 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull reference point cloud quality assessment using support vector regression
Jun 15, 2024



Point clouds are a general format for representing realistic 3D objects in diverse 3D applications. Since point clouds have large data sizes, developing efficient point cloud compression methods is crucial. However, excessive compression leads to various distortions, which deteriorates the point cloud quality perceived by end users. Thus, establishing reliable point cloud quality assessment (PCQA) methods is essential as a benchmark to develop efficient compression methods. This paper presents an accurate full-reference point cloud quality assessment (FR-PCQA) method called full-reference quality assessment using support vector regression (FRSVR) for various types of degradations such as compression distortion, Gaussian noise, and down-sampling. The proposed method demonstrates accurate PCQA by integrating five FR-based metrics covering various types of errors (e.g., considering geometric distortion, color distortion, and point count) using support vector regression (SVR). Moreover, the proposed method achieves a superior trade-off between accuracy and calculation speed because it includes only the calculation of these five simple metrics and SVR, which can perform fast prediction. Experimental results with three types of open datasets show that the proposed method is more accurate than conventional FR-PCQA methods. In addition, the proposed method is faster than state-of-the-art methods that utilize complicated features such as curvature and multi-scale features. Thus, the proposed method provides excellent performance in terms of the accuracy of PCQA and processing speed. Our method is available from https://github.com/STAC-USC/FRSVR-PCQA.
Motion estimation and filtered prediction for dynamic point cloud attribute compression
Oct 15, 2022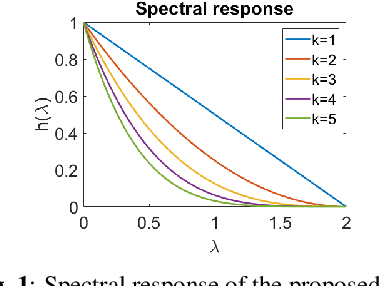
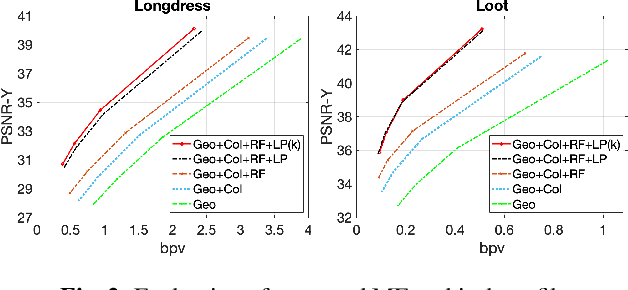

In point cloud compression, exploiting temporal redundancy for inter predictive coding is challenging because of the irregular geometry. This paper proposes an efficient block-based inter-coding scheme for color attribute compression. The scheme includes integer-precision motion estimation and an adaptive graph based in-loop filtering scheme for improved attribute prediction. The proposed block-based motion estimation scheme consists of an initial motion search that exploits geometric and color attributes, followed by a motion refinement that only minimizes color prediction error. To further improve color prediction, we propose a vertex-domain low-pass graph filtering scheme that can adaptively remove noise from predictors computed from motion estimation with different accuracy. Our experiments demonstrate significant coding gain over state-of-the-art coding methods.
Fractional Motion Estimation for Point Cloud Compression
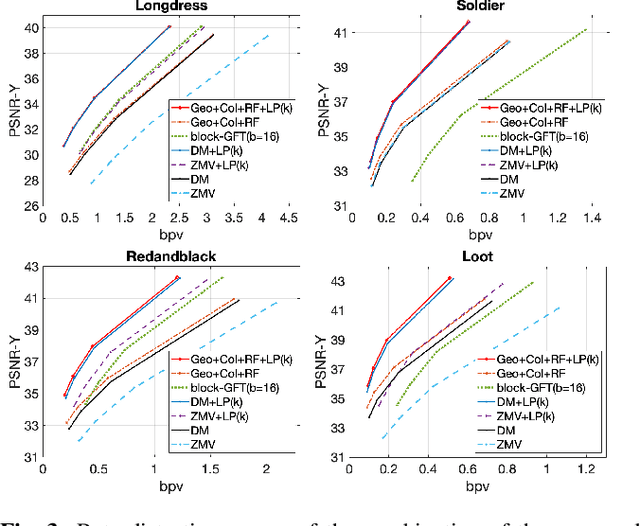
Feb 01, 2022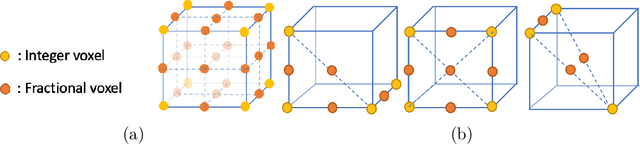
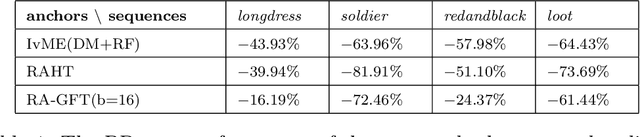

Motivated by the success of fractional pixel motion in video coding, we explore the design of motion estimation with fractional-voxel resolution for compression of color attributes of dynamic 3D point clouds. Our proposed block-based fractional-voxel motion estimation scheme takes into account the fundamental differences between point clouds and videos, i.e., the irregularity of the distribution of voxels within a frame and across frames. We show that motion compensation can benefit from the higher resolution reference and more accurate displacements provided by fractional precision. Our proposed scheme significantly outperforms comparable methods that only use integer motion. The proposed scheme can be combined with and add sizeable gains to state-of-the-art systems that use transforms such as Region Adaptive Graph Fourier Transform and Region Adaptive Haar Transform.
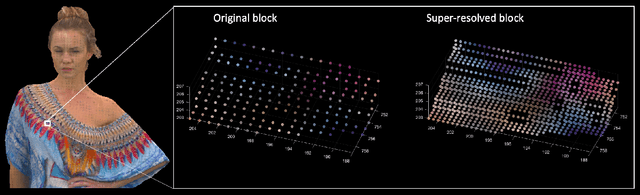
Pre-demosaic Graph-based Light Field Image Compression
Feb 15, 2021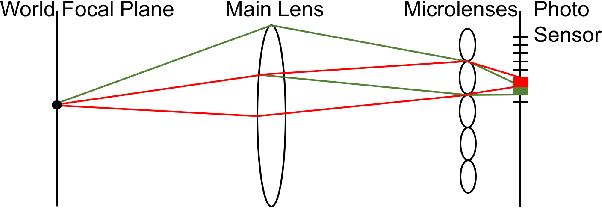

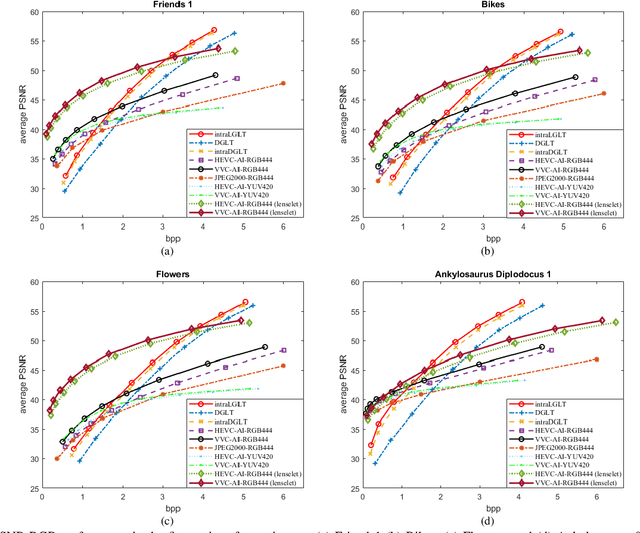
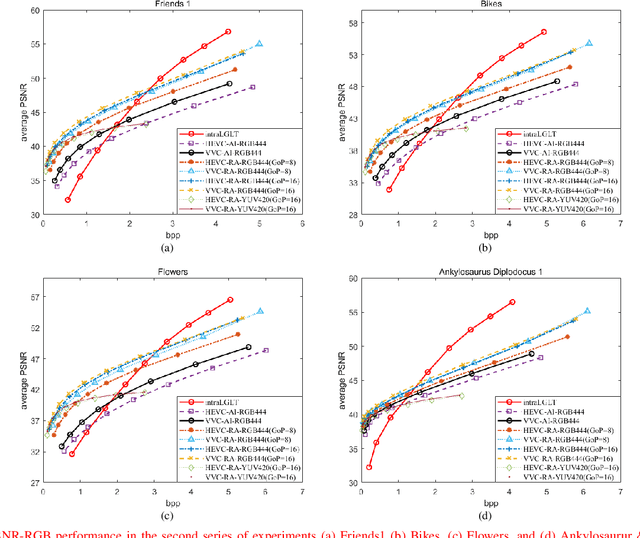
A plenoptic light field (LF) camera places an array of microlenses in front of an image sensor in order to separately capture different directional rays arriving at an image pixel. Using a conventional Bayer pattern, data captured at each pixel is a single color component (R, G or B). The sensed data then undergoes demosaicking (interpolation of RGB components per pixel) and conversion to an array of sub-aperture images (SAIs). In this paper, we propose a new LF image coding scheme based on graph lifting transform (GLT), where the acquired sensor data are coded in the original captured form without pre-processing. Specifically, we directly map raw sensed color data to the SAIs, resulting in sparsely distributed color pixels on 2D grids, and perform demosaicking at the receiver after decoding. To exploit spatial correlation among the sparse pixels, we propose a novel intra-prediction scheme, where the prediction kernel is determined according to the local gradient estimated from already coded neighboring pixel blocks. We then connect the pixels by forming a graph, modeling the prediction residuals statistically as a Gaussian Markov Random Field (GMRF). The optimal edge weights are computed via a graph learning method using a set of training SAIs. The residual data is encoded via low-complexity GLT. Experiments show that at high PSNRs -- important for archiving and instant storage scenarios -- our method outperformed significantly a conventional light field image coding scheme with demosaicking followed by High Efficiency Video Coding (HEVC).