 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Conformal Prediction Intervals with Approximate Message Passing
Oct 21, 2024Conformal prediction has emerged as a powerful tool for building prediction intervals that are valid in a distribution-free way. However, its evaluation may be computationally costly, especially in the high-dimensional setting where the dimensionality and sample sizes are both large and of comparable magnitudes. To address this challenge in the context of generalized linear regression, we propose a novel algorithm based on Approximate Message Passing (AMP) to accelerate the computation of prediction intervals using full conformal prediction, by approximating the computation of conformity scores. Our work bridges a gap between modern uncertainty quantification techniques and tools for high-dimensional problems involving the AMP algorithm. We evaluate our method on both synthetic and real data, and show that it produces prediction intervals that are close to the baseline methods, while being orders of magnitude faster. Additionally, in the high-dimensional limit and under assumptions on the data distribution, the conformity scores computed by AMP converge to the one computed exactly, which allows theoretical study and benchmarking of conformal methods in high dimensions.
Analysis of Bootstrap and Subsampling in High-dimensional Regularized Regression
Feb 21, 2024



We investigate popular resampling methods for estimating the uncertainty of statistical models, such as subsampling, bootstrap and the jackknife, and their performance in high-dimensional supervised regression tasks. We provide a tight asymptotic description of the biases and variances estimated by these methods in the context of generalized linear models, such as ridge and logistic regression, taking the limit where the number of samples $n$ and dimension $d$ of the covariates grow at a comparable fixed rate $\alpha\!=\! n/d$. Our findings are three-fold: i) resampling methods are fraught with problems in high dimensions and exhibit the double-descent-like behavior typical of these situations; ii) only when $\alpha$ is large enough do they provide consistent and reliable error estimations (we give convergence rates); iii) in the over-parametrized regime $\alpha\!<\!1$ relevant to modern machine learning practice, their predictions are not consistent, even with optimal regularization.
Expectation consistency for calibration of neural networks
Mar 05, 2023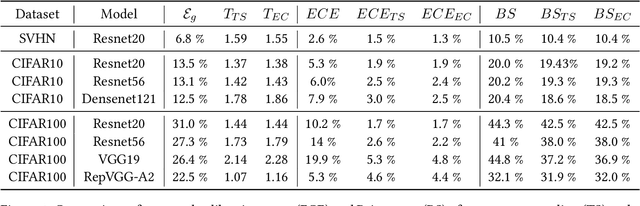
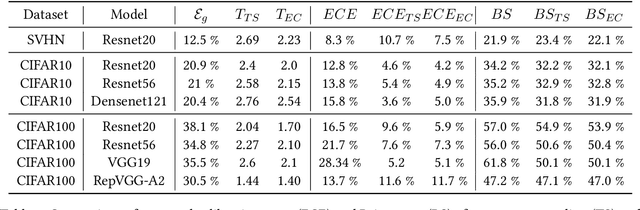
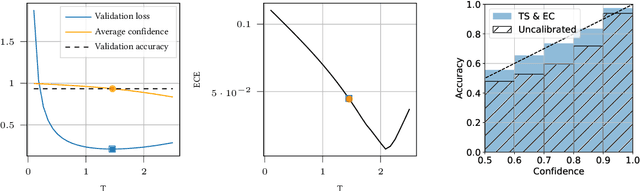
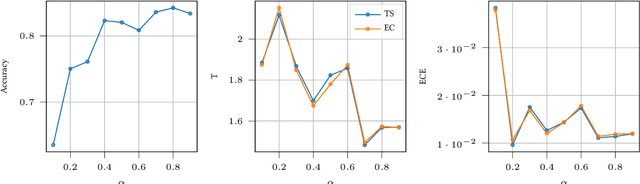
Despite their incredible performance, it is well reported that deep neural networks tend to be overoptimistic about their prediction confidence. Finding effective and efficient calibration methods for neural networks is therefore an important endeavour towards better uncertainty quantification in deep learning. In this manuscript, we introduce a novel calibration technique named expectation consistency (EC), consisting of a post-training rescaling of the last layer weights by enforcing that the average validation confidence coincides with the average proportion of correct labels. First, we show that the EC method achieves similar calibration performance to temperature scaling (TS) across different neural network architectures and data sets, all while requiring similar validation samples and computational resources. However, we argue that EC provides a principled method grounded on a Bayesian optimality principle known as the Nishimori identity. Next, we provide an asymptotic characterization of both TS and EC in a synthetic setting and show that their performance crucially depends on the target function. In particular, we discuss examples where EC significantly outperforms TS.
A study of uncertainty quantification in overparametrized high-dimensional models
Oct 23, 2022



Uncertainty quantification is a central challenge in reliable and trustworthy machine learning. Naive measures such as last-layer scores are well-known to yield overconfident estimates in the context of overparametrized neural networks. Several methods, ranging from temperature scaling to different Bayesian treatments of neural networks, have been proposed to mitigate overconfidence, most often supported by the numerical observation that they yield better calibrated uncertainty measures. In this work, we provide a sharp comparison between popular uncertainty measures for binary classification in a mathematically tractable model for overparametrized neural networks: the random features model. We discuss a trade-off between classification accuracy and calibration, unveiling a double descent like behavior in the calibration curve of optimally regularized estimators as a function of overparametrization. This is in contrast with the empirical Bayes method, which we show to be well calibrated in our setting despite the higher generalization error and overparametrization.
Theoretical characterization of uncertainty in high-dimensional linear classification
Feb 07, 2022Being able to reliably assess not only the accuracy but also the uncertainty of models' predictions is an important endeavour in modern machine learning. Even if the model generating the data and labels is known, computing the intrinsic uncertainty after learning the model from a limited number of samples amounts to sampling the corresponding posterior probability measure. Such sampling is computationally challenging in high-dimensional problems and theoretical results on heuristic uncertainty estimators in high-dimensions are thus scarce. In this manuscript, we characterise uncertainty for learning from limited number of samples of high-dimensional Gaussian input data and labels generated by the probit model. We prove that the Bayesian uncertainty (i.e. the posterior marginals) can be asymptotically obtained by the approximate message passing algorithm, bypassing the canonical but costly Monte Carlo sampling of the posterior. We then provide a closed-form formula for the joint statistics between the logistic classifier, the uncertainty of the statistically optimal Bayesian classifier and the ground-truth probit uncertainty. The formula allows us to investigate calibration of the logistic classifier learning from limited amount of samples. We discuss how over-confidence can be mitigated by appropriately regularising, and show that cross-validating with respect to the loss leads to better calibration than with the 0/1 error.