 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-specific Pre-training and Prompt Decomposition for Knowledge Graph Population with Language Models
Aug 31, 2022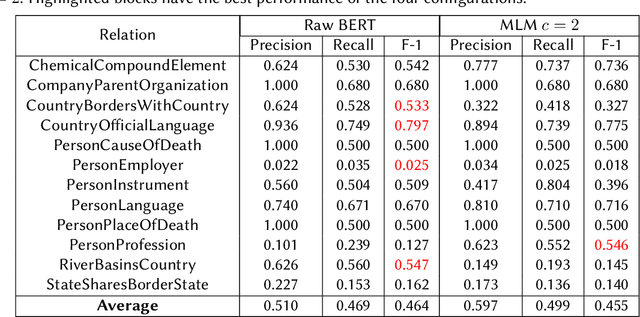
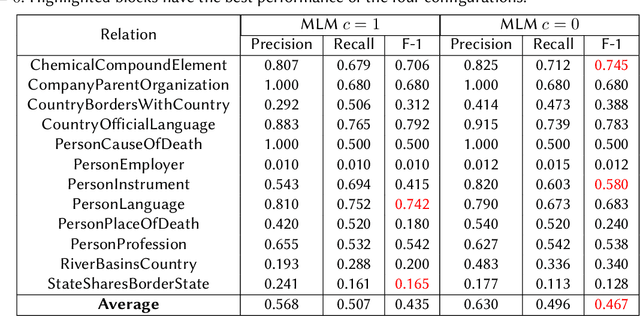
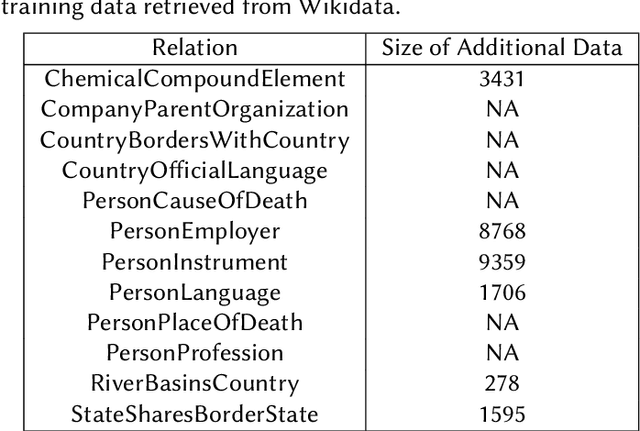
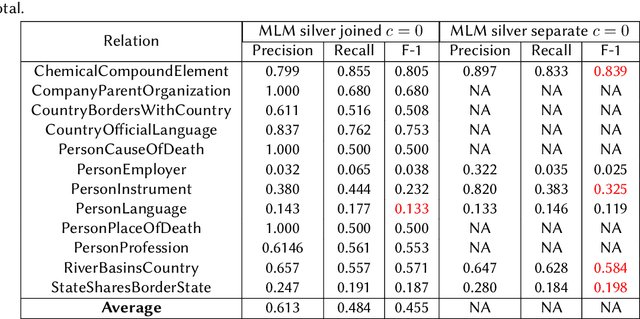
We present a system for knowledge graph population with Language Models, evaluated on the Knowledge Base Construction from Pre-trained Language Models (LM-KBC) challenge at ISWC 2022. Our system involves task-specific pre-training to improve LM representation of the masked object tokens, prompt decomposition for progressive generation of candidate objects, among other methods for higher-quality retrieval. Our system is the winner of track 1 of the LM-KBC challenge, based on BERT LM; it achieves 55.0% F-1 score on the hidden test set of the challenge.
Narration Generation for Cartoon Videos
Jan 17, 2021
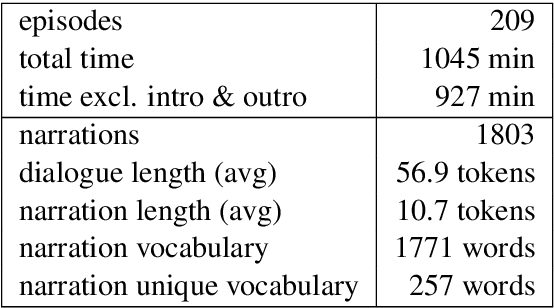
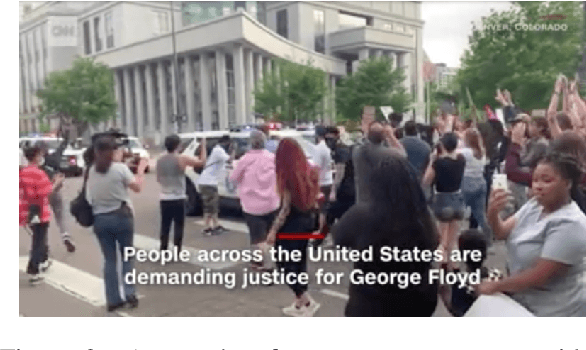
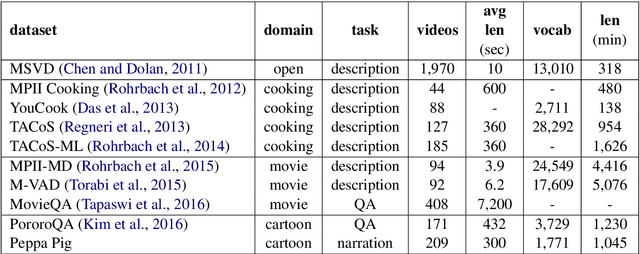
Research on text generation from multimodal inputs has largely focused on static images, and less on video data. In this paper, we propose a new task, narration generation, that is complementing videos with narration texts that are to be interjected in several places. The narrations are part of the video and contribute to the storyline unfolding in it. Moreover, they are context-informed, since they include information appropriate for the timeframe of video they cover, and also, do not need to include every detail shown in input scenes, as a caption would. We collect a new dataset from the animated television series Peppa Pig. Furthermore, we formalize the task of narration generation as including two separate tasks, timing and content generation, and present a set of models on the new task.
Canonical Correlation Inference for Mapping Abstract Scenes to Text
Nov 17, 2017

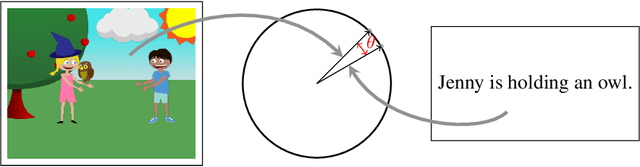

We describe a technique for structured prediction, based on canonical correlation analysis. Our learning algorithm finds two projections for the input and the output spaces that aim at projecting a given input and its correct output into points close to each other. We demonstrate our technique on a language-vision problem, namely the problem of giving a textual description to an "abstract scene".