Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-specific Pre-training and Prompt Decomposition for Knowledge Graph Population with Language Models
Paper and Code
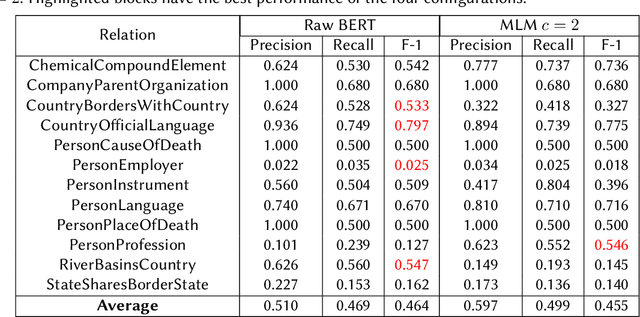
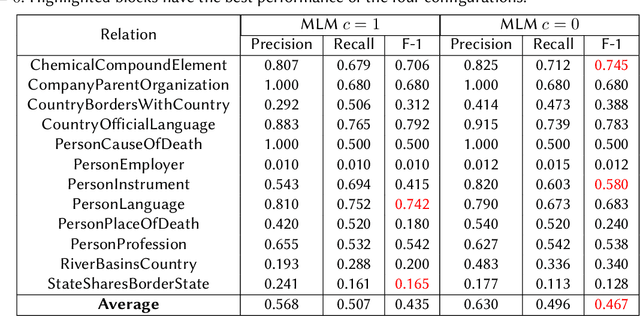
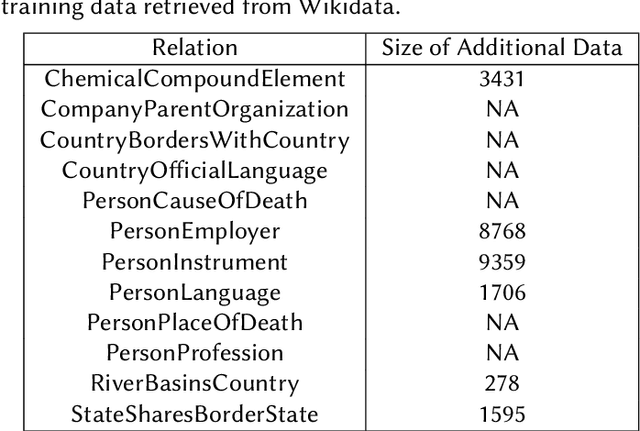
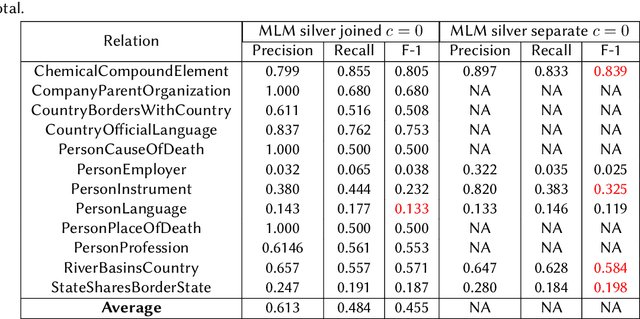
We present a system for knowledge graph population with Language Models, evaluated on the Knowledge Base Construction from Pre-trained Language Models (LM-KBC) challenge at ISWC 2022. Our system involves task-specific pre-training to improve LM representation of the masked object tokens, prompt decomposition for progressive generation of candidate objects, among other methods for higher-quality retrieval. Our system is the winner of track 1 of the LM-KBC challenge, based on BERT LM; it achieves 55.0% F-1 score on the hidden test set of the challenge.
* To appear in ISWC 2022
View paper on