 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and sparse support vector machine via hybrid truncated loss for supervised classification
Jun 04, 2026The support vector machine (SVM) is a widely used classifier, but choosing an appropriate loss function remains difficult. Convex losses such as the hinge loss and least-squares loss are sensitive to outliers, while bounded non-convex losses often lead to high computational cost. To address this, we propose a hybrid truncated loss function ($L_{\mathrm{ht}}$) that is both sparse and bounded, and build the $L_{\mathrm{ht}}$-SVM model for single-view classification. We introduce the P-stationary point and use it to establish the first-order necessary and sufficient optimality conditions. Based on these conditions, we design an alternating direction method of multipliers with a working-set strategy that reduces computational cost and achieves global convergence. We further extend $L_{\mathrm{ht}}$-SVM to multi-view learning by adding structural information and view weights, resulting in Mv$L_{\mathrm{ht}}$-SVM, which follows both the consensus and complementarity principles. Experiments on synthetic, real-world, and image datasets show that $L_{\mathrm{ht}}$-SVM achieves higher accuracy with fewer support vectors and better noise robustness than five single-view methods, while Mv$L_{\mathrm{ht}}$-SVM outperforms six multi-view methods in accuracy, precision, recall, and F1-score.
Exploring the Technical Knowledge Interaction of Global Digital Humanities: Three-decade Evidence from Bibliometric-based perspectives
Aug 11, 2025


Digital Humanities (DH) is an interdisciplinary field that integrates computational methods with humanities scholarship to investigate innovative topics. Each academic discipline follows a unique developmental path shaped by the topics researchers investigate and the methods they employ. With the help of bibliometric analysis, most of previous studies have examined DH across multiple dimensions such as research hotspots, co-author networks, and institutional rankings. However, these studies have often been limited in their ability to provide deep insights into the current state of technological advancements and topic development in DH. As a result, their conclusions tend to remain superficial or lack interpretability in understanding how methods and topics interrelate in the field. To address this gap, this study introduced a new concept of Topic-Method Composition (TMC), which refers to a hybrid knowledge structure generated by the co-occurrence of specific research topics and the corresponding method. Especially by analyzing the interaction between TMCs, we can see more clearly the intersection and integration of digital technology and humanistic subjects in DH. Moreover, this study developed a TMC-based workflow combining bibliometric analysis, topic modeling, and network analysis to analyze the development characteristics and patterns of research disciplines. By applying this workflow to large-scale bibliometric data, it enables a detailed view of the knowledge structures, providing a tool adaptable to other fields.
Neighboring Slice Noise2Noise: Self-Supervised Medical Image Denoising from Single Noisy Image Volume
Nov 16, 2024



In the last few years, with the rapid development of deep learning technologies, supervised methods based on convolutional neural networks have greatly enhanced the performance of medical image denoising. However, these methods require large quantities of noisy-clean image pairs for training, which greatly limits their practicality. Although some researchers have attempted to train denoising networks using only single noisy images, existing self-supervised methods, including blind-spot-based and data-splitting-based methods, heavily rely on the assumption that noise is pixel-wise independent. However, this assumption often does not hold in real-world medical images. Therefore, in the field of medical imaging, there remains a lack of simple and practical denoising methods that can achieve high-quality denoising performance using only single noisy images. In this paper, we propose a novel self-supervised medical image denoising method, Neighboring Slice Noise2Noise (NS-N2N). The proposed method utilizes neighboring slices within a single noisy image volume to construct weighted training data, and then trains the denoising network using a self-supervised scheme with regional consistency loss and inter-slice continuity loss. NS-N2N only requires a single noisy image volume obtained from one medical imaging procedure to achieve high-quality denoising of the image volume itself. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art self-supervised denoising methods in both denoising performance and processing efficiency. Furthermore, since NS-N2N operates solely in the image domain, it is free from device-specific issues such as reconstruction geometry, making it easier to apply in various clinical practices.
Exploring Multimodal Sentiment Analysis via CBAM Attention and Double-layer BiLSTM Architecture
Mar 26, 2023



Because multimodal data contains more modal information, multimodal sentiment analysis has become a recent research hotspot. However, redundant information is easily involved in feature fusion after feature extraction, which has a certain impact on the feature representation after fusion. Therefore, in this papaer, we propose a new multimodal sentiment analysis model. In our model, we use BERT + BiLSTM as new feature extractor to capture the long-distance dependencies in sentences and consider the position information of input sequences to obtain richer text features. To remove redundant information and make the network pay more attention to the correlation between image and text features, CNN and CBAM attention are added after splicing text features and picture features, to improve the feature representation ability. On the MVSA-single dataset and HFM dataset, compared with the baseline model, the ACC of our model is improved by 1.78% and 1.91%, and the F1 value is enhanced by 3.09% and 2.0%, respectively. The experimental results show that our model achieves a sound effect, similar to the advanced model.
Exploring Turkish Speech Recognition via Hybrid CTC/Attention Architecture and Multi-feature Fusion Network
Mar 22, 2023



In recent years, End-to-End speech recognition technology based on deep learning has developed rapidly. Due to the lack of Turkish speech data, the performance of Turkish speech recognition system is poor. Firstly, this paper studies a series of speech recognition tuning technologies. The results show that the performance of the model is the best when the data enhancement technology combining speed perturbation with noise addition is adopted and the beam search width is set to 16. Secondly, to maximize the use of effective feature information and improve the accuracy of feature extraction, this paper proposes a new feature extractor LSPC. LSPC and LiGRU network are combined to form a shared encoder structure, and model compression is realized. The results show that the performance of LSPC is better than MSPC and VGGnet when only using Fbank features, and the WER is improved by 1.01% and 2.53% respectively. Finally, based on the above two points, a new multi-feature fusion network is proposed as the main structure of the encoder. The results show that the WER of the proposed feature fusion network based on LSPC is improved by 0.82% and 1.94% again compared with the single feature (Fbank feature and Spectrogram feature) extraction using LSPC. Our model achieves performance comparable to that of advanced End-to-End models.
Multi-view learning with privileged weighted twin support vector machine
Jan 27, 2022
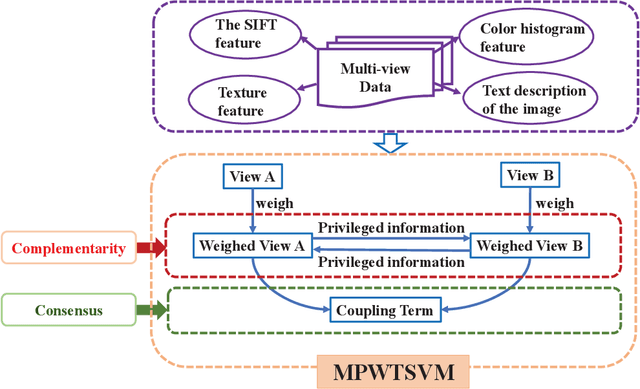

Weighted twin support vector machines (WLTSVM) mines as much potential similarity information in samples as possible to improve the common short-coming of non-parallel plane classifiers. Compared with twin support vector machines (TWSVM), it reduces the time complexity by deleting the superfluous constraints using the inter-class K-Nearest Neighbor (KNN). Multi-view learning (MVL) is a newly developing direction of machine learning, which focuses on learning acquiring information from the data indicated by multiple feature sets. In this paper, we propose multi-view learning with privileged weighted twin support vector machines (MPWTSVM). It not only inherits the advantages of WLTSVM but also has its characteristics. Firstly, it enhances generalization ability by mining intra-class information from the same perspective. Secondly, it reduces the redundancy constraints with the help of inter-class information, thus improving the running speed. Most importantly, it can follow both the consensus and the complementarity principle simultaneously as a multi-view classification model. The consensus principle is realized by minimizing the coupling items of the two views in the original objective function. The complementary principle is achieved by establishing privileged information paradigms and MVL. A standard quadratic programming solver is used to solve the problem. Compared with multi-view classification models such as SVM-2K, MVTSVM, MCPK, and PSVM-2V, our model has better accuracy and classification efficiency. Experimental results on 45 binary data sets prove the effectiveness of our method.
Automated classification of stems and leaves of potted plants based on point cloud data
Feb 28, 2020

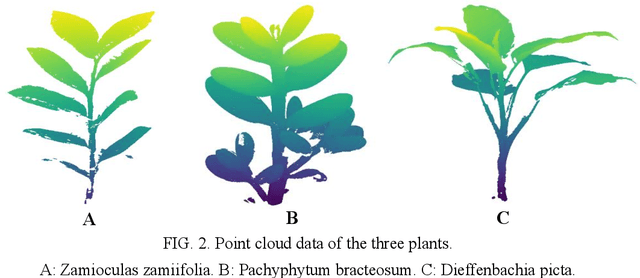

The accurate classification of plant organs is a key step in monitoring the growing status and physiology of plants. A classification method was proposed to classify the leaves and stems of potted plants automatically based on the point cloud data of the plants, which is a nondestructive acquisition. The leaf point training samples were automatically extracted by using the three-dimensional convex hull algorithm, while stem point training samples were extracted by using the point density of a two-dimensional projection. The two training sets were used to classify all the points into leaf points and stem points by utilizing the support vector machine (SVM) algorithm. The proposed method was tested by using the point cloud data of three potted plants and compared with two other methods, which showed that the proposed method can classify leaf and stem points accurately and efficiently.