Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention networks for image-to-text
Paper and Code

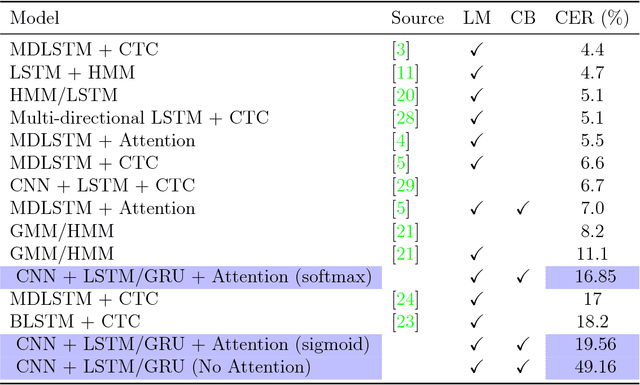
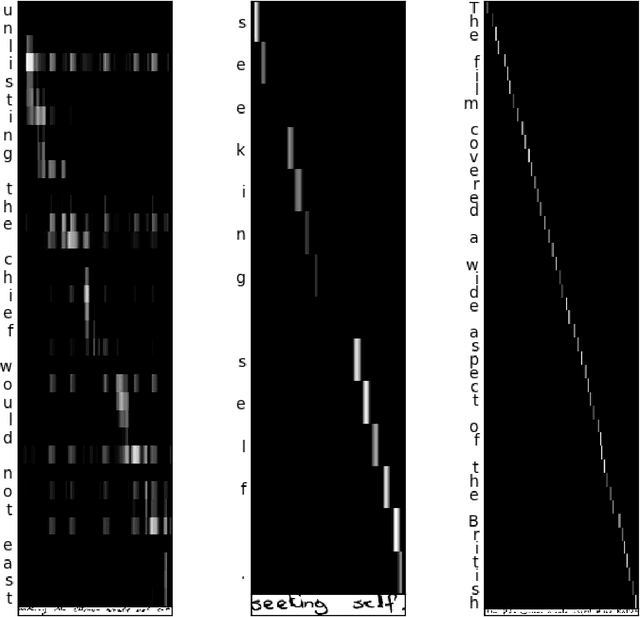

The paper approaches the problem of image-to-text with attention-based encoder-decoder networks that are trained to handle sequences of characters rather than words. We experiment on lines of text from a popular handwriting database with different attention mechanisms for the decoder. The model trained with softmax attention achieves the lowest test error, outperforming several other RNN-based models. Our results show that softmax attention is able to learn a linear alignment whereas the alignment generated by sigmoid attention is linear but much less precise.
View paper on