 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCable Routing and Assembly using Tactile-driven Motion Primitives
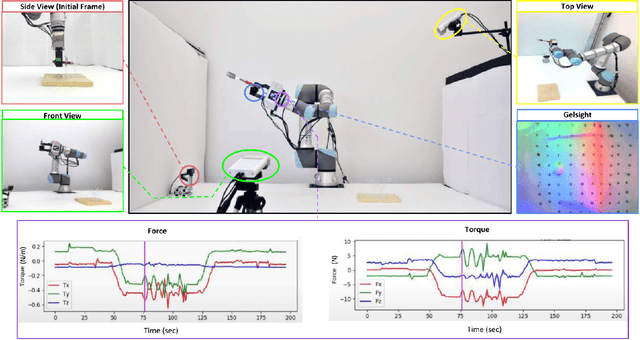
Mar 21, 2023Manipulating cables is challenging for robots because of the infinite degrees of freedom of the cables and frequent occlusion by the gripper and the environment. These challenges are further complicated by the dexterous nature of the operations required for cable routing and assembly, such as weaving and inserting, hampering common solutions with vision-only sensing. In this paper, we propose to integrate tactile-guided low-level motion control with high-level vision-based task parsing for a challenging task: cable routing and assembly on a reconfigurable task board. Specifically, we build a library of tactile-guided motion primitives using a fingertip GelSight sensor, where each primitive reliably accomplishes an operation such as cable following and weaving. The overall task is inferred via visual perception given a goal configuration image, and then used to generate the primitive sequence. Experiments demonstrate the effectiveness of individual tactile-guided primitives and the integrated end-to-end solution, significantly outperforming the method without tactile sensing. Our reconfigurable task setup and proposed baselines provide a benchmark for future research in cable manipulation. More details and video are presented in \url{https://helennn.github.io/cable-manip/}
PoseIt: A Visual-Tactile Dataset of Holding Poses for Grasp Stability Analysis
Sep 12, 2022


When humans grasp objects in the real world, we often move our arms to hold the object in a different pose where we can use it. In contrast, typical lab settings only study the stability of the grasp immediately after lifting, without any subsequent re-positioning of the arm. However, the grasp stability could vary widely based on the object's holding pose, as the gravitational torque and gripper contact forces could change completely. To facilitate the study of how holding poses affect grasp stability, we present PoseIt, a novel multi-modal dataset that contains visual and tactile data collected from a full cycle of grasping an object, re-positioning the arm to one of the sampled poses, and shaking the object. Using data from PoseIt, we can formulate and tackle the task of predicting whether a grasped object is stable in a particular held pose. We train an LSTM classifier that achieves 85% accuracy on the proposed task. Our experimental results show that multi-modal models trained on PoseIt achieve higher accuracy than using solely vision or tactile data and that our classifiers can also generalize to unseen objects and poses.
On Two XAI Cultures: A Case Study of Non-technical Explanations in Deployed AI System
Dec 02, 2021

Explainable AI (XAI) research has been booming, but the question "$\textbf{To whom}$ are we making AI explainable?" is yet to gain sufficient attention. Not much of XAI is comprehensible to non-AI experts, who nonetheless, are the primary audience and major stakeholders of deployed AI systems in practice. The gap is glaring: what is considered "explained" to AI-experts versus non-experts are very different in practical scenarios. Hence, this gap produced two distinct cultures of expectations, goals, and forms of XAI in real-life AI deployments. We advocate that it is critical to develop XAI methods for non-technical audiences. We then present a real-life case study, where AI experts provided non-technical explanations of AI decisions to non-technical stakeholders, and completed a successful deployment in a highly regulated industry. We then synthesize lessons learned from the case, and share a list of suggestions for AI experts to consider when explaining AI decisions to non-technical stakeholders.
Usable Security for ML Systems in Mental Health: A Framework
Aug 18, 2020

While the applications and demands of Machine learning (ML) systems in mental health are growing, there is little discussion nor consensus regarding a uniquely challenging aspect: building security methods and requirements into these ML systems, and keep the ML system usable for end-users. This question of usable security is very important, because the lack of consideration in either security or usability would hinder large-scale user adoption and active usage of ML systems in mental health applications. In this short paper, we introduce a framework of four pillars, and a set of desired properties which can be used to systematically guide and evaluate security-related designs, implementations, and deployments of ML systems for mental health. We aim to weave together threads from different domains, incorporate existing views, and propose new principles and requirements, in an effort to lay out a clear framework where criteria and expectations are established, and are used to make security mechanisms usable for end-users of those ML systems in mental health. Together with this framework, we present several concrete scenarios where different usable security cases and profiles in ML-systems in mental health applications are examined and evaluated.
Semantic Curiosity for Active Visual Learning
Jun 16, 2020



In this paper, we study the task of embodied interactive learning for object detection. Given a set of environments (and some labeling budget), our goal is to learn an object detector by having an agent select what data to obtain labels for. How should an exploration policy decide which trajectory should be labeled? One possibility is to use a trained object detector's failure cases as an external reward. However, this will require labeling millions of frames required for training RL policies, which is infeasible. Instead, we explore a self-supervised approach for training our exploration policy by introducing a notion of semantic curiosity. Our semantic curiosity policy is based on a simple observation -- the detection outputs should be consistent. Therefore, our semantic curiosity rewards trajectories with inconsistent labeling behavior and encourages the exploration policy to explore such areas. The exploration policy trained via semantic curiosity generalizes to novel scenes and helps train an object detector that outperforms baselines trained with other possible alternatives such as random exploration, prediction-error curiosity, and coverage-maximizing exploration.
Canonical Correlation Inference for Mapping Abstract Scenes to Text
Nov 17, 2017


We describe a technique for structured prediction, based on canonical correlation analysis. Our learning algorithm finds two projections for the input and the output spaces that aim at projecting a given input and its correct output into points close to each other. We demonstrate our technique on a language-vision problem, namely the problem of giving a textual description to an "abstract scene".