 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Reality Robot Behavior Replay: A System Implementation
Sep 30, 2022



As robots become increasingly complex, they must explain their behaviors to gain trust and acceptance. However, it may be difficult through verbal explanation alone to fully convey information about past behavior, especially regarding objects no longer present due to robots' or humans' actions. Humans often try to physically mimic past movements to accompany verbal explanations. Inspired by this human-human interaction, we describe the technical implementation of a system for past behavior replay for robots in this tool paper. Specifically, we used Behavior Trees to encode and separate robot behaviors, and schemaless MongoDB to structurally store and query the underlying sensor data and joint control messages for future replay. Our approach generalizes to different types of replays, including both manipulation and navigation replay, and visual (i.e., augmented reality (AR)) and auditory replay. Additionally, we briefly summarize a user study to further provide empirical evidence of its effectiveness and efficiency. Sample code and instructions are available on GitHub at https://github.com/umhan35/robot-behavior-replay.
* 6 pages, 5 figures, the AI-HRI Symposium at AAAI Fall Symposium Series (FSS) 2022
Causal Robot Communication Inspired by Observational Learning Insights
Mar 17, 2022Autonomous robots must communicate about their decisions to gain trust and acceptance. When doing so, robots must determine which actions are causal, i.e., which directly give rise to the desired outcome, so that these actions can be included in explanations. In behavior learning in psychology, this sort of reasoning during an action sequence has been studied extensively in the context of imitation learning. And yet, these techniques and empirical insights are rarely applied to human-robot interaction (HRI). In this work, we discuss the relevance of behavior learning insights for robot intent communication, and present the first application of these insights for a robot to efficiently communicate its intent by selectively explaining the causal actions in an action sequence.
Projecting Robot Navigation Paths: Hardware and Software for Projected AR
Jan 06, 2022


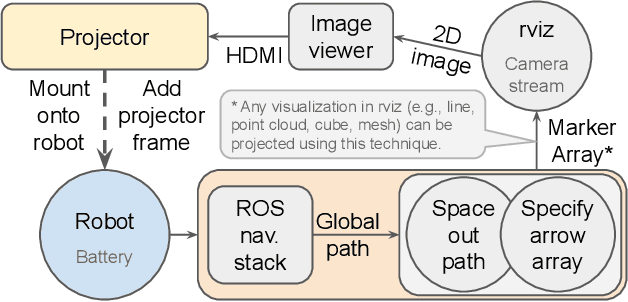
For mobile robots, mobile manipulators, and autonomous vehicles to safely navigate around populous places such as streets and warehouses, human observers must be able to understand their navigation intent. One way to enable such understanding is by visualizing this intent through projections onto the surrounding environment. But despite the demonstrated effectiveness of such projections, no open codebase with an integrated hardware setup exists. In this work, we detail the empirical evidence for the effectiveness of such directional projections, and share a robot-agnostic implementation of such projections, coded in C++ using the widely-used Robot Operating System (ROS) and rviz. Additionally, we demonstrate a hardware configuration for deploying this software, using a Fetch robot, and briefly summarize a full-scale user study that motivates this configuration. The code, configuration files (roslaunch and rviz files), and documentation are freely available on GitHub at https://github.com/umhan35/arrow_projection.
Semi-Autonomous Planning and Visualization in Virtual Reality
Apr 23, 2021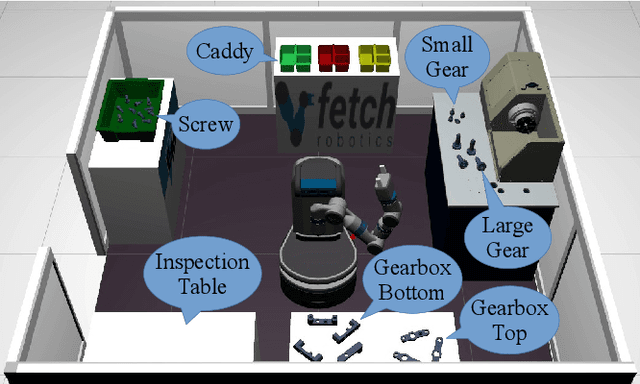
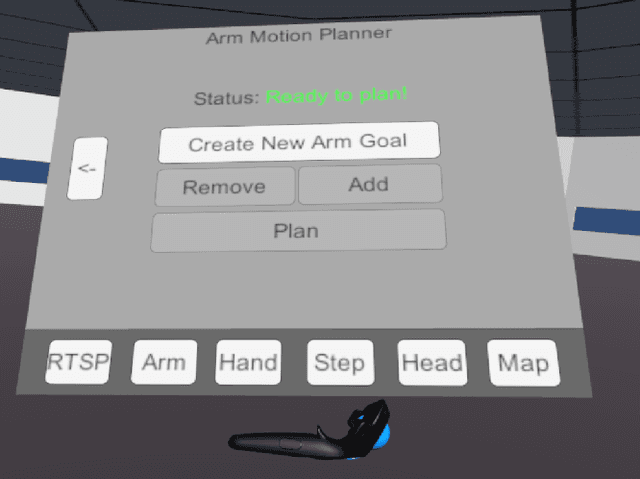

Virtual reality (VR) interfaces for robots provide a three-dimensional (3D) view of the robot in its environment, which allows people to better plan complex robot movements in tight or cluttered spaces. In our prior work, we created a VR interface to allow for the teleoperation of a humanoid robot. As detailed in this paper, we have now focused on a human-in-the-loop planner where the operator can send higher level manipulation and navigation goals in VR through functional waypoints, visualize the results of a robot planner in the 3D virtual space, and then deny, alter or confirm the plan to send to the robot. In addition, we have adapted our interface to also work for a mobile manipulation robot in addition to the humanoid robot. For a video demonstration please see the accompanying video at https://youtu.be/wEHZug_fxrA.
Investigation of Multiple Resource Theory Design Principles on Robot Teleoperation and Workload Management
Mar 31, 2021
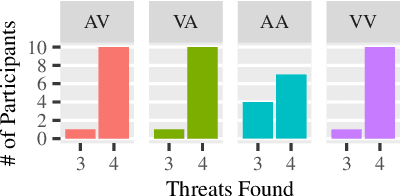
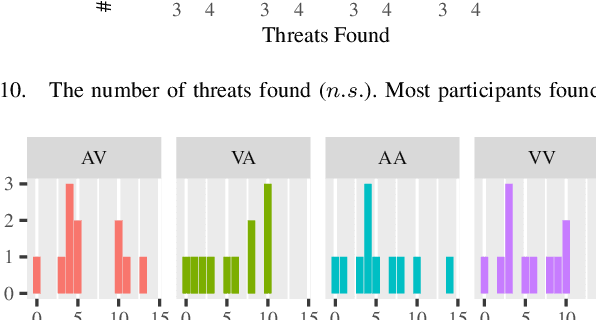
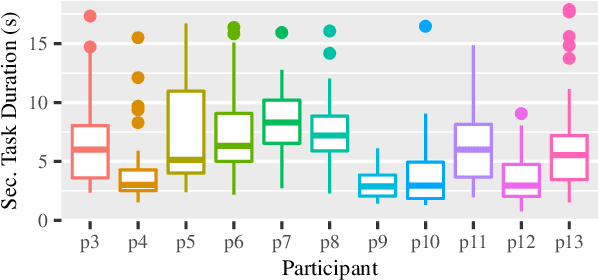
Robot interfaces often only use the visual channel. Inspired by Wickens' Multiple Resource Theory, we investigated if the addition of audio elements would reduce cognitive workload and improve performance. Specifically, we designed a search and threat-defusal task (primary) with a memory test task (secondary). Eleven participants - predominantly first responders - were recruited to control a robot to clear all threats in a combination of four conditions of primary and secondary tasks in visual and auditory channels. We did not find any statistically significant differences in performance or workload across subjects, making it questionable that Multiple Resource Theory could shorten longer-term task completion time and reduce workload. Our results suggest that considering individual differences for splitting interface modalities across multiple channels requires further investigation.
Reasons People Want Explanations After Unrecoverable Pre-Handover Failures
Oct 05, 2020
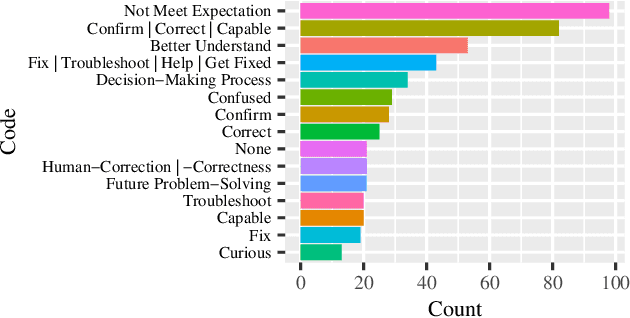
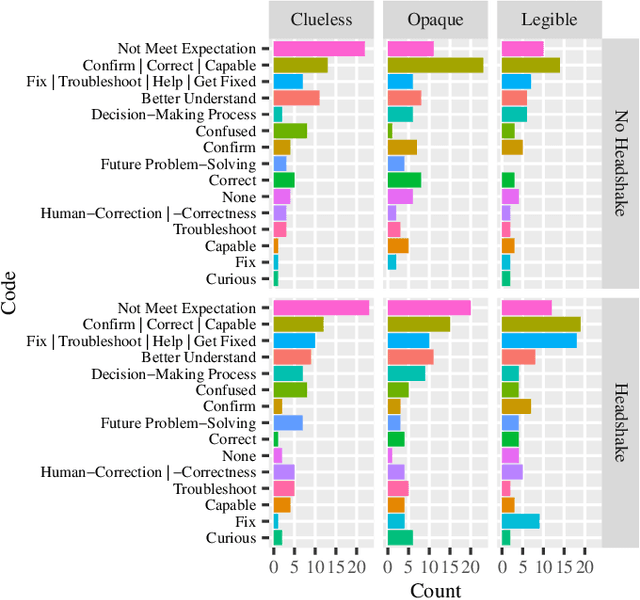
Most research on human-robot handovers focuses on the development of comfortable and efficient HRI; few have studied handover failures. If a failure occurs in the beginning of the interaction, it prevents the whole handover process and destroys trust. Here we analyze the underlying reasons why people want explanations in a handover scenario where a robot cannot possess the object. Results suggest that participants set expectations on their request and that a robot should provide explanations rather than non-verbal cues after failing. Participants also expect that their handover request can be done by a robot, and, if not, would like to be able to fix the robot or change the request based on the provided explanations.
Projection Mapping Implementation: Enabling Direct Externalization of Perception Results and Action Intent to Improve Robot Explainability
Oct 05, 2020
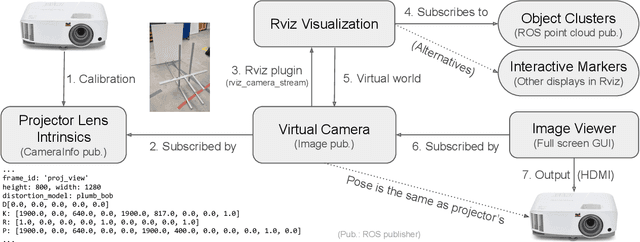


Existing research on non-verbal cues, e.g., eye gaze or arm movement, may not accurately present a robot's internal states such as perception results and action intent. Projecting the states directly onto a robot's operating environment has the advantages of being direct, accurate, and more salient, eliminating mental inference about the robot's intention. However, there is a lack of tools for projection mapping in robotics, compared to established motion planning libraries (e.g., MoveIt). In this paper, we detail the implementation of projection mapping to enable researchers and practitioners to push the boundaries for better interaction between robots and humans. We also provide practical documentation and code for a sample manipulation projection mapping on GitHub: github.com/uml-robotics/projection_mapping.
Towards Mobile Multi-Task Manipulation in a Confined and Integrated Environment with Irregular Objects
Mar 03, 2020


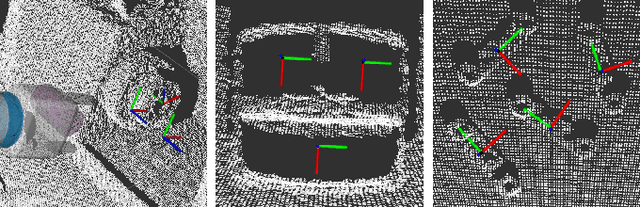
The FetchIt! Mobile Manipulation Challenge, held at the IEEE International Conference on Robots and Automation (ICRA) in May 2019, offered an environment with complex and integrated task sets, irregular objects, confined space, and machining, introducing new challenges in the mobile manipulation domain. Here we describe our efforts to address these challenges by demonstrating the assembly of a kit of mechanical parts in a caddy. In addition to implementation details, we examine the issues in this task set extensively, and we discuss our software architecture in the hope of providing a base for other researchers. To evaluate performance and consistency, we conducted 20 full runs, then examined failure cases with possible solutions. We conclude by identifying future research directions to address the open challenges.
Towards A Robot Explanation System: A Survey and Our Approach to State Summarization, Storage and Querying, and Human Interface
Sep 13, 2019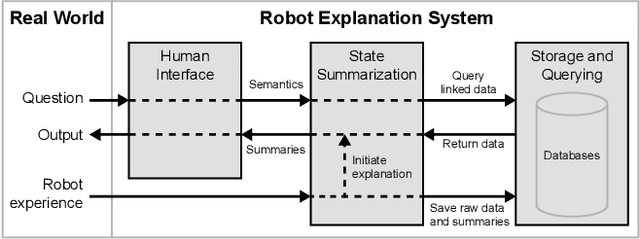
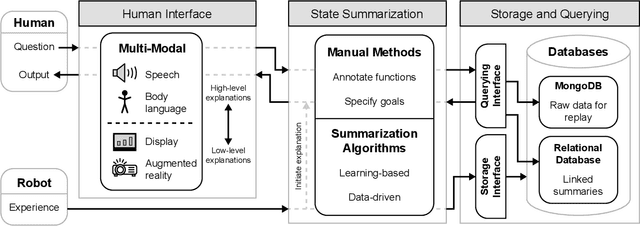

As robot systems become more ubiquitous, developing understandable robot systems becomes increasingly important in order to build trust. In this paper, we present an approach to developing a holistic robot explanation system, which consists of three interconnected components: state summarization, storage and querying, and human interface. To find trends towards and gaps in the development of such an integrated system, a literature review was performed and categorized around those three components, with a focus on robotics applications. After the review of each component, we discuss our proposed approach for robot explanation. Finally, we summarize the system as a whole and review its functionality.