 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal and counterfactual views of missing data models
Oct 11, 2022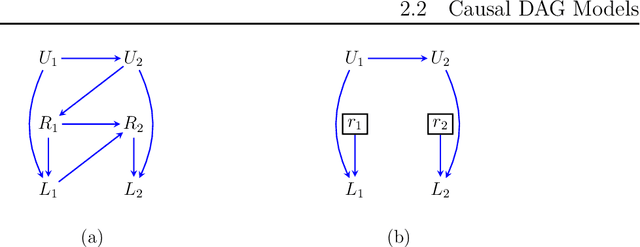
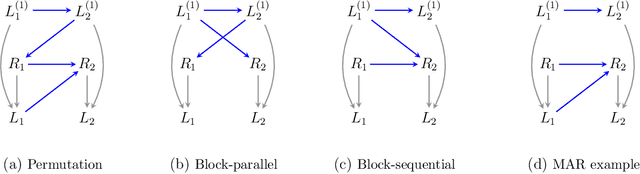
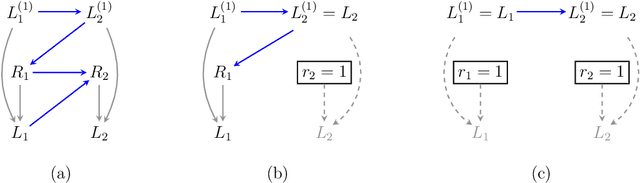
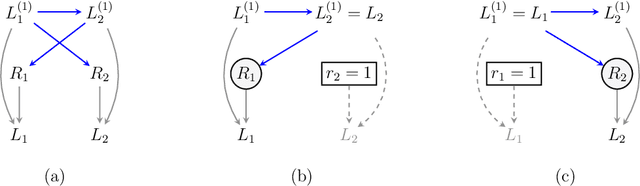
It is often said that the fundamental problem of causal inference is a missing data problem -- the comparison of responses to two hypothetical treatment assignments is made difficult because for every experimental unit only one potential response is observed. In this paper, we consider the implications of the converse view: that missing data problems are a form of causal inference. We make explicit how the missing data problem of recovering the complete data law from the observed law can be viewed as identification of a joint distribution over counterfactual variables corresponding to values had we (possibly contrary to fact) been able to observe them. Drawing analogies with causal inference, we show how identification assumptions in missing data can be encoded in terms of graphical models defined over counterfactual and observed variables. We review recent results in missing data identification from this viewpoint. In doing so, we note interesting similarities and differences between missing data and causal identification theories.
Double/De-Biased Machine Learning Using Regularized Riesz Representers
Mar 19, 2018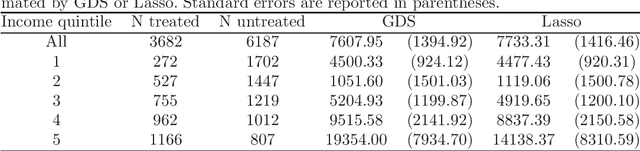
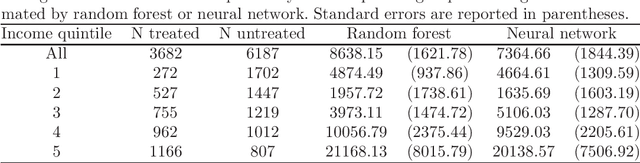
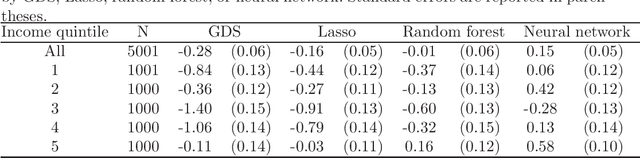
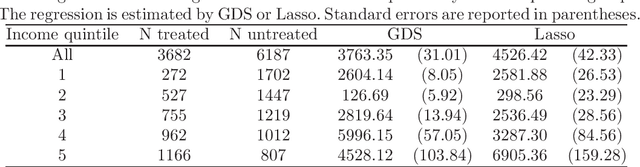
We provide adaptive inference methods for linear functionals of sparse linear approximations to the conditional expectation function. Examples of such functionals include average derivatives, policy effects, average treatment effects, and many others. The construction relies on building Neyman-orthogonal equations that are approximately invariant to perturbations of the nuisance parameters, including the Riesz representer for the linear functionals. We use L1-regularized methods to learn approximations to the regression function and the Riesz representer, and construct the estimator for the linear functionals as the solution to the orthogonal estimating equations. We establish that under weak assumptions the estimator concentrates in a 1/root n neighborhood of the target with deviations controlled by the normal laws, and the estimator attains the semi-parametric efficiency bound in many cases. In particular, either the approximation to the regression function or the approximation to the Riesz representer can be "dense" as long as one of them is sufficiently "sparse". Our main results are non-asymptotic and imply asymptotic uniform validity over large classes of models.
Double/Debiased Machine Learning for Treatment and Causal Parameters
Dec 12, 2017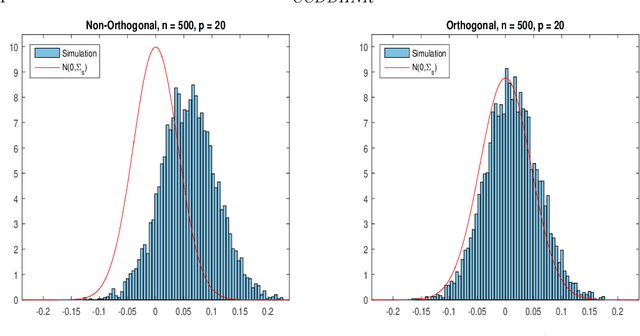
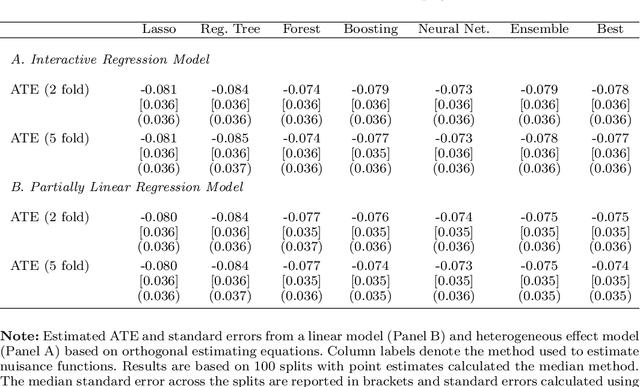
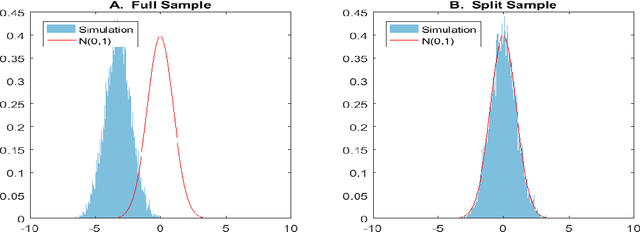
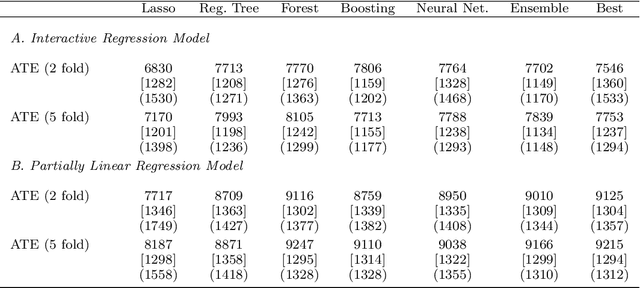
Most modern supervised statistical/machine learning (ML) methods are explicitly designed to solve prediction problems very well. Achieving this goal does not imply that these methods automatically deliver good estimators of causal parameters. Examples of such parameters include individual regression coefficients, average treatment effects, average lifts, and demand or supply elasticities. In fact, estimates of such causal parameters obtained via naively plugging ML estimators into estimating equations for such parameters can behave very poorly due to the regularization bias. Fortunately, this regularization bias can be removed by solving auxiliary prediction problems via ML tools. Specifically, we can form an orthogonal score for the target low-dimensional parameter by combining auxiliary and main ML predictions. The score is then used to build a de-biased estimator of the target parameter which typically will converge at the fastest possible 1/root(n) rate and be approximately unbiased and normal, and from which valid confidence intervals for these parameters of interest may be constructed. The resulting method thus could be called a "double ML" method because it relies on estimating primary and auxiliary predictive models. In order to avoid overfitting, our construction also makes use of the K-fold sample splitting, which we call cross-fitting. This allows us to use a very broad set of ML predictive methods in solving the auxiliary and main prediction problems, such as random forest, lasso, ridge, deep neural nets, boosted trees, as well as various hybrids and aggregators of these methods.
Efficient Nonparametric Conformal Prediction Regions
Nov 06, 2011

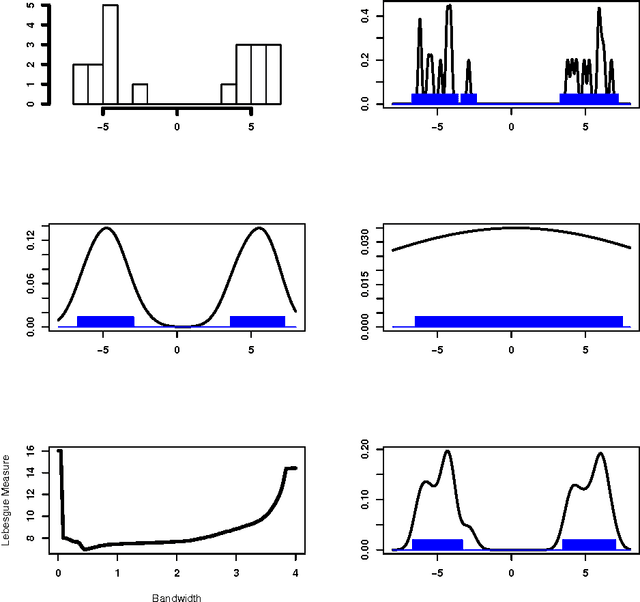

We investigate and extend the conformal prediction method due to Vovk,Gammerman and Shafer (2005) to construct nonparametric prediction regions. These regions have guaranteed distribution free, finite sample coverage, without any assumptions on the distribution or the bandwidth. Explicit convergence rates of the loss function are established for such regions under standard regularity conditions. Approximations for simplifying implementation and data driven bandwidth selection methods are also discussed. The theoretical properties of our method are demonstrated through simulations.