 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZYN: Zero-Shot Reward Models with Yes-No Questions
Paper and Code

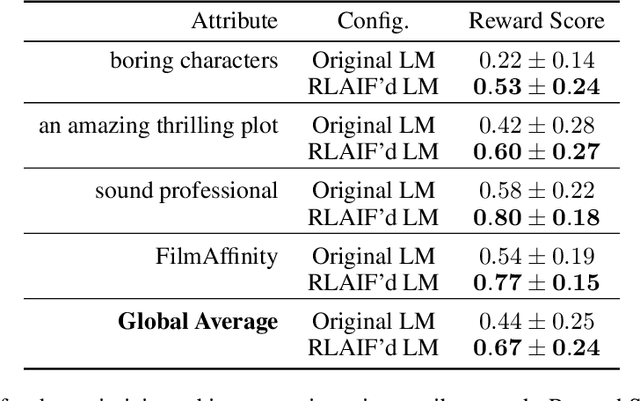

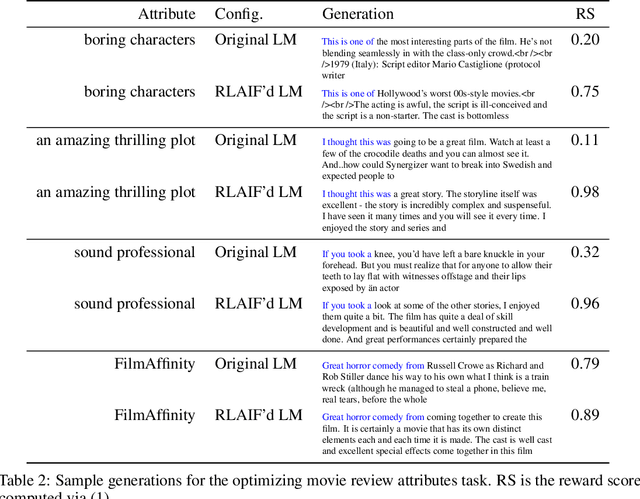
In this work, we address the problem of directing the text generations of a LLM towards a desired behavior, aligning the generated text with the preferences of the human operator. We propose using another language model as a critic, reward model in a zero-shot way thanks to the prompt of a Yes-No question that represents the user preferences, without requiring further labeled data. This zero-shot reward model provides the learning signal to further fine-tune the base LLM using reinforcement learning, as in RLAIF; yet our approach is also compatible in other contexts such as quality-diversity search. Extensive evidence of the capabilities of the proposed ZYN framework is provided through experiments in different domains related to text generation, including detoxification; optimizing sentiment of movie reviews, or any other attribute; steering the opinion about a particular topic the model may have; and personalizing prompt generators for text-to-image tasks. Code to be released at \url{https://github.com/vicgalle/zero-shot-reward-models/}.