 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelivering Arbitrary-Modal Semantic Segmentation
Mar 02, 2023



Multimodal fusion can make semantic segmentation more robust. However, fusing an arbitrary number of modalities remains underexplored. To delve into this problem, we create the DeLiVER arbitrary-modal segmentation benchmark, covering Depth, LiDAR, multiple Views, Events, and RGB. Aside from this, we provide this dataset in four severe weather conditions as well as five sensor failure cases to exploit modal complementarity and resolve partial outages. To make this possible, we present the arbitrary cross-modal segmentation model CMNeXt. It encompasses a Self-Query Hub (SQ-Hub) designed to extract effective information from any modality for subsequent fusion with the RGB representation and adds only negligible amounts of parameters (~0.01M) per additional modality. On top, to efficiently and flexibly harvest discriminative cues from the auxiliary modalities, we introduce the simple Parallel Pooling Mixer (PPX). With extensive experiments on a total of six benchmarks, our CMNeXt achieves state-of-the-art performance on the DeLiVER, KITTI-360, MFNet, NYU Depth V2, UrbanLF, and MCubeS datasets, allowing to scale from 1 to 81 modalities. On the freshly collected DeLiVER, the quad-modal CMNeXt reaches up to 66.30% in mIoU with a +9.10% gain as compared to the mono-modal baseline. The DeLiVER dataset and our code are at: https://jamycheung.github.io/DELIVER.html.
Behind Every Domain There is a Shift: Adapting Distortion-aware Vision Transformers for Panoramic Semantic Segmentation
Jul 27, 2022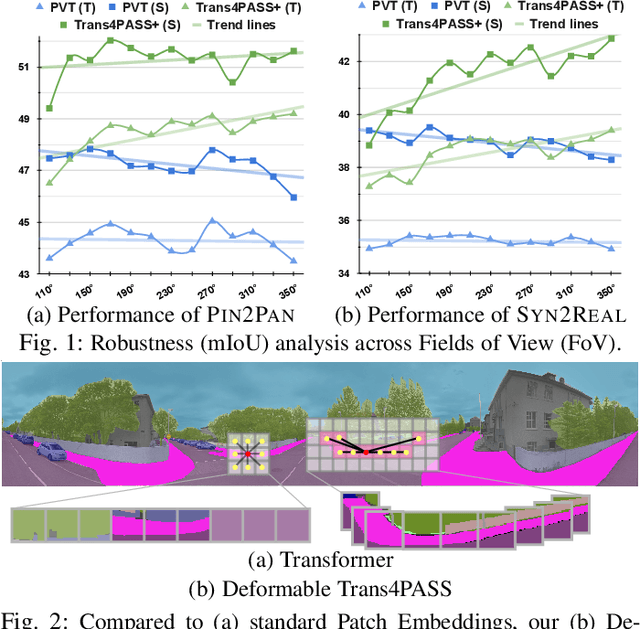
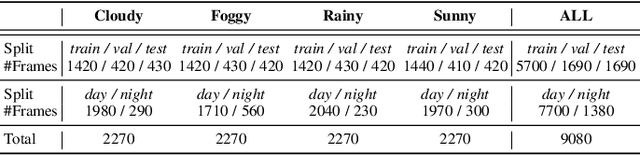
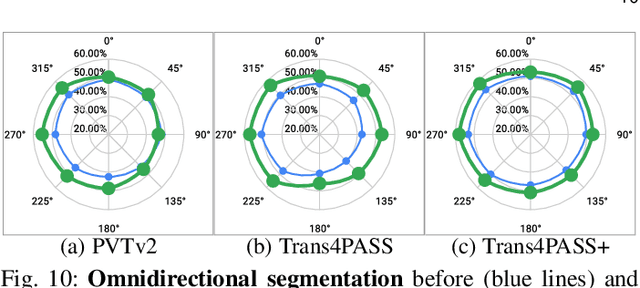

In this paper, we address panoramic semantic segmentation, which provides a full-view and dense-pixel understanding of surroundings in a holistic way. Panoramic segmentation is under-explored due to two critical challenges: (1) image distortions and object deformations on panoramas; (2) lack of annotations for training panoramic segmenters. To tackle these problems, we propose a Transformer for Panoramic Semantic Segmentation (Trans4PASS) architecture. First, to enhance distortion awareness, Trans4PASS, equipped with Deformable Patch Embedding (DPE) and Deformable MLP (DMLP) modules, is capable of handling object deformations and image distortions whenever (before or after adaptation) and wherever (shallow or deep levels) by design. We further introduce the upgraded Trans4PASS+ model, featuring DMLPv2 with parallel token mixing to improve the flexibility and generalizability in modeling discriminative cues. Second, we propose a Mutual Prototypical Adaptation (MPA) strategy for unsupervised domain adaptation. Third, aside from Pinhole-to-Panoramic (Pin2Pan) adaptation, we create a new dataset (SynPASS) with 9,080 panoramic images to explore a Synthetic-to-Real (Syn2Real) adaptation scheme in 360{\deg} imagery. Extensive experiments are conducted, which cover indoor and outdoor scenarios, and each of them is investigated with Pin2Pan and Syn2Real regimens. Trans4PASS+ achieves state-of-the-art performances on four domain adaptive panoramic semantic segmentation benchmarks. Code is available at https://github.com/jamycheung/Trans4PASS.