 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Tree: Aligning Text Representation to the Label Tree Hierarchy for Imbalanced Medical Classification
Nov 28, 2023Deep learning approaches exhibit promising performances on various text tasks. However, they are still struggling on medical text classification since samples are often extremely imbalanced and scarce. Different from existing mainstream approaches that focus on supplementary semantics with external medical information, this paper aims to rethink the data challenges in medical texts and present a novel framework-agnostic algorithm called Text2Tree that only utilizes internal label hierarchy in training deep learning models. We embed the ICD code tree structure of labels into cascade attention modules for learning hierarchy-aware label representations. Two new learning schemes, Similarity Surrogate Learning (SSL) and Dissimilarity Mixup Learning (DML), are devised to boost text classification by reusing and distinguishing samples of other labels following the label representation hierarchy, respectively. Experiments on authoritative public datasets and real-world medical records show that our approach stably achieves superior performances over classical and advanced imbalanced classification methods.
Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022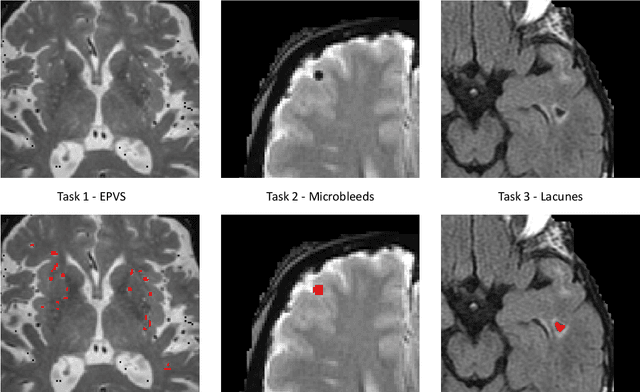
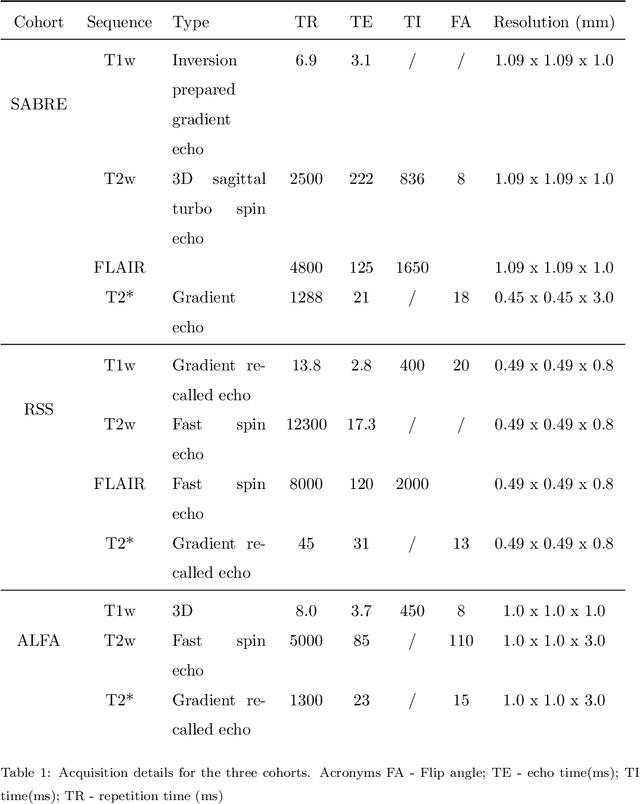
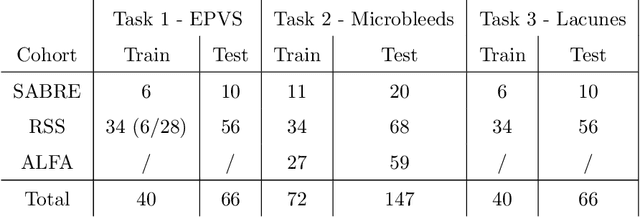
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.