 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Information Fusion for Glaucoma and DR Classification
Paper and Code
Sep 05, 2022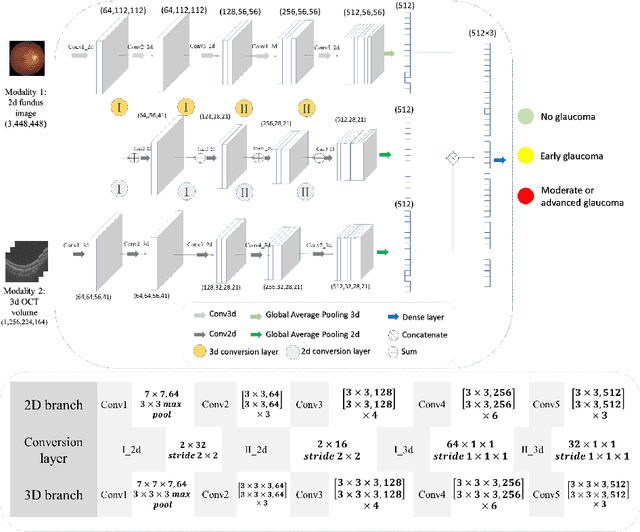
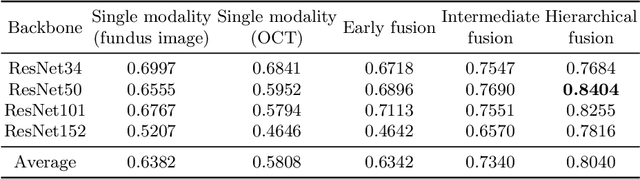
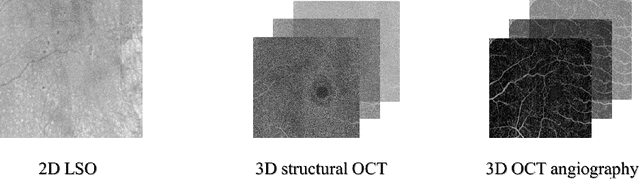
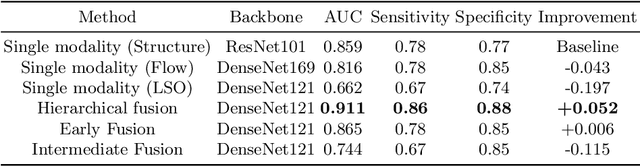
Multimodal information is frequently available in medical tasks. By combining information from multiple sources, clinicians are able to make more accurate judgments. In recent years, multiple imaging techniques have been used in clinical practice for retinal analysis: 2D fundus photographs, 3D optical coherence tomography (OCT) and 3D OCT angiography, etc. Our paper investigates three multimodal information fusion strategies based on deep learning to solve retinal analysis tasks: early fusion, intermediate fusion, and hierarchical fusion. The commonly used early and intermediate fusions are simple but do not fully exploit the complementary information between modalities. We developed a hierarchical fusion approach that focuses on combining features across multiple dimensions of the network, as well as exploring the correlation between modalities. These approaches were applied to glaucoma and diabetic retinopathy classification, using the public GAMMA dataset (fundus photographs and OCT) and a private dataset of PlexElite 9000 (Carl Zeis Meditec Inc.) OCT angiography acquisitions, respectively. Our hierarchical fusion method performed the best in both cases and paved the way for better clinical diagnosis.