 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymBa: Symmetric Backpropagation-Free Contrastive Learning with Forward-Forward Algorithm for Optimizing Convergence
Mar 15, 2023The paper proposes a new algorithm called SymBa that aims to achieve more biologically plausible learning than Back-Propagation (BP). The algorithm is based on the Forward-Forward (FF) algorithm, which is a BP-free method for training neural networks. SymBa improves the FF algorithm's convergence behavior by addressing the problem of asymmetric gradients caused by conflicting converging directions for positive and negative samples. The algorithm balances positive and negative losses to enhance performance and convergence speed. Furthermore, it modifies the FF algorithm by adding Intrinsic Class Pattern (ICP) containing class information to prevent the loss of class information during training. The proposed algorithm has the potential to improve our understanding of how the brain learns and processes information and to develop more effective and efficient artificial intelligence systems. The paper presents experimental results that demonstrate the effectiveness of SymBa algorithm compared to the FF algorithm and BP.
X-ViT: High Performance Linear Vision Transformer without Softmax
May 27, 2022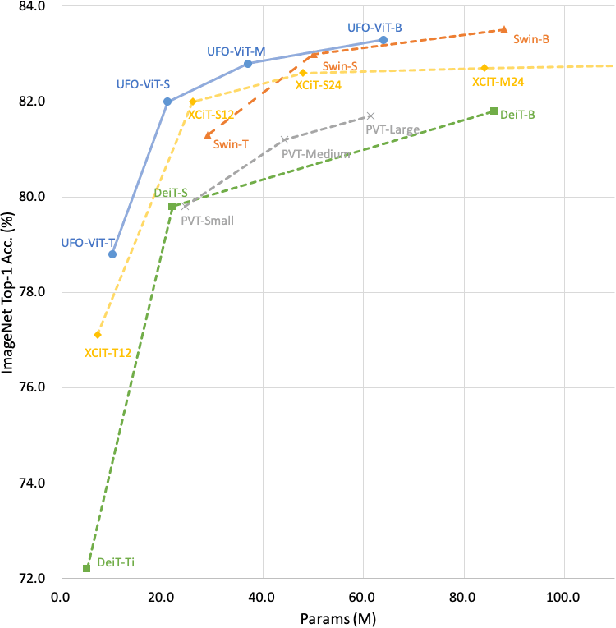



Vision transformers have become one of the most important models for computer vision tasks. Although they outperform prior works, they require heavy computational resources on a scale that is quadratic to the number of tokens, $N$. This is a major drawback of the traditional self-attention (SA) algorithm. Here, we propose the X-ViT, ViT with a novel SA mechanism that has linear complexity. The main approach of this work is to eliminate nonlinearity from the original SA. We factorize the matrix multiplication of the SA mechanism without complicated linear approximation. By modifying only a few lines of code from the original SA, the proposed models outperform most transformer-based models on image classification and dense prediction tasks on most capacity regimes.
Proxyless Neural Architecture Adaptation for Supervised Learning and Self-Supervised Learning
May 15, 2022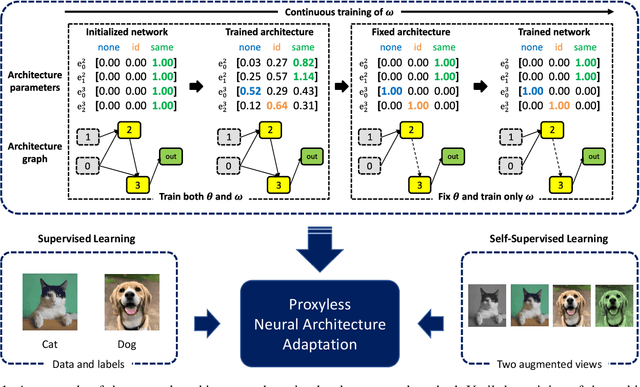
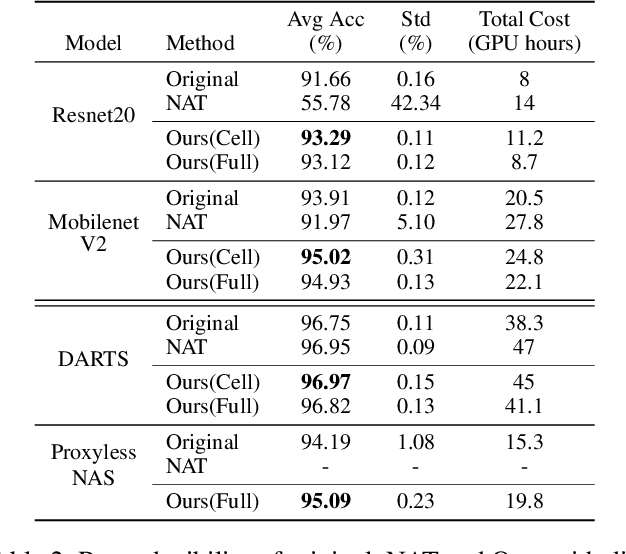
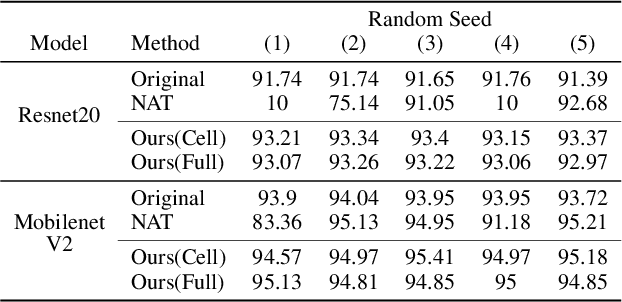
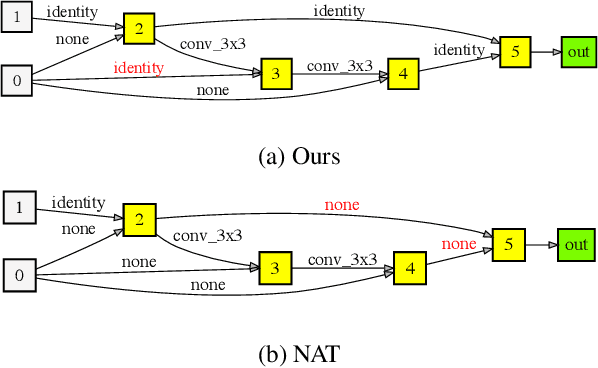
Recently, Neural Architecture Search (NAS) methods have been introduced and show impressive performance on many benchmarks. Among those NAS studies, Neural Architecture Transformer (NAT) aims to adapt the given neural architecture to improve performance while maintaining computational costs. However, NAT lacks reproducibility and it requires an additional architecture adaptation process before network weight training. In this paper, we propose proxyless neural architecture adaptation that is reproducible and efficient. Our method can be applied to both supervised learning and self-supervised learning. The proposed method shows stable performance on various architectures. Extensive reproducibility experiments on two datasets, i.e., CIFAR-10 and Tiny Imagenet, present that the proposed method definitely outperforms NAT and is applicable to other models and datasets.
SmoothMix: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness
Nov 17, 2021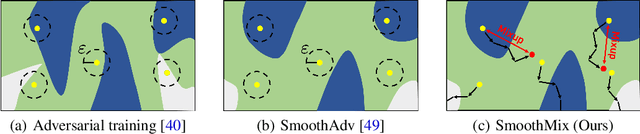

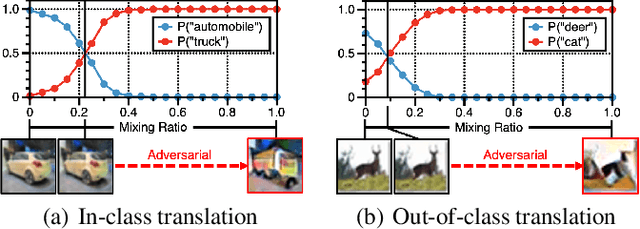
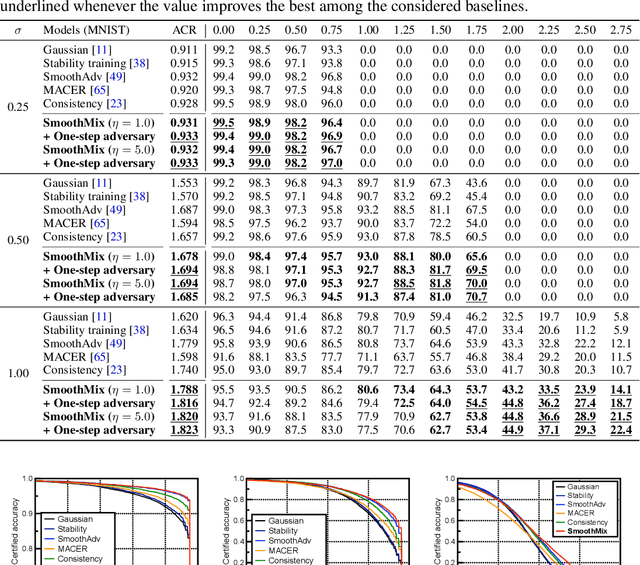
Randomized smoothing is currently a state-of-the-art method to construct a certifiably robust classifier from neural networks against $\ell_2$-adversarial perturbations. Under the paradigm, the robustness of a classifier is aligned with the prediction confidence, i.e., the higher confidence from a smoothed classifier implies the better robustness. This motivates us to rethink the fundamental trade-off between accuracy and robustness in terms of calibrating confidences of a smoothed classifier. In this paper, we propose a simple training scheme, coined SmoothMix, to control the robustness of smoothed classifiers via self-mixup: it trains on convex combinations of samples along the direction of adversarial perturbation for each input. The proposed procedure effectively identifies over-confident, near off-class samples as a cause of limited robustness in case of smoothed classifiers, and offers an intuitive way to adaptively set a new decision boundary between these samples for better robustness. Our experimental results demonstrate that the proposed method can significantly improve the certified $\ell_2$-robustness of smoothed classifiers compared to existing state-of-the-art robust training methods.
Differentiable Neural Architecture Transformation for Reproducible Architecture Improvement
Jun 15, 2020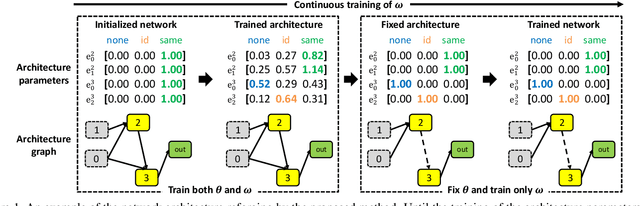
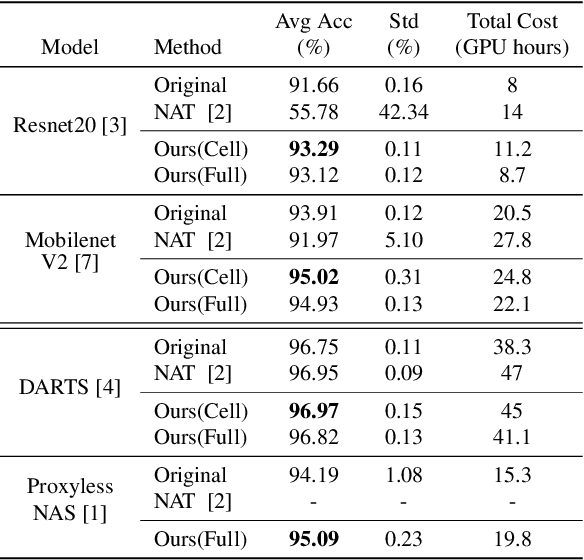
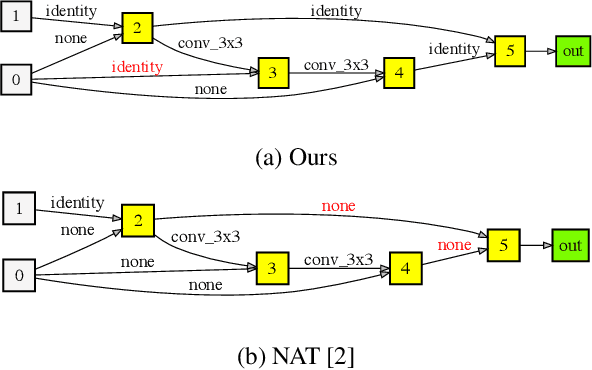
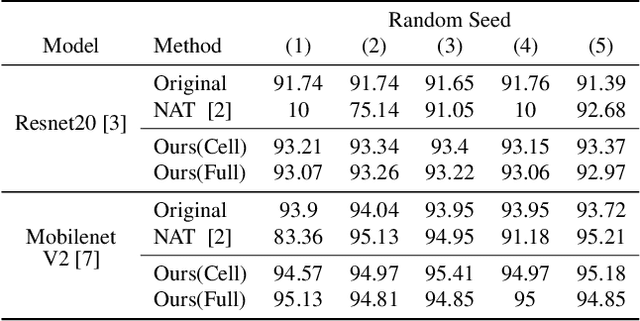
Recently, Neural Architecture Search (NAS) methods are introduced and show impressive performance on many benchmarks. Among those NAS studies, Neural Architecture Transformer (NAT) aims to improve the given neural architecture to have better performance while maintaining computational costs. However, NAT has limitations about a lack of reproducibility. In this paper, we propose differentiable neural architecture transformation that is reproducible and efficient. The proposed method shows stable performance on various architectures. Extensive reproducibility experiments on two datasets, i.e., CIFAR-10 and Tiny Imagenet, present that the proposed method definitely outperforms NAT and be applicable to other models and datasets.
Efficient Decoupled Neural Architecture Search by Structure and Operation Sampling
Oct 23, 2019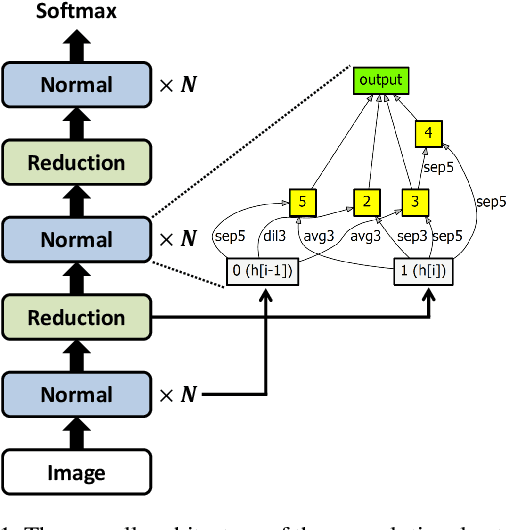



We propose a novel neural architecture search algorithm via reinforcement learning by decoupling structure and operation search processes. Our approach samples candidate models from the multinomial distribution on the policy vectors defined on the two search spaces independently. The proposed technique improves the efficiency of architecture search process significantly compared to the conventional methods based on reinforcement learning with the RNN controllers while achieving competitive accuracy and model size in target tasks. Our policy vectors are easily interpretable throughout the training procedure, which allows to analyze the search progress and the discovered architectures; the black-box characteristics of the RNN controllers hamper understanding training progress in terms of policy parameter updates. Our experiments demonstrate outstanding performance compared to the state-of-the-art methods with a fraction of search cost.