 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymBa: Symmetric Backpropagation-Free Contrastive Learning with Forward-Forward Algorithm for Optimizing Convergence
Mar 15, 2023The paper proposes a new algorithm called SymBa that aims to achieve more biologically plausible learning than Back-Propagation (BP). The algorithm is based on the Forward-Forward (FF) algorithm, which is a BP-free method for training neural networks. SymBa improves the FF algorithm's convergence behavior by addressing the problem of asymmetric gradients caused by conflicting converging directions for positive and negative samples. The algorithm balances positive and negative losses to enhance performance and convergence speed. Furthermore, it modifies the FF algorithm by adding Intrinsic Class Pattern (ICP) containing class information to prevent the loss of class information during training. The proposed algorithm has the potential to improve our understanding of how the brain learns and processes information and to develop more effective and efficient artificial intelligence systems. The paper presents experimental results that demonstrate the effectiveness of SymBa algorithm compared to the FF algorithm and BP.
X-ViT: High Performance Linear Vision Transformer without Softmax
May 27, 2022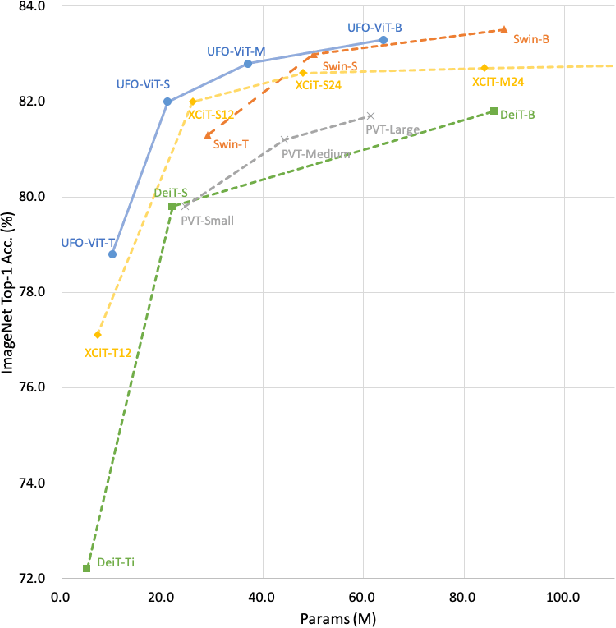



Vision transformers have become one of the most important models for computer vision tasks. Although they outperform prior works, they require heavy computational resources on a scale that is quadratic to the number of tokens, $N$. This is a major drawback of the traditional self-attention (SA) algorithm. Here, we propose the X-ViT, ViT with a novel SA mechanism that has linear complexity. The main approach of this work is to eliminate nonlinearity from the original SA. We factorize the matrix multiplication of the SA mechanism without complicated linear approximation. By modifying only a few lines of code from the original SA, the proposed models outperform most transformer-based models on image classification and dense prediction tasks on most capacity regimes.