 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-ViT: High Performance Linear Vision Transformer without Softmax
Paper and Code
May 27, 2022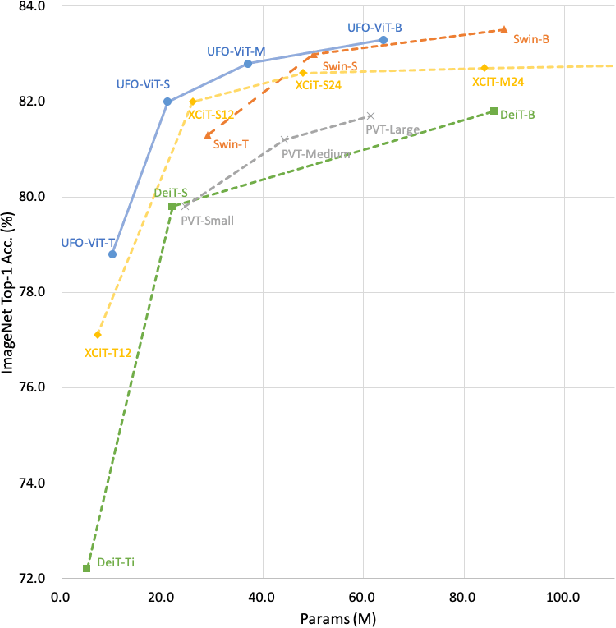



Vision transformers have become one of the most important models for computer vision tasks. Although they outperform prior works, they require heavy computational resources on a scale that is quadratic to the number of tokens, $N$. This is a major drawback of the traditional self-attention (SA) algorithm. Here, we propose the X-ViT, ViT with a novel SA mechanism that has linear complexity. The main approach of this work is to eliminate nonlinearity from the original SA. We factorize the matrix multiplication of the SA mechanism without complicated linear approximation. By modifying only a few lines of code from the original SA, the proposed models outperform most transformer-based models on image classification and dense prediction tasks on most capacity regimes.