 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoL-PIM: Long-Context LLM Decoding with Scalable DRAM-PIM System
Dec 28, 2024



The expansion of large language models (LLMs) with hundreds of billions of parameters presents significant challenges to computational resources, particularly data movement and memory bandwidth. Long-context LLMs, which process sequences of tens of thousands of tokens, further increase the demand on the memory system as the complexity in attention layers and key-value cache sizes is proportional to the context length. Processing-in-Memory (PIM) maximizes memory bandwidth by moving compute to the data and can address the memory bandwidth challenges; however, PIM is not necessarily scalable to accelerate long-context LLM because of limited per-module memory capacity and the inflexibility of fixed-functional unit PIM architecture and static memory management. In this work, we propose LoL-PIM which is a multi-node PIM architecture that accelerates long context LLM through hardware-software co-design. In particular, we propose how pipeline parallelism can be exploited across a multi-PIM module while a direct PIM access (DPA) controller (or DMA for PIM) is proposed that enables dynamic PIM memory management and results in efficient PIM utilization across a diverse range of context length. We developed an MLIR-based compiler for LoL-PIM extending a commercial PIM-based compiler where the software modifications were implemented and evaluated, while the hardware changes were modeled in the simulator. Our evaluations demonstrate that LoL-PIM significantly improves throughput and reduces latency for long-context LLM inference, outperforming both multi-GPU and GPU-PIM systems (up to 8.54x and 16.0x speedup, respectively), thereby enabling more efficient deployment of LLMs in real-world applications.
CBP: Backpropagation with constraint on weight precision using a pseudo-Lagrange multiplier method
Oct 06, 2021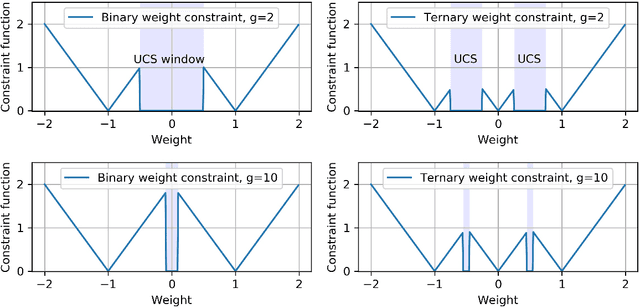
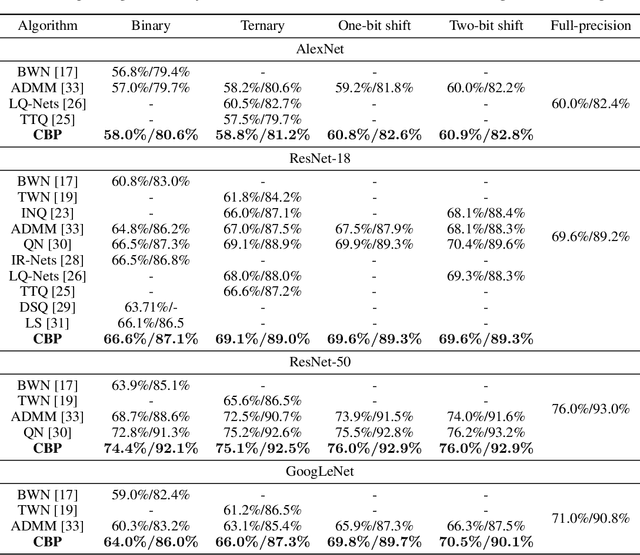
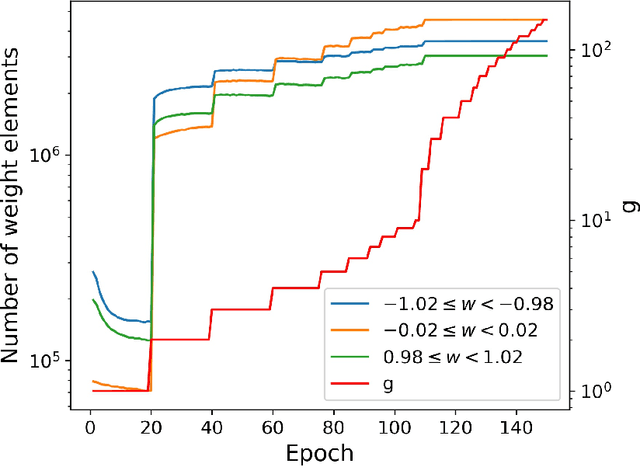

Backward propagation of errors (backpropagation) is a method to minimize objective functions (e.g., loss functions) of deep neural networks by identifying optimal sets of weights and biases. Imposing constraints on weight precision is often required to alleviate prohibitive workloads on hardware. Despite the remarkable success of backpropagation, the algorithm itself is not capable of considering such constraints unless additional algorithms are applied simultaneously. To address this issue, we propose the constrained backpropagation (CBP) algorithm based on a pseudo-Lagrange multiplier method to obtain the optimal set of weights that satisfy a given set of constraints. The defining characteristic of the proposed CBP algorithm is the utilization of a Lagrangian function (loss function plus constraint function) as its objective function. We considered various types of constraints--binary, ternary, one-bit shift, and two-bit shift weight constraints. As a post-training method, CBP applied to AlexNet, ResNet-18, ResNet-50, and GoogLeNet on ImageNet, which were pre-trained using the conventional backpropagation. For all cases, the proposed algorithm outperforms the state-of-the-art methods on ImageNet, e.g., 66.6%, 74.4%, and 64.0% top-1 accuracy for ResNet-18, ResNet-50, and GoogLeNet with binary weights, respectively. This highlights CBP as a learning algorithm to address diverse constraints with the minimal performance loss by employing appropriate constraint functions.
Simplified calcium signaling cascade for synaptic plasticity
Nov 26, 2019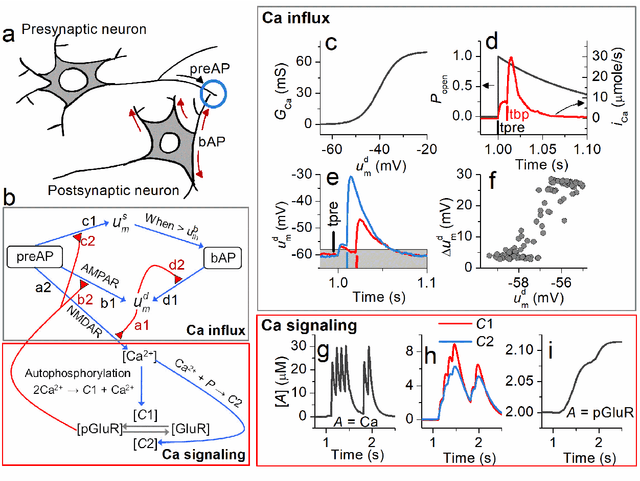
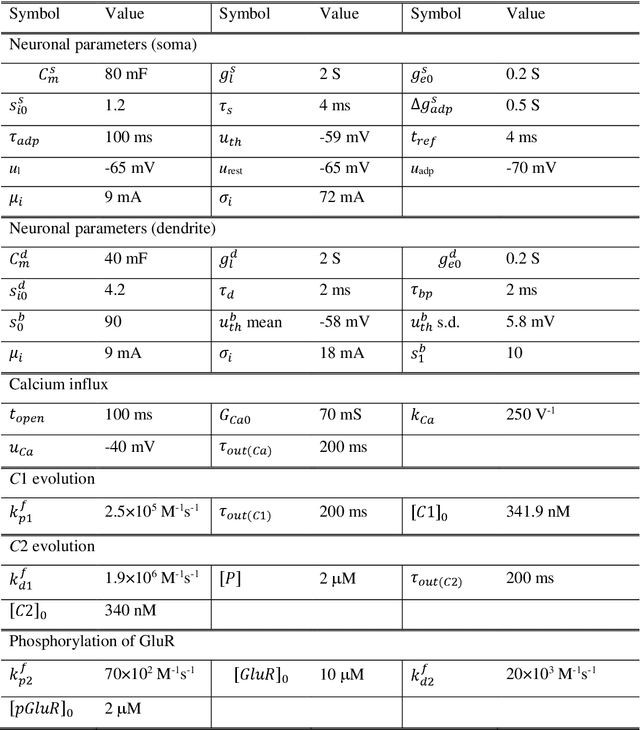
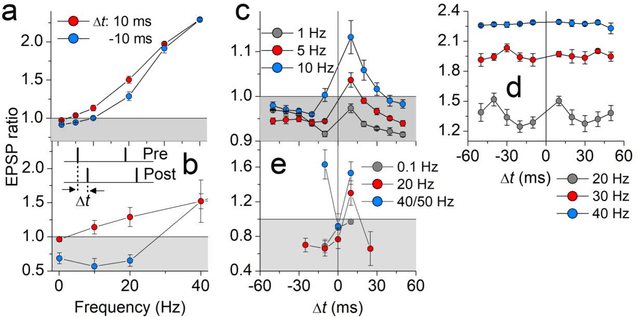
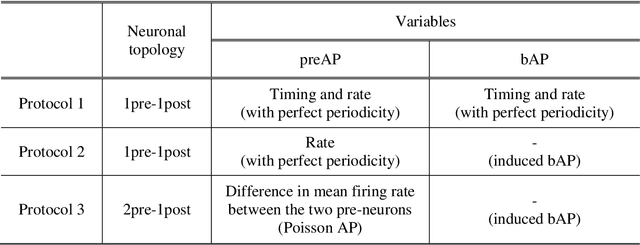
We propose a model for synaptic plasticity based on a calcium signaling cascade. The model simplifies the full signaling pathways from a calcium influx to the phosphorylation (potentiation) and dephosphorylation (depression) of glutamate receptors that are gated by fictive C1 and C2 catalysts, respectively. This model is based on tangible chemical reactions, including fictive catalysts, for long-term plasticity rather than the conceptual theories commonplace in various models, such as preset thresholds of calcium concentration. Our simplified model successfully reproduced the experimental synaptic plasticity induced by different protocols such as (i) a synchronous pairing protocol and (ii) correlated presynaptic and postsynaptic action potentials (APs). Further, the ocular dominance plasticity (or the experimental verification of the celebrated Bienenstock--Cooper--Munro theory) was reproduced by two model synapses that compete by means of back-propagating APs (bAPs). The key to this competition is synapse-specific bAPs with reference to bAP-boosting on the physiological grounds.
Markov chain Hebbian learning algorithm with ternary synaptic units
Nov 23, 2017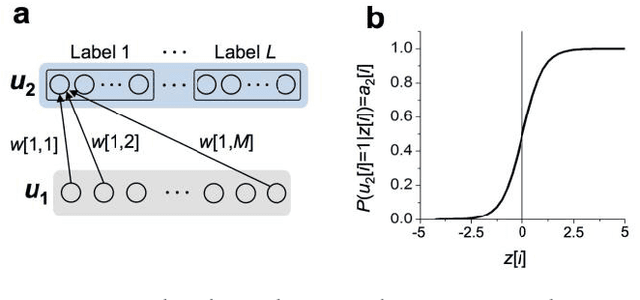

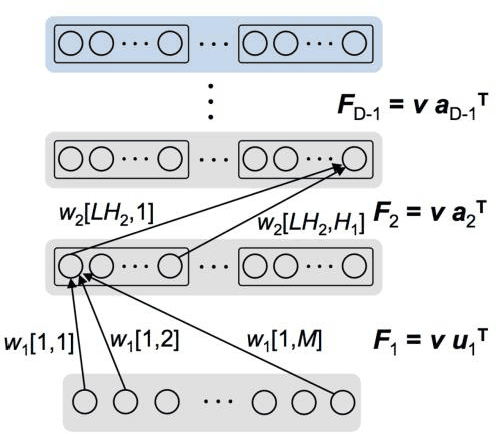
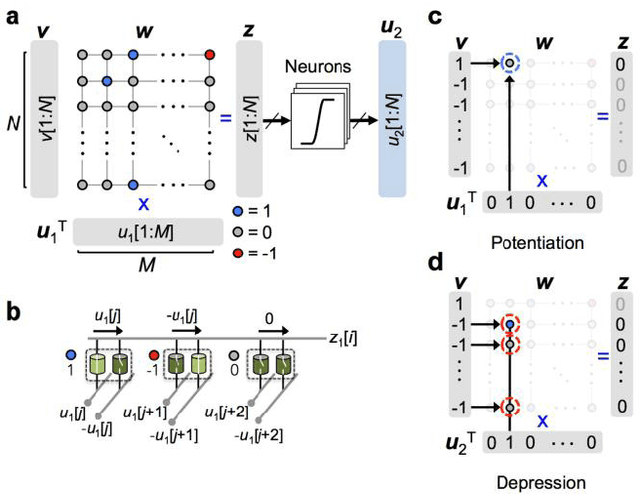
In spite of remarkable progress in machine learning techniques, the state-of-the-art machine learning algorithms often keep machines from real-time learning (online learning) due in part to computational complexity in parameter optimization. As an alternative, a learning algorithm to train a memory in real time is proposed, which is named as the Markov chain Hebbian learning algorithm. The algorithm pursues efficient memory use during training in that (i) the weight matrix has ternary elements (-1, 0, 1) and (ii) each update follows a Markov chain--the upcoming update does not need past weight memory. The algorithm was verified by two proof-of-concept tasks (handwritten digit recognition and multiplication table memorization) in which numbers were taken as symbols. Particularly, the latter bases multiplication arithmetic on memory, which may be analogous to humans' mental arithmetic. The memory-based multiplication arithmetic feasibly offers the basis of factorization, supporting novel insight into the arithmetic.