 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Common Interface for Automatic Differentiation
May 08, 2025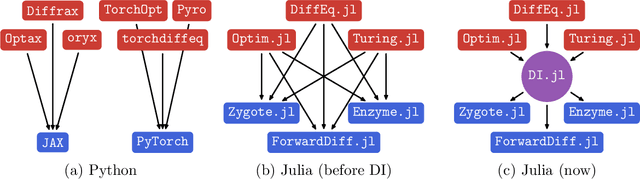


For scientific machine learning tasks with a lot of custom code, picking the right Automatic Differentiation (AD) system matters. Our Julia package DifferentiationInterface.jl provides a common frontend to a dozen AD backends, unlocking easy comparison and modular development. In particular, its built-in preparation mechanism leverages the strengths of each backend by amortizing one-time computations. This is key to enabling sophisticated features like sparsity handling without putting additional burdens on the user.
Sparser, Better, Faster, Stronger: Efficient Automatic Differentiation for Sparse Jacobians and Hessians
Jan 29, 2025



From implicit differentiation to probabilistic modeling, Jacobians and Hessians have many potential use cases in Machine Learning (ML), but conventional wisdom views them as computationally prohibitive. Fortunately, these matrices often exhibit sparsity, which can be leveraged to significantly speed up the process of Automatic Differentiation (AD). This paper presents advances in Automatic Sparse Differentiation (ASD), starting with a new perspective on sparsity detection. Our refreshed exposition is based on operator overloading, able to detect both local and global sparsity patterns, and naturally avoids dead ends in the control flow graph. We also describe a novel ASD pipeline in Julia, consisting of independent software packages for sparsity detection, matrix coloring, and differentiation, which together enable ASD based on arbitrary AD backends. Our pipeline is fully automatic and requires no modification of existing code, making it compatible with existing ML codebases. We demonstrate that this pipeline unlocks Jacobian and Hessian matrices at scales where they were considered too expensive to compute. On real-world problems from scientific ML and optimization, we show significant speed-ups of up to three orders of magnitude. Notably, our ASD pipeline often outperforms standard AD for one-off computations, once thought impractical due to slower sparsity detection methods.
Analysis of Bootstrap and Subsampling in High-dimensional Regularized Regression
Feb 21, 2024



We investigate popular resampling methods for estimating the uncertainty of statistical models, such as subsampling, bootstrap and the jackknife, and their performance in high-dimensional supervised regression tasks. We provide a tight asymptotic description of the biases and variances estimated by these methods in the context of generalized linear models, such as ridge and logistic regression, taking the limit where the number of samples $n$ and dimension $d$ of the covariates grow at a comparable fixed rate $\alpha\!=\! n/d$. Our findings are three-fold: i) resampling methods are fraught with problems in high dimensions and exhibit the double-descent-like behavior typical of these situations; ii) only when $\alpha$ is large enough do they provide consistent and reliable error estimations (we give convergence rates); iii) in the over-parametrized regime $\alpha\!<\!1$ relevant to modern machine learning practice, their predictions are not consistent, even with optimal regularization.
Learning with Combinatorial Optimization Layers: a Probabilistic Approach
Jul 27, 2022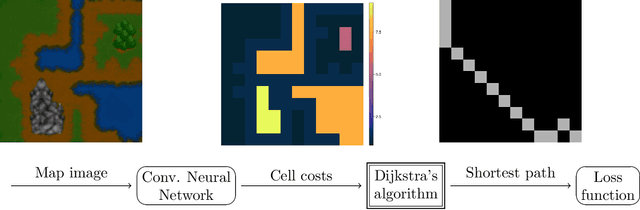

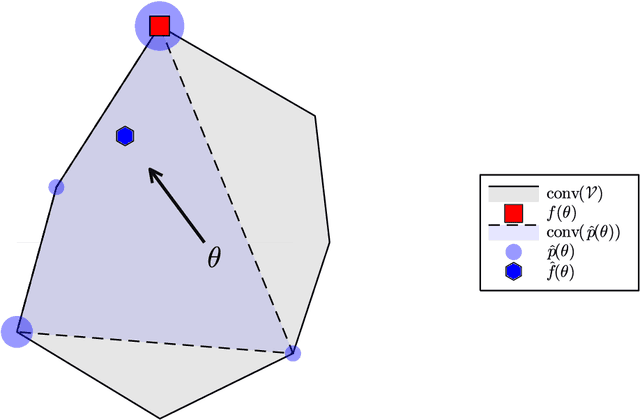
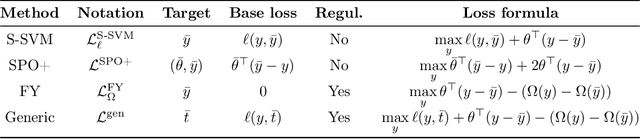
Combinatorial optimization (CO) layers in machine learning (ML) pipelines are a powerful tool to tackle data-driven decision tasks, but they come with two main challenges. First, the solution of a CO problem often behaves as a piecewise constant function of its objective parameters. Given that ML pipelines are typically trained using stochastic gradient descent, the absence of slope information is very detrimental. Second, standard ML losses do not work well in combinatorial settings. A growing body of research addresses these challenges through diverse methods. Unfortunately, the lack of well-maintained implementations slows down the adoption of CO layers. In this paper, building upon previous works, we introduce a probabilistic perspective on CO layers, which lends itself naturally to approximate differentiation and the construction of structured losses. We recover many approaches from the literature as special cases, and we also derive new ones. Based on this unifying perspective, we present InferOpt.jl, an open-source Julia package that 1) allows turning any CO oracle with a linear objective into a differentiable layer, and 2) defines adequate losses to train pipelines containing such layers. Our library works with arbitrary optimization algorithms, and it is fully compatible with Julia's ML ecosystem. We demonstrate its abilities using a pathfinding problem on video game maps.
Minimax Estimation of Partially-Observed Vector AutoRegressions
Jun 17, 2021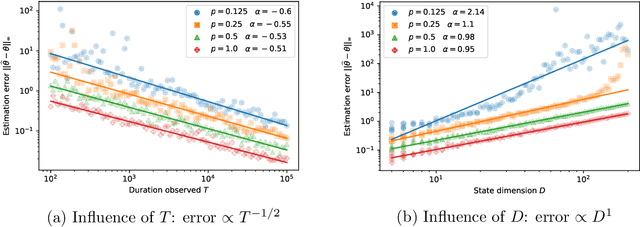
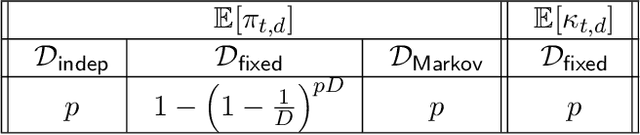
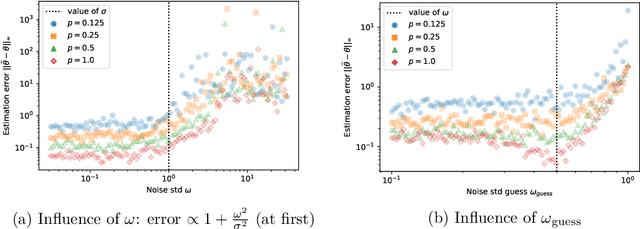

To understand the behavior of large dynamical systems like transportation networks, one must often rely on measurements transmitted by a set of sensors, for instance individual vehicles. Such measurements are likely to be incomplete and imprecise, which makes it hard to recover the underlying signal of interest.Hoping to quantify this phenomenon, we study the properties of a partially-observed state-space model. In our setting, the latent state $X$ follows a high-dimensional Vector AutoRegressive process $X_t = \theta X_{t-1} + \varepsilon_t$. Meanwhile, the observations $Y$ are given by a noise-corrupted random sample from the state $Y_t = \Pi_t X_t + \eta_t$. Several random sampling mechanisms are studied, allowing us to investigate the effect of spatial and temporal correlations in the distribution of the sampling matrices $\Pi_t$.We first prove a lower bound on the minimax estimation error for the transition matrix $\theta$. We then describe a sparse estimator based on the Dantzig selector and upper bound its non-asymptotic error, showing that it achieves the optimal convergence rate for most of our sampling mechanisms. Numerical experiments on simulated time series validate our theoretical findings, while an application to open railway data highlights the relevance of this model for public transport traffic analysis.