 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Sampling Reinforcement Learning with Gaussian Processes for Continuous Control: Sublinear Regret Bounds for Unbounded State Spaces
Mar 09, 2026We analyze the Bayesian regret of the Gaussian process posterior sampling reinforcement learning (GP-PSRL) algorithm. Posterior sampling is an effective heuristic for decision-making under uncertainty that has been used to develop successful algorithms for a variety of continuous control problems. However, theoretical work on GP-PSRL is limited. All known regret bounds either fail to achieve a tight dependence on a kernel-dependent quantity called the maximum information gain or fail to properly account for the fact that the set of possible system states is unbounded. Through a recursive application of the Borell-Tsirelson-Ibragimov-Sudakov inequality, we show that, with high probability, the states actually visited by the algorithm are contained within a ball of near-constant radius. To obtain tight dependence on the maximum information gain, we use the chaining method to control the regret suffered by GP-PSRL. Our main result is a Bayesian regret bound of the order $\widetilde{\mathcal{O}}(H^{3/2}\sqrt{γ_{T/H} T})$, where $H$ is the horizon, $T$ is the number of time steps and $γ_{T/H}$ is the maximum information gain. With this result, we resolve the limitations with prior theoretical work on PSRL, and provide the theoretical foundation and tools for analyzing PSRL in complex settings.
Relative Information Gain and Gaussian Process Regression
Oct 05, 2025The sample complexity of estimating or maximising an unknown function in a reproducing kernel Hilbert space is known to be linked to both the effective dimension and the information gain associated with the kernel. While the information gain has an attractive information-theoretic interpretation, the effective dimension typically results in better rates. We introduce a new quantity called the relative information gain, which measures the sensitivity of the information gain with respect to the observation noise. We show that the relative information gain smoothly interpolates between the effective dimension and the information gain, and that the relative information gain has the same growth rate as the effective dimension. In the second half of the paper, we prove a new PAC-Bayesian excess risk bound for Gaussian process regression. The relative information gain arises naturally from the complexity term in this PAC-Bayesian bound. We prove bounds on the relative information gain that depend on the spectral properties of the kernel. When these upper bounds are combined with our excess risk bound, we obtain minimax-optimal rates of convergence.
Linear Bandits with Non-i.i.d. Noise
May 26, 2025We study the linear stochastic bandit problem, relaxing the standard i.i.d. assumption on the observation noise. As an alternative to this restrictive assumption, we allow the noise terms across rounds to be sub-Gaussian but interdependent, with dependencies that decay over time. To address this setting, we develop new confidence sequences using a recently introduced reduction scheme to sequential probability assignment, and use these to derive a bandit algorithm based on the principle of optimism in the face of uncertainty. We provide regret bounds for the resulting algorithm, expressed in terms of the decay rate of the strength of dependence between observations. Among other results, we show that our bounds recover the standard rates up to a factor of the mixing time for geometrically mixing observation noise.
Confidence Sequences for Generalized Linear Models via Regret Analysis
Apr 23, 2025We develop a methodology for constructing confidence sets for parameters of statistical models via a reduction to sequential prediction. Our key observation is that for any generalized linear model (GLM), one can construct an associated game of sequential probability assignment such that achieving low regret in the game implies a high-probability upper bound on the excess likelihood of the true parameter of the GLM. This allows us to develop a scheme that we call online-to-confidence-set conversions, which effectively reduces the problem of proving the desired statistical claim to an algorithmic question. We study two varieties of this conversion scheme: 1) analytical conversions that only require proving the existence of algorithms with low regret and provide confidence sets centered at the maximum-likelihood estimator 2) algorithmic conversions that actively leverage the output of the online algorithm to construct confidence sets (and may be centered at other, adaptively constructed point estimators). The resulting methodology recovers all state-of-the-art confidence set constructions within a single framework, and also provides several new types of confidence sets that were previously unknown in the literature.
Sparse Nonparametric Contextual Bandits
Mar 20, 2025This paper studies the problem of simultaneously learning relevant features and minimising regret in contextual bandit problems. We introduce and analyse a new class of contextual bandit problems, called sparse nonparametric contextual bandits, in which the expected reward function lies in the linear span of a small unknown set of features that belongs to a known infinite set of candidate features. We consider two notions of sparsity, for which the set of candidate features is either countable or uncountable. Our contribution is two-fold. First, we provide lower bounds on the minimax regret, which show that polynomial dependence on the number of actions is generally unavoidable in this setting. Second, we show that a variant of the Feel-Good Thompson Sampling algorithm enjoys regret bounds that match our lower bounds up to logarithmic factors of the horizon, and have logarithmic dependence on the effective number of candidate features. When we apply our results to kernelised and neural contextual bandits, we find that sparsity always enables better regret bounds, as long as the horizon is large enough relative to the sparsity and the number of actions.
Tighter Confidence Bounds for Sequential Kernel Regression
Mar 19, 2024Confidence bounds are an essential tool for rigorously quantifying the uncertainty of predictions. In this capacity, they can inform the exploration-exploitation trade-off and form a core component in many sequential learning and decision-making algorithms. Tighter confidence bounds give rise to algorithms with better empirical performance and better performance guarantees. In this work, we use martingale tail bounds and finite-dimensional reformulations of infinite-dimensional convex programs to establish new confidence bounds for sequential kernel regression. We prove that our new confidence bounds are always tighter than existing ones in this setting. We apply our confidence bounds to the kernel bandit problem, where future actions depend on the previous history. When our confidence bounds replace existing ones, the KernelUCB (GP-UCB) algorithm has better empirical performance, a matching worst-case performance guarantee and comparable computational cost. Our new confidence bounds can be used as a generic tool to design improved algorithms for other kernelised learning and decision-making problems.
Improved Algorithms for Stochastic Linear Bandits Using Tail Bounds for Martingale Mixtures
Sep 27, 2023



We present improved algorithms with worst-case regret guarantees for the stochastic linear bandit problem. The widely used "optimism in the face of uncertainty" principle reduces a stochastic bandit problem to the construction of a confidence sequence for the unknown reward function. The performance of the resulting bandit algorithm depends on the size of the confidence sequence, with smaller confidence sets yielding better empirical performance and stronger regret guarantees. In this work, we use a novel tail bound for adaptive martingale mixtures to construct confidence sequences which are suitable for stochastic bandits. These confidence sequences allow for efficient action selection via convex programming. We prove that a linear bandit algorithm based on our confidence sequences is guaranteed to achieve competitive worst-case regret. We show that our confidence sequences are tighter than competitors, both empirically and theoretically. Finally, we demonstrate that our tighter confidence sequences give improved performance in several hyperparameter tuning tasks.
PAC-Bayes Bounds for Bandit Problems: A Survey and Experimental Comparison
Nov 29, 2022



PAC-Bayes has recently re-emerged as an effective theory with which one can derive principled learning algorithms with tight performance guarantees. However, applications of PAC-Bayes to bandit problems are relatively rare, which is a great misfortune. Many decision-making problems in healthcare, finance and natural sciences can be modelled as bandit problems. In many of these applications, principled algorithms with strong performance guarantees would be very much appreciated. This survey provides an overview of PAC-Bayes performance bounds for bandit problems and an experimental comparison of these bounds. Our experimental comparison has revealed that available PAC-Bayes upper bounds on the cumulative regret are loose, whereas available PAC-Bayes lower bounds on the expected reward can be surprisingly tight. We found that an offline contextual bandit algorithm that learns a policy by optimising a PAC-Bayes bound was able to learn randomised neural network polices with competitive expected reward and non-vacuous performance guarantees.
PAC-Bayesian Lifelong Learning For Multi-Armed Bandits
Mar 07, 2022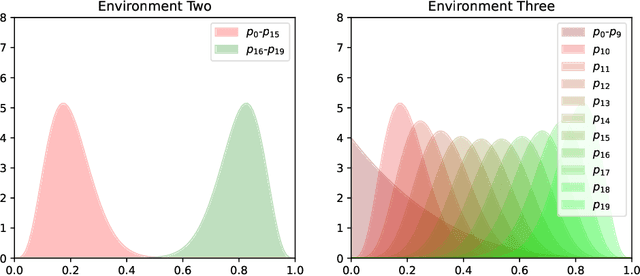
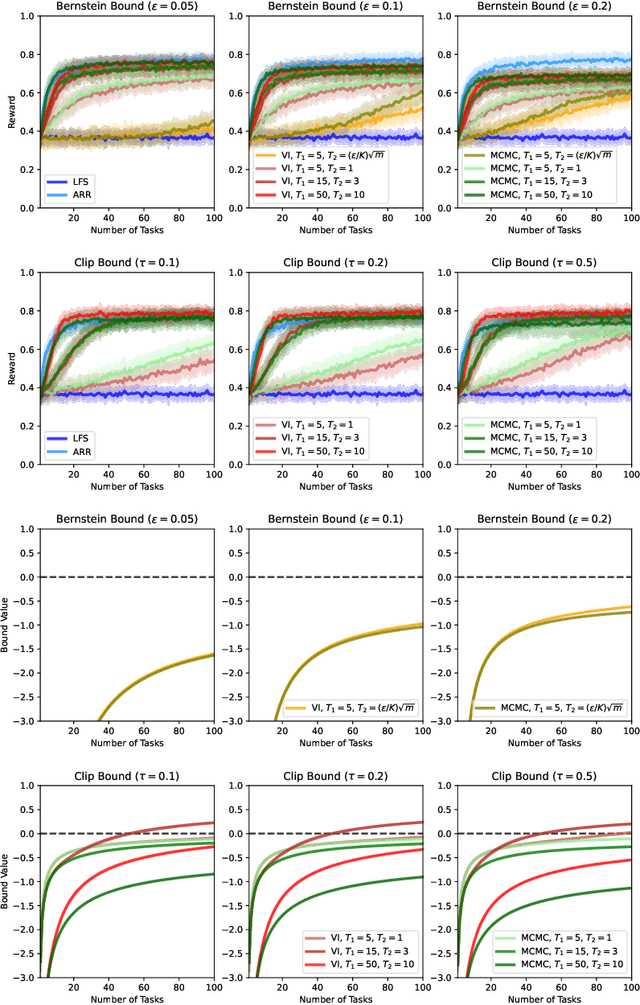
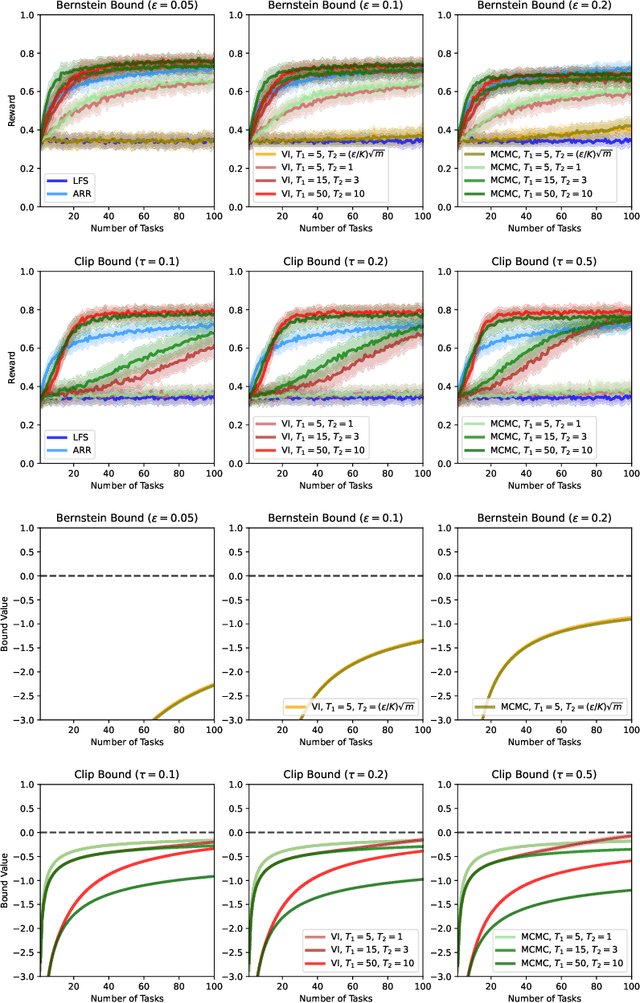
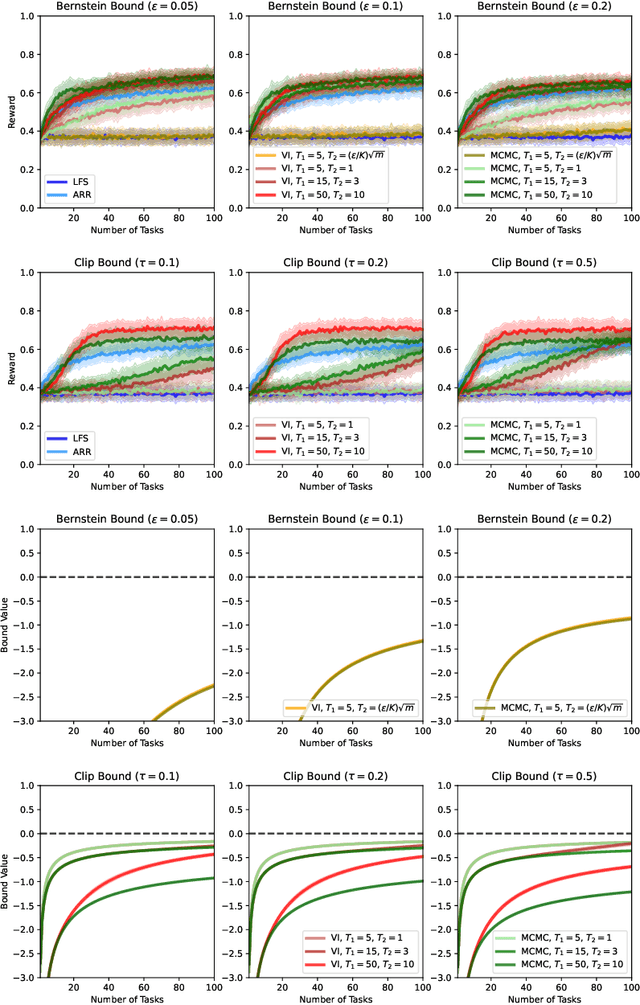
We present a PAC-Bayesian analysis of lifelong learning. In the lifelong learning problem, a sequence of learning tasks is observed one-at-a-time, and the goal is to transfer information acquired from previous tasks to new learning tasks. We consider the case when each learning task is a multi-armed bandit problem. We derive lower bounds on the expected average reward that would be obtained if a given multi-armed bandit algorithm was run in a new task with a particular prior and for a set number of steps. We propose lifelong learning algorithms that use our new bounds as learning objectives. Our proposed algorithms are evaluated in several lifelong multi-armed bandit problems and are found to perform better than a baseline method that does not use generalisation bounds.
* 29 pages, 5 figures