 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Multigrid Algorithms with Vision Transformer: A Novel Approach to Enhance the Seismic Foundation Model
Nov 17, 2025
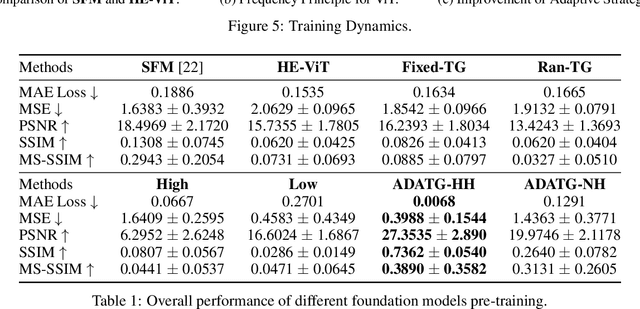


Due to the emergency and homogenization of Artificial Intelligence (AI) technology development, transformer-based foundation models have revolutionized scientific applications, such as drug discovery, materials research, and astronomy. However, seismic data presents unique characteristics that require specialized processing techniques for pretraining foundation models in seismic contexts with high- and low-frequency features playing crucial roles. Existing vision transformers (ViTs) with sequential tokenization ignore the intrinsic pattern and fail to grasp both the high- and low-frequency seismic information efficiently and effectively. This work introduces a novel adaptive two-grid foundation model training strategy (ADATG) with Hilbert encoding specifically tailored for seismogram data, leveraging the hierarchical structures inherent in seismic data. Specifically, our approach employs spectrum decomposition to separate high- and low-frequency components and utilizes hierarchical Hilbert encoding to represent the data effectively. Moreover, observing the frequency principle observed in ViTs, we propose an adaptive training strategy that initially emphasizes coarse-level information and then progressively refines the model's focus on fine-level features. Our extensive experiments demonstrate the effectiveness and efficiency of our training methods. This research highlights the importance of data encoding and training strategies informed by the distinct characteristics of high- and low-frequency features in seismic images, ultimately contributing to the enhancement of visual seismic foundation models pretraining.
DR-Encoder: Encode Low-rank Gradients with Random Prior for Large Language Models Differentially Privately
Dec 22, 2024



The emergence of the Large Language Model (LLM) has shown their superiority in a wide range of disciplines, including language understanding and translation, relational logic reasoning, and even partial differential equations solving. The transformer is the pervasive backbone architecture for the foundation model construction. It is vital to research how to adjust the Transformer architecture to achieve an end-to-end privacy guarantee in LLM fine-tuning. In this paper, we investigate three potential information leakage during a federated fine-tuning procedure for LLM (FedLLM). Based on the potential information leakage, we provide an end-to-end privacy guarantee solution for FedLLM by inserting two-stage randomness. The first stage is to train a gradient auto-encoder with a Gaussian random prior based on the statistical information of the gradients generated by local clients. The second stage is to fine-tune the overall LLM with a differential privacy guarantee by adopting appropriate Gaussian noises. We show the efficiency and accuracy gains of our proposed method with several foundation models and two popular evaluation benchmarks. Furthermore, we present a comprehensive privacy analysis with Gaussian Differential Privacy (GDP) and Renyi Differential Privacy (RDP).
Iter-AHMCL: Alleviate Hallucination for Large Language Model via Iterative Model-level Contrastive Learning
Oct 16, 2024



The development of Large Language Models (LLMs) has significantly advanced various AI applications in commercial and scientific research fields, such as scientific literature summarization, writing assistance, and knowledge graph construction. However, a significant challenge is the high risk of hallucination during LLM inference, which can lead to security concerns like factual inaccuracies, inconsistent information, and fabricated content. To tackle this issue, it is essential to develop effective methods for reducing hallucination while maintaining the original capabilities of the LLM. This paper introduces a novel approach called Iterative Model-level Contrastive Learning (Iter-AHMCL) to address hallucination. This method modifies the representation layers of pre-trained LLMs by using contrastive `positive' and `negative' models, trained on data with and without hallucinations. By leveraging the differences between these two models, we create a more straightforward pathway to eliminate hallucinations, and the iterative nature of contrastive learning further enhances performance. Experimental validation on four pre-trained foundation LLMs (LLaMA2, Alpaca, LLaMA3, and Qwen) finetuning with a specially designed dataset shows that our approach achieves an average improvement of 10.1 points on the TruthfulQA benchmark. Comprehensive experiments demonstrate the effectiveness of Iter-AHMCL in reducing hallucination while maintaining the general capabilities of LLMs.
Contextual Bandits for Unbounded Context Distributions
Aug 19, 2024



Nonparametric contextual bandit is an important model of sequential decision making problems. Under $\alpha$-Tsybakov margin condition, existing research has established a regret bound of $\tilde{O}\left(T^{1-\frac{\alpha+1}{d+2}}\right)$ for bounded supports. However, the optimal regret with unbounded contexts has not been analyzed. The challenge of solving contextual bandit problems with unbounded support is to achieve both exploration-exploitation tradeoff and bias-variance tradeoff simultaneously. In this paper, we solve the nonparametric contextual bandit problem with unbounded contexts. We propose two nearest neighbor methods combined with UCB exploration. The first method uses a fixed $k$. Our analysis shows that this method achieves minimax optimal regret under a weak margin condition and relatively light-tailed context distributions. The second method uses adaptive $k$. By a proper data-driven selection of $k$, this method achieves an expected regret of $\tilde{O}\left(T^{1-\frac{(\alpha+1)\beta}{\alpha+(d+2)\beta}}+T^{1-\beta}\right)$, in which $\beta$ is a parameter describing the tail strength. This bound matches the minimax lower bound up to logarithm factors, indicating that the second method is approximately optimal.
Learning with User-Level Local Differential Privacy
May 27, 2024
User-level privacy is important in distributed systems. Previous research primarily focuses on the central model, while the local models have received much less attention. Under the central model, user-level DP is strictly stronger than the item-level one. However, under the local model, the relationship between user-level and item-level LDP becomes more complex, thus the analysis is crucially different. In this paper, we first analyze the mean estimation problem and then apply it to stochastic optimization, classification, and regression. In particular, we propose adaptive strategies to achieve optimal performance at all privacy levels. Moreover, we also obtain information-theoretic lower bounds, which show that the proposed methods are minimax optimal up to logarithmic factors. Unlike the central DP model, where user-level DP always leads to slower convergence, our result shows that under the local model, the convergence rates are nearly the same between user-level and item-level cases for distributions with bounded support. For heavy-tailed distributions, the user-level rate is even faster than the item-level one.
Enhancing Learning with Label Differential Privacy by Vector Approximation
May 24, 2024Label differential privacy (DP) is a framework that protects the privacy of labels in training datasets, while the feature vectors are public. Existing approaches protect the privacy of labels by flipping them randomly, and then train a model to make the output approximate the privatized label. However, as the number of classes $K$ increases, stronger randomization is needed, thus the performances of these methods become significantly worse. In this paper, we propose a vector approximation approach, which is easy to implement and introduces little additional computational overhead. Instead of flipping each label into a single scalar, our method converts each label into a random vector with $K$ components, whose expectations reflect class conditional probabilities. Intuitively, vector approximation retains more information than scalar labels. A brief theoretical analysis shows that the performance of our method only decays slightly with $K$. Finally, we conduct experiments on both synthesized and real datasets, which validate our theoretical analysis as well as the practical performance of our method.
CG-FedLLM: How to Compress Gradients in Federated Fune-tuning for Large Language Models
May 22, 2024



The success of current Large-Language Models (LLMs) hinges on extensive training data that is collected and stored centrally, called Centralized Learning (CL). However, such a collection manner poses a privacy threat, and one potential solution is Federated Learning (FL), which transfers gradients, not raw data, among clients. Unlike traditional networks, FL for LLMs incurs significant communication costs due to their tremendous parameters. This study introduces an innovative approach to compress gradients to improve communication efficiency during LLM FL, formulating the new FL pipeline named CG-FedLLM. This approach integrates an encoder on the client side to acquire the compressed gradient features and a decoder on the server side to reconstruct the gradients. We also developed a novel training strategy that comprises Temporal-ensemble Gradient-Aware Pre-training (TGAP) to identify characteristic gradients of the target model and Federated AutoEncoder-Involved Fine-tuning (FAF) to compress gradients adaptively. Extensive experiments confirm that our approach reduces communication costs and improves performance (e.g., average 3 points increment compared with traditional CL- and FL-based fine-tuning with LlaMA on a well-recognized benchmark, C-Eval). This improvement is because our encoder-decoder, trained via TGAP and FAF, can filter gradients while selectively preserving critical features. Furthermore, we present a series of experimental analyses focusing on the signal-to-noise ratio, compression rate, and robustness within this privacy-centric framework, providing insight into developing more efficient and secure LLMs.
Differential Private Knowledge Transfer for Privacy-Preserving Cross-Domain Recommendation
Feb 10, 2022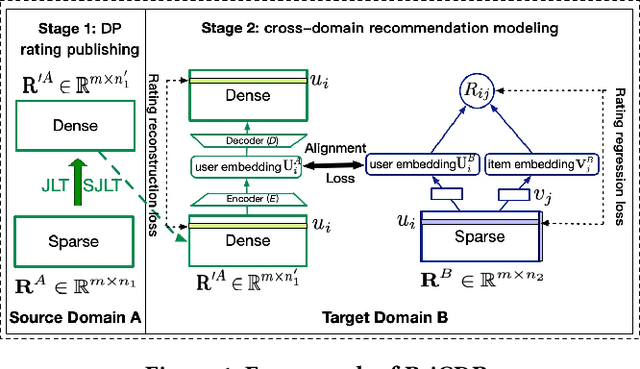
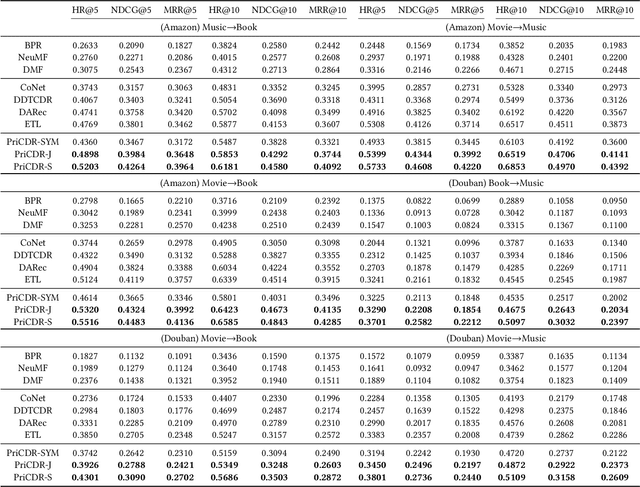
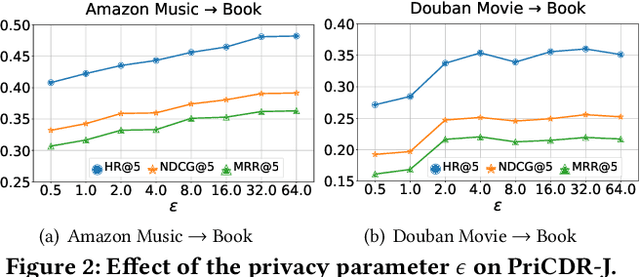

Cross Domain Recommendation (CDR) has been popularly studied to alleviate the cold-start and data sparsity problem commonly existed in recommender systems. CDR models can improve the recommendation performance of a target domain by leveraging the data of other source domains. However, most existing CDR models assume information can directly 'transfer across the bridge', ignoring the privacy issues. To solve the privacy concern in CDR, in this paper, we propose a novel two stage based privacy-preserving CDR framework (PriCDR). In the first stage, we propose two methods, i.e., Johnson-Lindenstrauss Transform (JLT) based and Sparse-awareJLT (SJLT) based, to publish the rating matrix of the source domain using differential privacy. We theoretically analyze the privacy and utility of our proposed differential privacy based rating publishing methods. In the second stage, we propose a novel heterogeneous CDR model (HeteroCDR), which uses deep auto-encoder and deep neural network to model the published source rating matrix and target rating matrix respectively. To this end, PriCDR can not only protect the data privacy of the source domain, but also alleviate the data sparsity of the source domain. We conduct experiments on two benchmark datasets and the results demonstrate the effectiveness of our proposed PriCDR and HeteroCDR.
A Theoretical Perspective on Differentially Private Federated Multi-task Learning
Nov 14, 2020

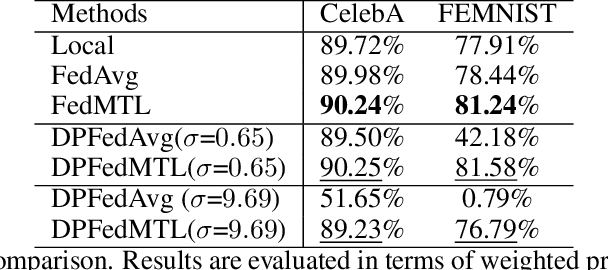
In the era of big data, the need to expand the amount of data through data sharing to improve model performance has become increasingly compelling. As a result, effective collaborative learning models need to be developed with respect to both privacy and utility concerns. In this work, we propose a new federated multi-task learning method for effective parameter transfer with differential privacy to protect gradients at the client level. Specifically, the lower layers of the networks are shared across all clients to capture transferable feature representation, while top layers of the network are task-specific for on-client personalization. Our proposed algorithm naturally resolves the statistical heterogeneity problem in federated networks. We are, to the best of knowledge, the first to provide both privacy and utility guarantees for such a proposed federated algorithm. The convergences are proved for the cases with Lipschitz smooth objective functions under the non-convex, convex, and strongly convex settings. Empirical experiment results on different datasets have been conducted to demonstrate the effectiveness of the proposed algorithm and verify the implications of the theoretical findings.