 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Deep Image Compression via Content-Adaptive Optimization with Adapters
Nov 02, 2022
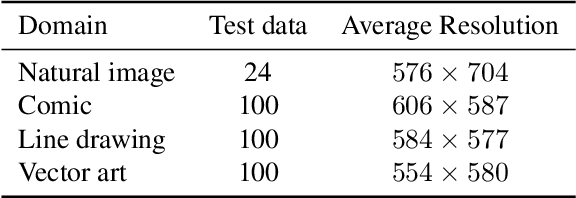
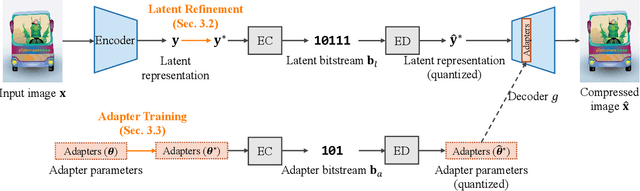
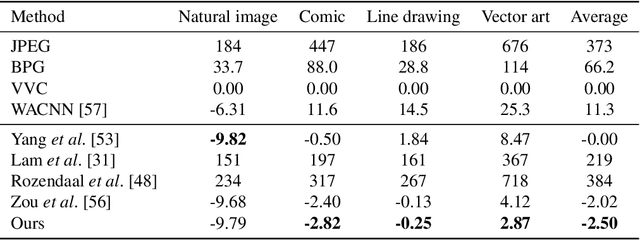
Deep image compression performs better than conventional codecs, such as JPEG, on natural images. However, deep image compression is learning-based and encounters a problem: the compression performance deteriorates significantly for out-of-domain images. In this study, we highlight this problem and address a novel task: universal deep image compression. This task aims to compress images belonging to arbitrary domains, such as natural images, line drawings, and comics. To address this problem, we propose a content-adaptive optimization framework; this framework uses a pre-trained compression model and adapts the model to a target image during compression. Adapters are inserted into the decoder of the model. For each input image, our framework optimizes the latent representation extracted by the encoder and the adapter parameters in terms of rate-distortion. The adapter parameters are additionally transmitted per image. For the experiments, a benchmark dataset containing uncompressed images of four domains (natural images, line drawings, comics, and vector arts) is constructed and the proposed universal deep compression is evaluated. Finally, the proposed model is compared with non-adaptive and existing adaptive compression models. The comparison reveals that the proposed model outperforms these. The code and dataset are publicly available at https://github.com/kktsubota/universal-dic.
Evaluating the Stability of Deep Image Quality Assessment With Respect to Image Scaling
Jul 20, 2022



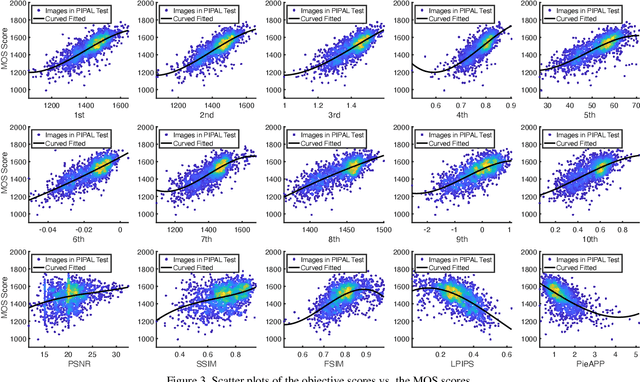
Image quality assessment (IQA) is a fundamental metric for image processing tasks (e.g., compression). With full-reference IQAs, traditional IQAs, such as PSNR and SSIM, have been used. Recently, IQAs based on deep neural networks (deep IQAs), such as LPIPS and DISTS, have also been used. It is known that image scaling is inconsistent among deep IQAs, as some perform down-scaling as pre-processing, whereas others instead use the original image size. In this paper, we show that the image scale is an influential factor that affects deep IQA performance. We comprehensively evaluate four deep IQAs on the same five datasets, and the experimental results show that image scale significantly influences IQA performance. We found that the most appropriate image scale is often neither the default nor the original size, and the choice differs depending on the methods and datasets used. We visualized the stability and found that PieAPP is the most stable among the four deep IQAs.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021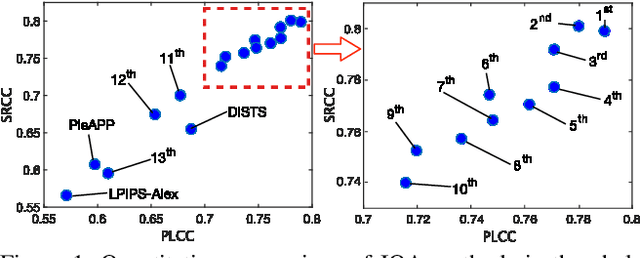
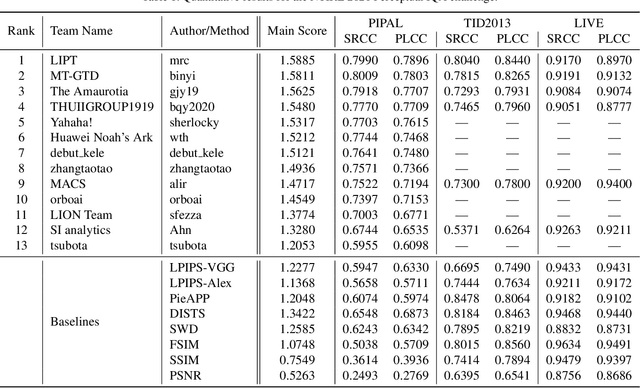

This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Channel-Level Variable Quantization Network for Deep Image Compression
Jul 15, 2020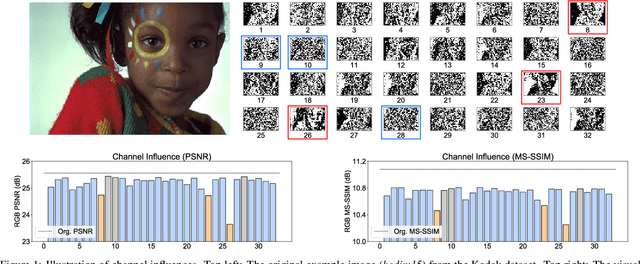

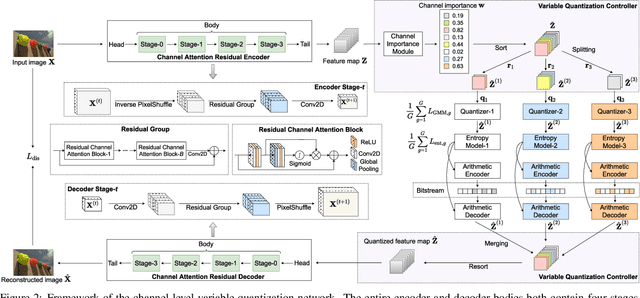
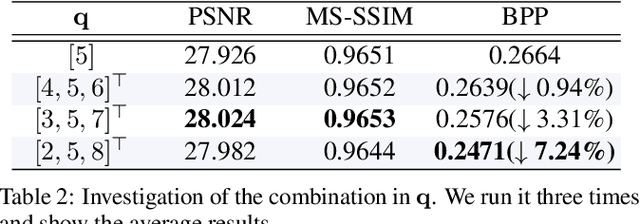
Deep image compression systems mainly contain four components: encoder, quantizer, entropy model, and decoder. To optimize these four components, a joint rate-distortion framework was proposed, and many deep neural network-based methods achieved great success in image compression. However, almost all convolutional neural network-based methods treat channel-wise feature maps equally, reducing the flexibility in handling different types of information. In this paper, we propose a channel-level variable quantization network to dynamically allocate more bitrates for significant channels and withdraw bitrates for negligible channels. Specifically, we propose a variable quantization controller. It consists of two key components: the channel importance module, which can dynamically learn the importance of channels during training, and the splitting-merging module, which can allocate different bitrates for different channels. We also formulate the quantizer into a Gaussian mixture model manner. Quantitative and qualitative experiments verify the effectiveness of the proposed model and demonstrate that our method achieves superior performance and can produce much better visual reconstructions.