 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseIt: A Visual-Tactile Dataset of Holding Poses for Grasp Stability Analysis
Sep 12, 2022

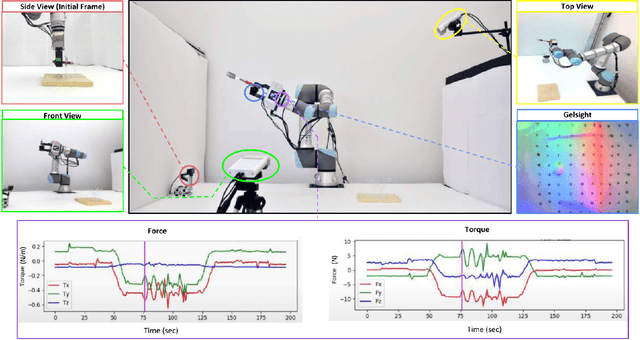

When humans grasp objects in the real world, we often move our arms to hold the object in a different pose where we can use it. In contrast, typical lab settings only study the stability of the grasp immediately after lifting, without any subsequent re-positioning of the arm. However, the grasp stability could vary widely based on the object's holding pose, as the gravitational torque and gripper contact forces could change completely. To facilitate the study of how holding poses affect grasp stability, we present PoseIt, a novel multi-modal dataset that contains visual and tactile data collected from a full cycle of grasping an object, re-positioning the arm to one of the sampled poses, and shaking the object. Using data from PoseIt, we can formulate and tackle the task of predicting whether a grasped object is stable in a particular held pose. We train an LSTM classifier that achieves 85% accuracy on the proposed task. Our experimental results show that multi-modal models trained on PoseIt achieve higher accuracy than using solely vision or tactile data and that our classifiers can also generalize to unseen objects and poses.