image tasks. Code to be released at \url{https://github.com/vicgalle/zero-shot-reward-models/}.
Personalizing Text-to-Image Generation via Aesthetic Gradients
Sep 25, 2022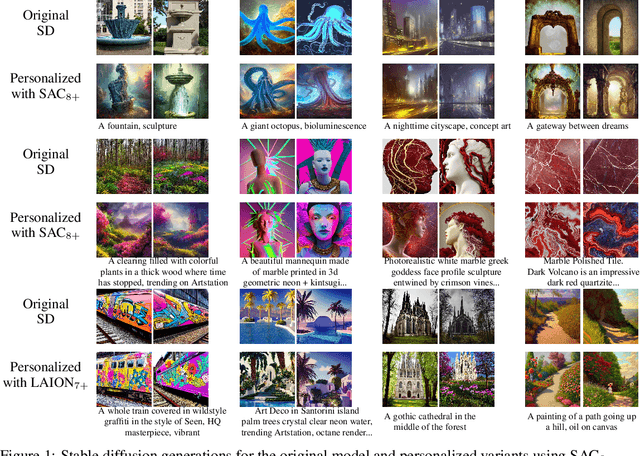


This work proposes aesthetic gradients, a method to personalize a CLIP-conditioned diffusion model by guiding the generative process towards custom aesthetics defined by the user from a set of images. The approach is validated with qualitative and quantitative experiments, using the recent stable diffusion model and several aesthetically-filtered datasets. Code is released at https://github.com/vicgalle/stable-diffusion-aesthetic-gradients
Protecting Classifiers From Attacks. A Bayesian Approach
Apr 18, 2020
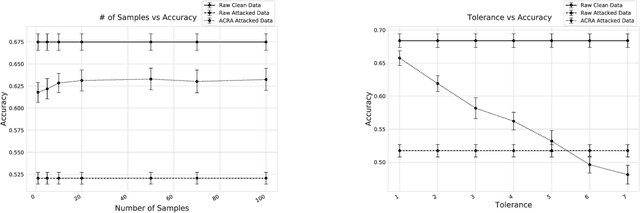

Classification problems in security settings are usually modeled as confrontations in which an adversary tries to fool a classifier manipulating the covariates of instances to obtain a benefit. Most approaches to such problems have focused on game-theoretic ideas with strong underlying common knowledge assumptions, which are not realistic in the security realm. We provide an alternative Bayesian framework that accounts for the lack of precise knowledge about the attacker's behavior using adversarial risk analysis. A key ingredient required by our framework is the ability to sample from the distribution of originating instances given the possibly attacked observed one. We propose a sampling procedure based on approximate Bayesian computation, in which we simulate the attacker's problem taking into account our uncertainty about his elements. For large scale problems, we propose an alternative, scalable approach that could be used when dealing with differentiable classifiers. Within it, we move the computational load to the training phase, simulating attacks from an adversary, adapting the framework to obtain a classifier robustified against attacks.
Adversarial Machine Learning: Perspectives from Adversarial Risk Analysis
Mar 07, 2020



Adversarial Machine Learning (AML) is emerging as a major field aimed at the protection of automated ML systems against security threats. The majority of work in this area has built upon a game-theoretic framework by modelling a conflict between an attacker and a defender. After reviewing game-theoretic approaches to AML, we discuss the benefits that a Bayesian Adversarial Risk Analysis perspective brings when defending ML based systems. A research agenda is included.
Variationally Inferred Sampling Through a Refined Bound for Probabilistic Programs
Sep 23, 2019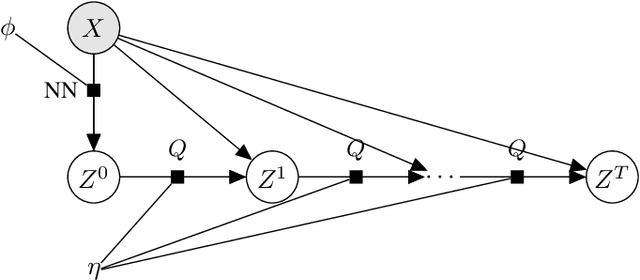
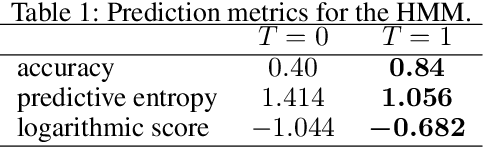
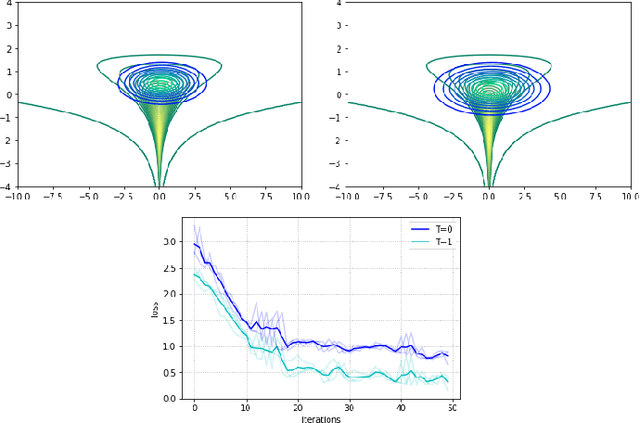
A framework to boost efficiency of Bayesian inference in probabilistic programs is introduced by embedding a sampler inside a variational posterior approximation, which we call the refined variational approximation. Its strength lies both in ease of implementation and in automatically tuning the sampler parameters to speed up mixing time. Several strategies to approximate the \emph{evidence lower bound} (ELBO) computation are introduced, including a rewriting of the ELBO objective. A specialization towards state-space models is proposed. Experimental evidence of its efficient performance is shown by solving an influence diagram in a high-dimensional space using a conditional variational autoencoder (cVAE) as a deep Bayes classifier; an unconditional VAE on density estimation tasks; and state-space models for time-series data.
Opponent Aware Reinforcement Learning
Aug 26, 2019
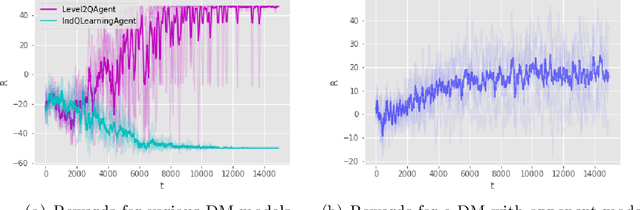
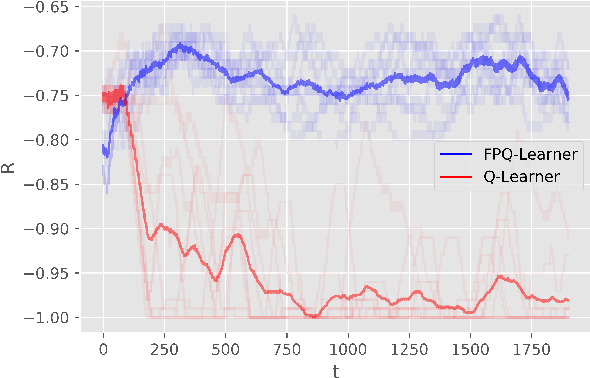
We introduce Threatened Markov Decision Processes (TMDPs) as an extension of the classical Markov Decision Process framework for Reinforcement Learning (RL). TMDPs allow suporting a decision maker against potential opponents in a RL context. We also propose a level-k thinking scheme resulting in a novel learning approach to deal with TMDPs. After introducing our framework and deriving theoretical results, relevant empirical evidence is given via extensive experiments, showing the benefits of accounting for adversaries in RL while the agent learns
Stochastic Gradient MCMC with Repulsive Forces
Nov 30, 2018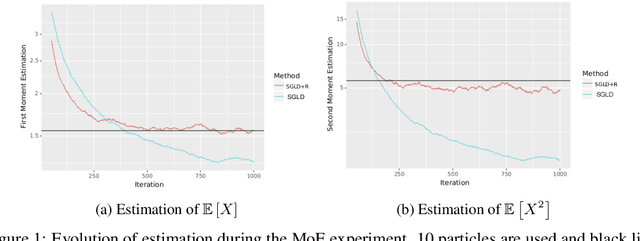
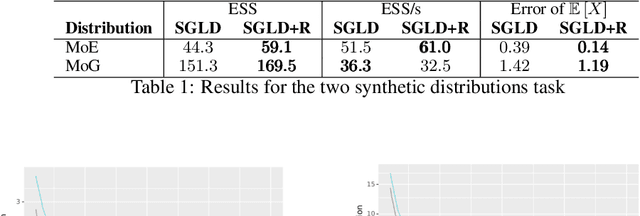

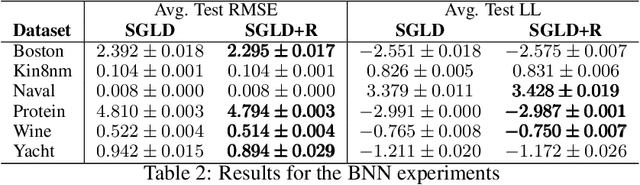
We propose a unifying view of two different families of Bayesian inference algorithms, SG-MCMC and SVGD. We show that SVGD plus a noise term can be framed as a multiple chain SG-MCMC method. Instead of treating each parallel chain independently from others, the proposed algorithm implements a repulsive force between particles, avoiding collapse. Experiments in both synthetic distributions and real datasets show the benefits of the proposed scheme.