 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaStereo: An Efficient Domain-Adaptive Stereo Matching Approach
Dec 09, 2021
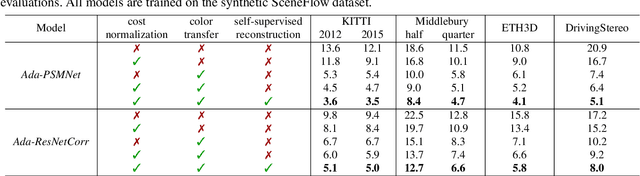
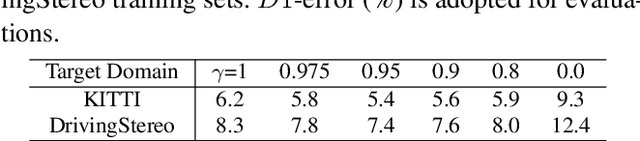
Recently, records on stereo matching benchmarks are constantly broken by end-to-end disparity networks. However, the domain adaptation ability of these deep models is quite limited. Addressing such problem, we present a novel domain-adaptive approach called AdaStereo that aims to align multi-level representations for deep stereo matching networks. Compared to previous methods, our AdaStereo realizes a more standard, complete and effective domain adaptation pipeline. Firstly, we propose a non-adversarial progressive color transfer algorithm for input image-level alignment. Secondly, we design an efficient parameter-free cost normalization layer for internal feature-level alignment. Lastly, a highly related auxiliary task, self-supervised occlusion-aware reconstruction is presented to narrow the gaps in output space. We perform intensive ablation studies and break-down comparisons to validate the effectiveness of each proposed module. With no extra inference overhead and only a slight increase in training complexity, our AdaStereo models achieve state-of-the-art cross-domain performance on multiple benchmarks, including KITTI, Middlebury, ETH3D and DrivingStereo, even outperforming some state-of-the-art disparity networks finetuned with target-domain ground-truths. Moreover, based on two additional evaluation metrics, the superiority of our domain-adaptive stereo matching pipeline is further uncovered from more perspectives. Finally, we demonstrate that our method is robust to various domain adaptation settings, and can be easily integrated into quick adaptation application scenarios and real-world deployments.
AdaStereo: A Simple and Efficient Approach for Adaptive Stereo Matching
Apr 09, 2020
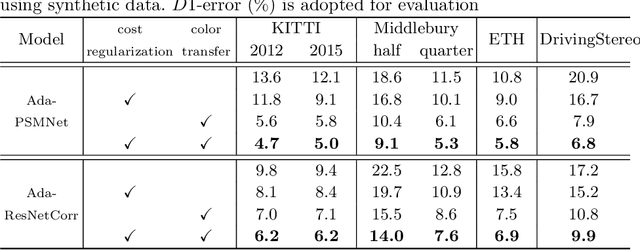
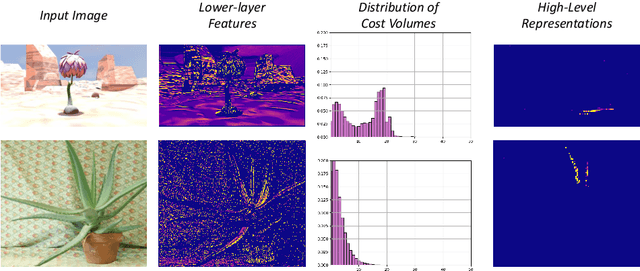
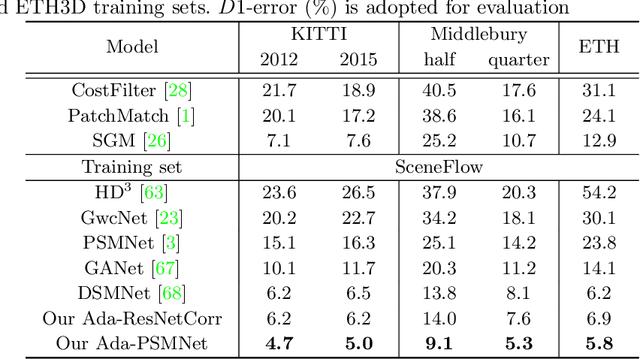
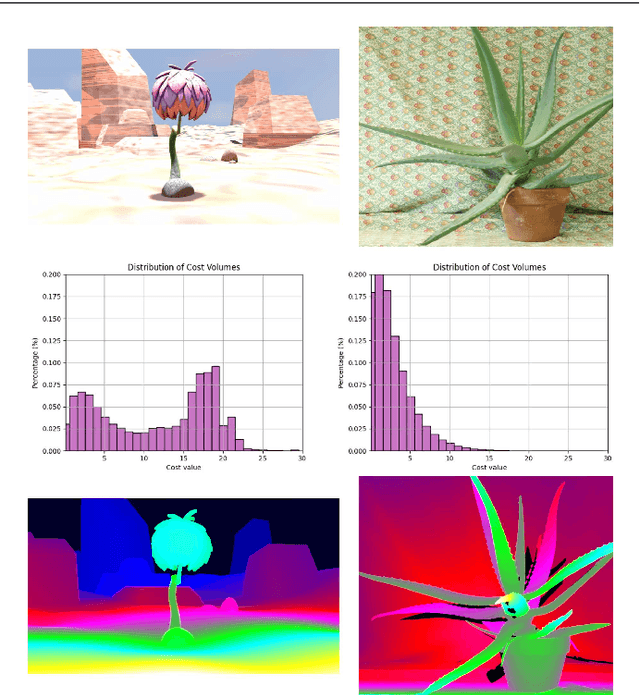
In this paper, we attempt to solve the domain adaptation problem for deep stereo matching networks. Instead of resorting to black-box structures or layers to find implicit connections across domains, we focus on investigating adaptation gaps for stereo matching. By visual inspections and extensive experiments, we conclude that low-level aligning is crucial for adaptive stereo matching, since main gaps across domains lie in the inconsistent input color and cost volume distributions. Correspondingly, we design a bottom-up domain adaptation method, in which two particular approaches are proposed, i.e. color transfer and cost regularization, that can be easily integrated into existing stereo matching models. The color transfer enables transferring a large amount of synthetic data to the same color spaces with target domains during training. The cost regularization can further constrain both the lower-layer features and cost volumes to domain-invariant distributions. Although our proposed strategies are simple and have no parameters to learn, they do improve the generalization ability of existing disparity networks by a large margin. We conduct experiments across multiple datasets, including Scene Flow, KITTI, Middlebury, ETH3D and DrivingStereo. Without whistles and bells, our synthetic-data pretrained models achieve state-of-the-art cross-domain performance compared to previous domain-invariant methods, even outperform state-of-the-art disparity networks fine-tuned with target domain ground-truths on multiple stereo matching benchmarks.
SegStereo: Exploiting Semantic Information for Disparity Estimation
Jul 31, 2018
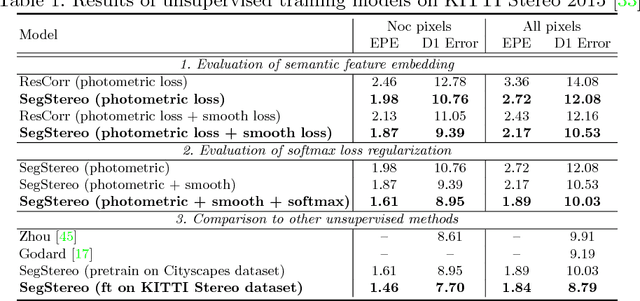
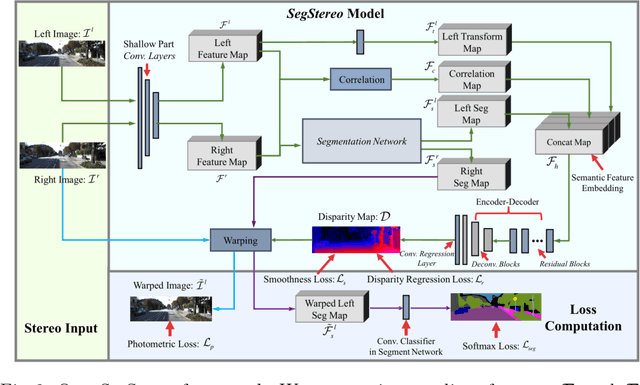
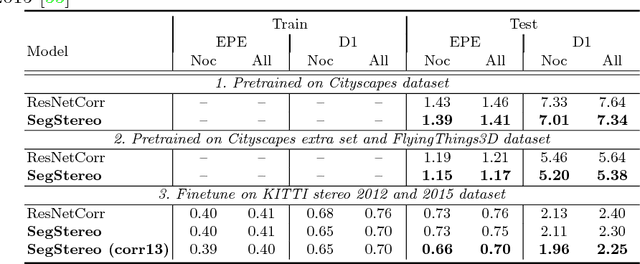
Disparity estimation for binocular stereo images finds a wide range of applications. Traditional algorithms may fail on featureless regions, which could be handled by high-level clues such as semantic segments. In this paper, we suggest that appropriate incorporation of semantic cues can greatly rectify prediction in commonly-used disparity estimation frameworks. Our method conducts semantic feature embedding and regularizes semantic cues as the loss term to improve learning disparity. Our unified model SegStereo employs semantic features from segmentation and introduces semantic softmax loss, which helps improve the prediction accuracy of disparity maps. The semantic cues work well in both unsupervised and supervised manners. SegStereo achieves state-of-the-art results on KITTI Stereo benchmark and produces decent prediction on both CityScapes and FlyingThings3D datasets.