Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpponent Aware Reinforcement Learning
Aug 26, 2019
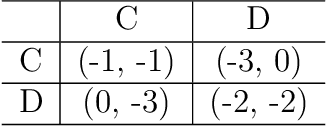
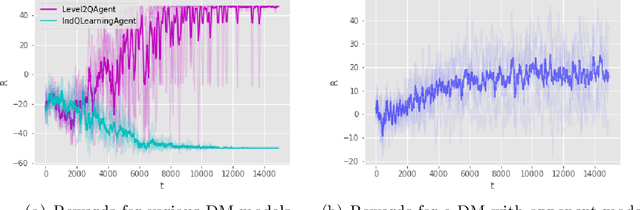
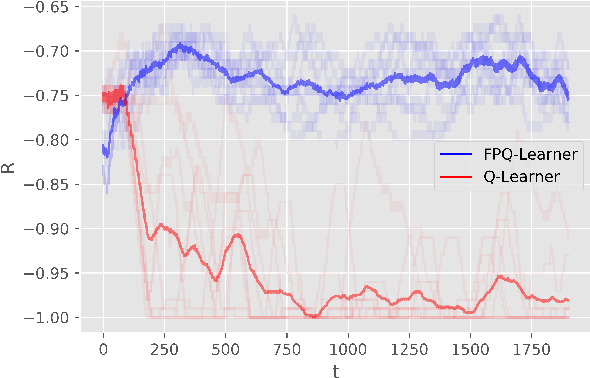
We introduce Threatened Markov Decision Processes (TMDPs) as an extension of the classical Markov Decision Process framework for Reinforcement Learning (RL). TMDPs allow suporting a decision maker against potential opponents in a RL context. We also propose a level-k thinking scheme resulting in a novel learning approach to deal with TMDPs. After introducing our framework and deriving theoretical results, relevant empirical evidence is given via extensive experiments, showing the benefits of accounting for adversaries in RL while the agent learns
* Substantially extends the previous work:
https://www.aaai.org/ojs/index.php/AAAI/article/view/5106. This article draws
heavily from arXiv arXiv:1809.01560
Via