 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre deep learning models superior for missing data imputation in large surveys? Evidence from an empirical comparison
Mar 14, 2021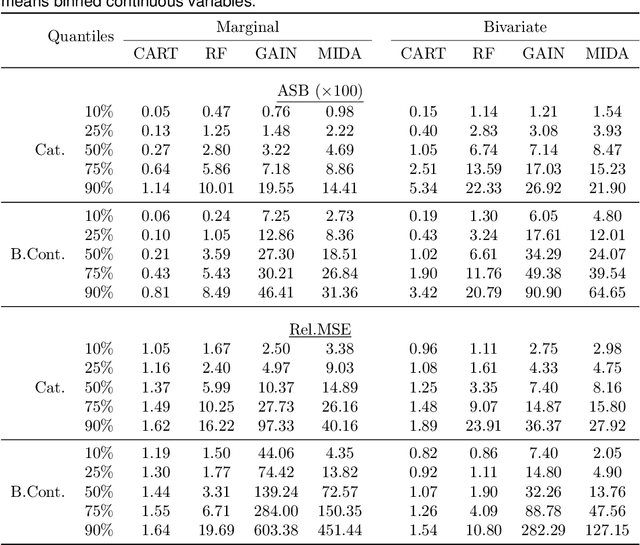
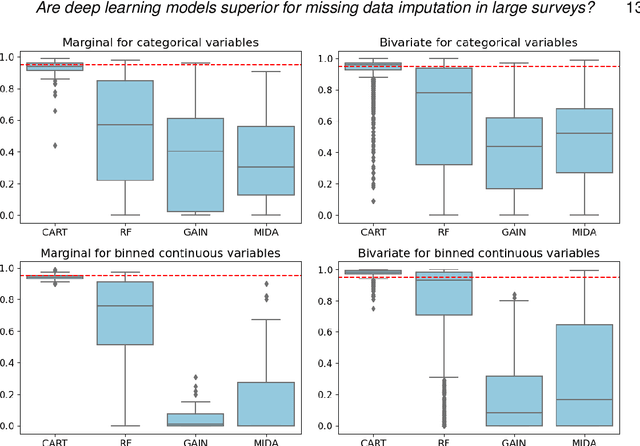

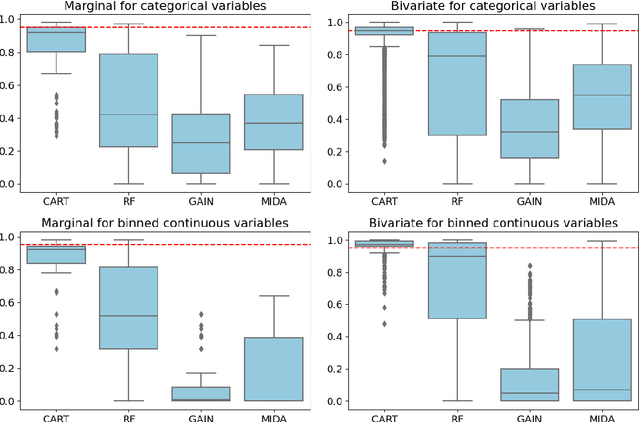
Multiple imputation (MI) is the state-of-the-art approach for dealing with missing data arising from non-response in sample surveys. Multiple imputation by chained equations (MICE) is the most widely used MI method, but it lacks theoretical foundation and is computationally intensive. Recently, MI methods based on deep learning models have been developed with encouraging results in small studies. However, there has been limited research on systematically evaluating their performance in realistic settings comparing to MICE, particularly in large-scale surveys. This paper provides a general framework for using simulations based on real survey data and several performance metrics to compare MI methods. We conduct extensive simulation studies based on the American Community Survey data to compare repeated sampling properties of four machine learning based MI methods: MICE with classification trees, MICE with random forests, generative adversarial imputation network, and multiple imputation using denoising autoencoders. We find the deep learning based MI methods dominate MICE in terms of computational time; however, MICE with classification trees consistently outperforms the deep learning MI methods in terms of bias, mean squared error, and coverage under a range of realistic settings.