 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarration Generation for Cartoon Videos
Paper and Code

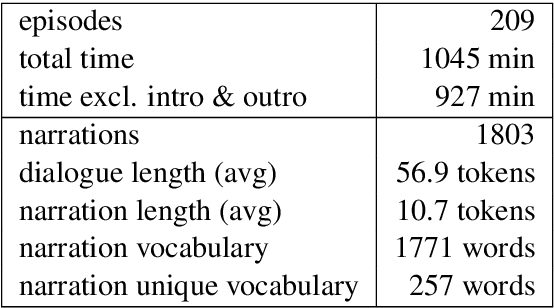
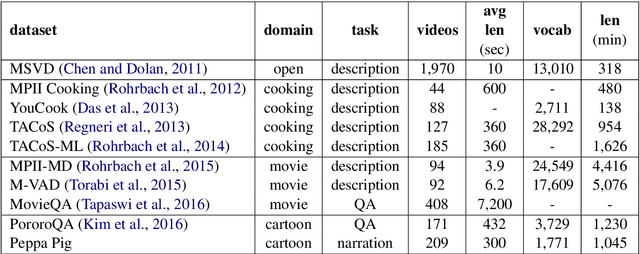
Research on text generation from multimodal inputs has largely focused on static images, and less on video data. In this paper, we propose a new task, narration generation, that is complementing videos with narration texts that are to be interjected in several places. The narrations are part of the video and contribute to the storyline unfolding in it. Moreover, they are context-informed, since they include information appropriate for the timeframe of video they cover, and also, do not need to include every detail shown in input scenes, as a caption would. We collect a new dataset from the animated television series Peppa Pig. Furthermore, we formalize the task of narration generation as including two separate tasks, timing and content generation, and present a set of models on the new task.