 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Information Fusion For The Diagnosis Of Diabetic Retinopathy
Mar 20, 2023


Diabetes is a chronic disease characterized by excess sugar in the blood and affects 422 million people worldwide, including 3.3 million in France. One of the frequent complications of diabetes is diabetic retinopathy (DR): it is the leading cause of blindness in the working population of developed countries. As a result, ophthalmology is on the verge of a revolution in screening, diagnosing, and managing of pathologies. This upheaval is led by the arrival of technologies based on artificial intelligence. The "Evaluation intelligente de la r\'etinopathie diab\'etique" (EviRed) project uses artificial intelligence to answer a medical need: replacing the current classification of diabetic retinopathy which is mainly based on outdated fundus photography and providing an insufficient prediction precision. EviRed exploits modern fundus imaging devices and artificial intelligence to properly integrate the vast amount of data they provide with other available medical data of the patient. The goal is to improve diagnosis and prediction and help ophthalmologists to make better decisions during diabetic retinopathy follow-up. In this study, we investigate the fusion of different modalities acquired simultaneously with a PLEXElite 9000 (Carl Zeiss Meditec Inc. Dublin, California, USA), namely 3-D structural optical coherence tomography (OCT), 3-D OCT angiography (OCTA) and 2-D Line Scanning Ophthalmoscope (LSO), for the automatic detection of proliferative DR.
Multimodal Information Fusion for Glaucoma and DR Classification
Sep 05, 2022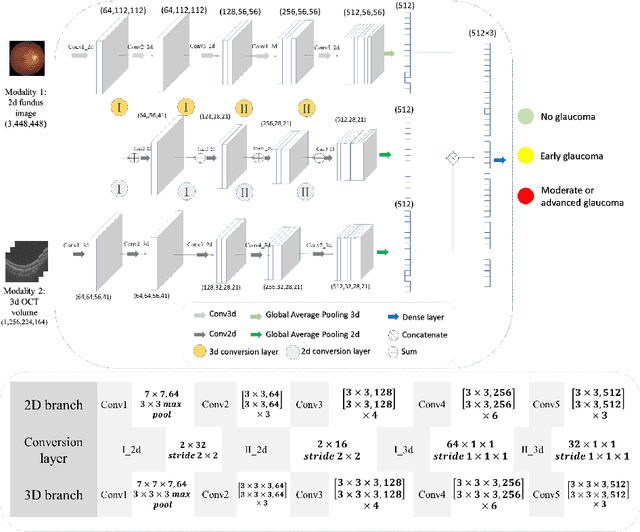
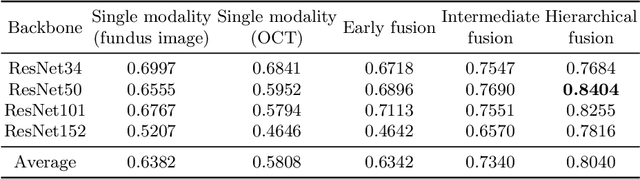
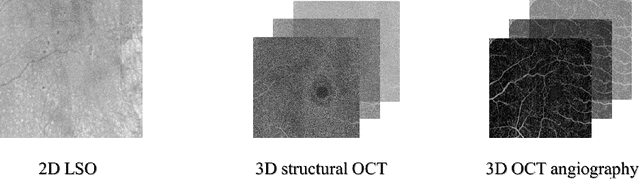
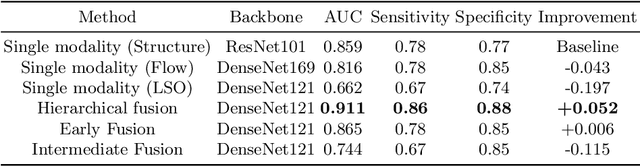
Multimodal information is frequently available in medical tasks. By combining information from multiple sources, clinicians are able to make more accurate judgments. In recent years, multiple imaging techniques have been used in clinical practice for retinal analysis: 2D fundus photographs, 3D optical coherence tomography (OCT) and 3D OCT angiography, etc. Our paper investigates three multimodal information fusion strategies based on deep learning to solve retinal analysis tasks: early fusion, intermediate fusion, and hierarchical fusion. The commonly used early and intermediate fusions are simple but do not fully exploit the complementary information between modalities. We developed a hierarchical fusion approach that focuses on combining features across multiple dimensions of the network, as well as exploring the correlation between modalities. These approaches were applied to glaucoma and diabetic retinopathy classification, using the public GAMMA dataset (fundus photographs and OCT) and a private dataset of PlexElite 9000 (Carl Zeis Meditec Inc.) OCT angiography acquisitions, respectively. Our hierarchical fusion method performed the best in both cases and paved the way for better clinical diagnosis.
ExplAIn: Explanatory Artificial Intelligence for Diabetic Retinopathy Diagnosis
Sep 01, 2020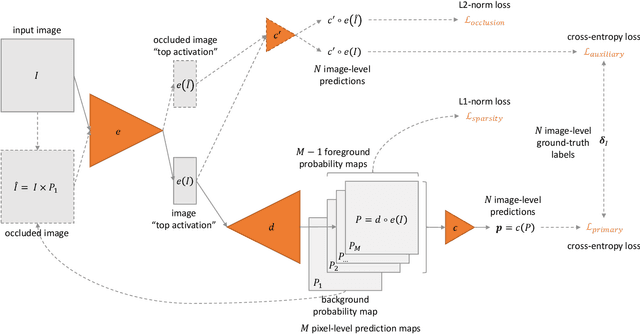
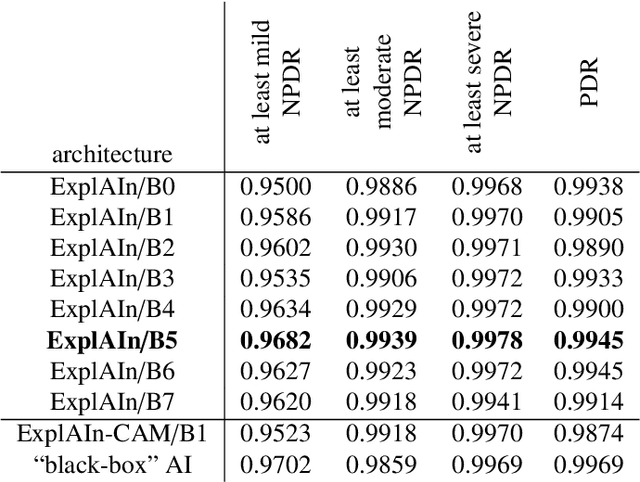
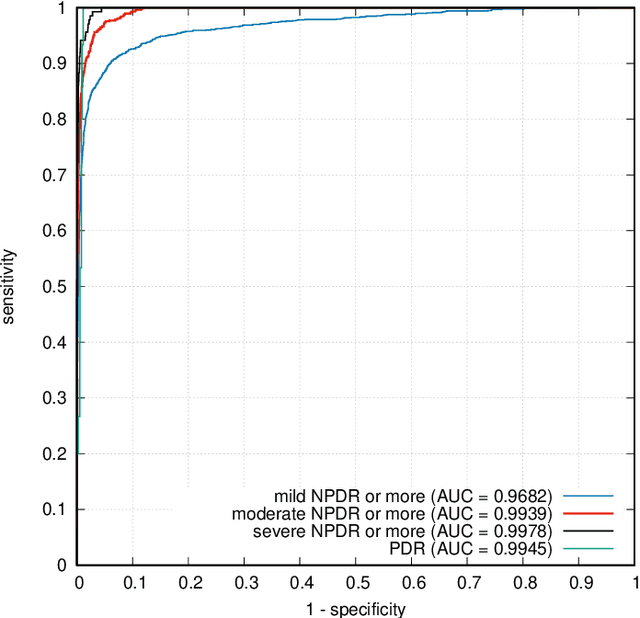
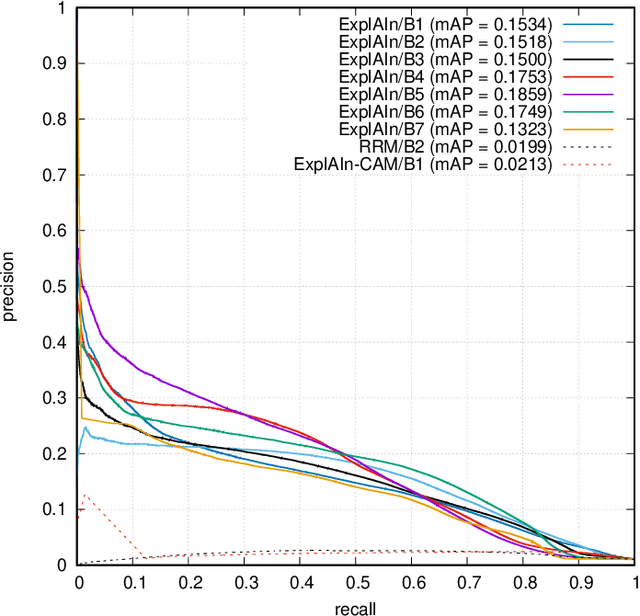
In recent years, Artificial Intelligence (AI) has proven its relevance for medical decision support. However, the "black-box" nature of successful AI algorithms still holds back their wide-spread deployment. In this paper, we describe an eXplanatory Artificial Intelligence (XAI) that reaches the same level of performance as black-box AI, for the task of classifying Diabetic Retinopathy (DR) severity using Color Fundus Photography (CFP). This algorithm, called ExplAIn, learns to segment and categorize lesions in images; the final image-level classification directly derives from these multivariate lesion segmentations. The novelty of this explanatory framework is that it is trained from end to end, with image supervision only, just like black-box AI algorithms: the concepts of lesions and lesion categories emerge by themselves. For improved lesion localization, foreground/background separation is trained through self-supervision, in such a way that occluding foreground pixels transforms the input image into a healthy-looking image. The advantage of such an architecture is that automatic diagnoses can be explained simply by an image and/or a few sentences. ExplAIn is evaluated at the image level and at the pixel level on various CFP image datasets. We expect this new framework, which jointly offers high classification performance and explainability, to facilitate AI deployment.
Monitoring tool usage in surgery videos using boosted convolutional and recurrent neural networks
May 06, 2018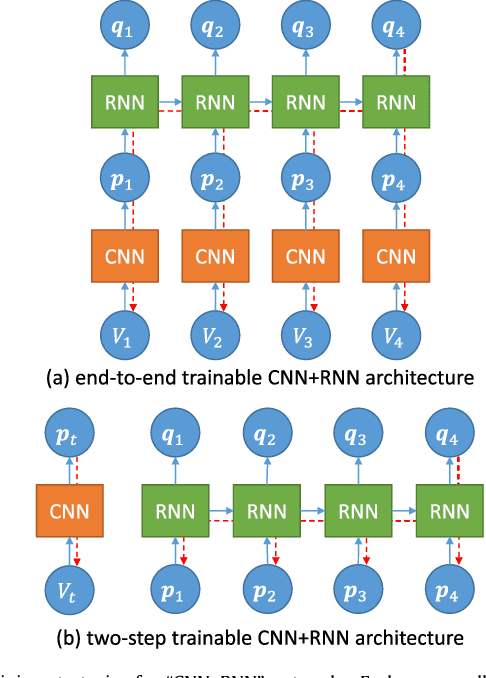
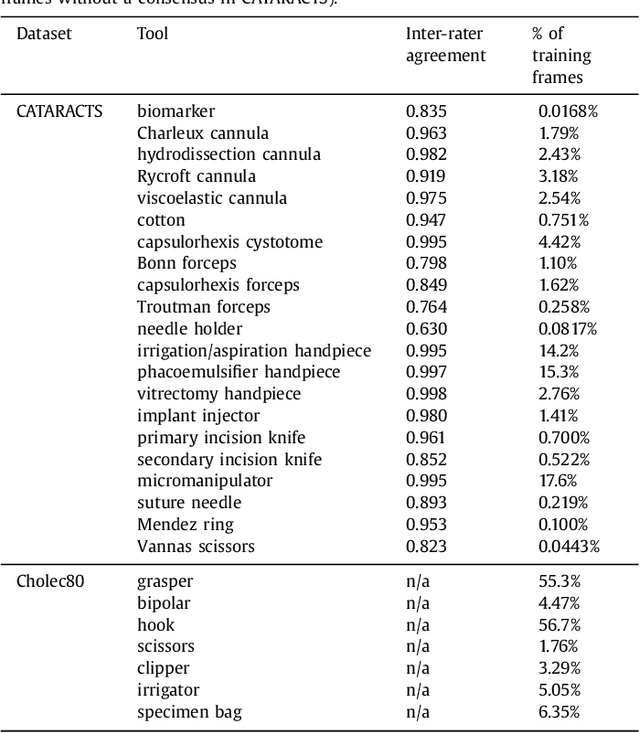


This paper investigates the automatic monitoring of tool usage during a surgery, with potential applications in report generation, surgical training and real-time decision support. Two surgeries are considered: cataract surgery, the most common surgical procedure, and cholecystectomy, one of the most common digestive surgeries. Tool usage is monitored in videos recorded either through a microscope (cataract surgery) or an endoscope (cholecystectomy). Following state-of-the-art video analysis solutions, each frame of the video is analyzed by convolutional neural networks (CNNs) whose outputs are fed to recurrent neural networks (RNNs) in order to take temporal relationships between events into account. Novelty lies in the way those CNNs and RNNs are trained. Computational complexity prevents the end-to-end training of "CNN+RNN" systems. Therefore, CNNs are usually trained first, independently from the RNNs. This approach is clearly suboptimal for surgical tool analysis: many tools are very similar to one another, but they can generally be differentiated based on past events. CNNs should be trained to extract the most useful visual features in combination with the temporal context. A novel boosting strategy is proposed to achieve this goal: the CNN and RNN parts of the system are simultaneously enriched by progressively adding weak classifiers (either CNNs or RNNs) trained to improve the overall classification accuracy. Experiments were performed in a dataset of 50 cataract surgery videos and a dataset of 80 cholecystectomy videos. Very good classification performance are achieved in both datasets: tool usage could be labeled with an average area under the ROC curve of $A_z = 0.9961$ and $A_z = 0.9939$, respectively, in offline mode (using past, present and future information), and $A_z = 0.9957$ and $A_z = 0.9936$, respectively, in online mode (using past and present information only).
Coarse-to-fine Surgical Instrument Detection for Cataract Surgery Monitoring
Sep 19, 2016
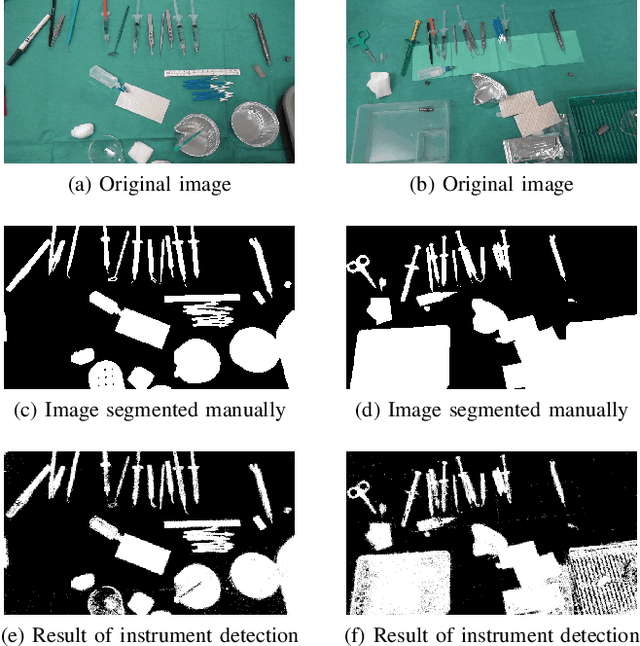

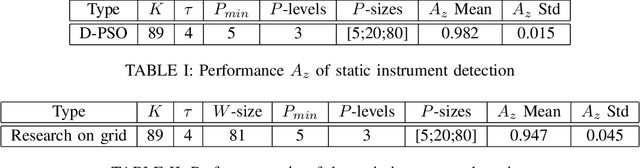
The amount of surgical data, recorded during video-monitored surgeries, has extremely increased. This paper aims at improving existing solutions for the automated analysis of cataract surgeries in real time. Through the analysis of a video recording the operating table, it is possible to know which instruments exit or enter the operating table, and therefore which ones are likely being used by the surgeon. Combining these observations with observations from the microscope video should enhance the overall performance of the systems. To this end, the proposed solution is divided into two main parts: one to detect the instruments at the beginning of the surgery and one to update the list of instruments every time a change is detected in the scene. In the first part, the goal is to separate the instruments from the background and from irrelevant objects. For the second, we are interested in detecting the instruments that appear and disappear whenever the surgeon interacts with the table. Experiments on a dataset of 36 cataract surgeries validate the good performance of the proposed solution.