 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACOL: Poisoning Attacks Against Continual Learners
Nov 18, 2023Continual learning algorithms are typically exposed to untrusted sources that contain training data inserted by adversaries and bad actors. An adversary can insert a small number of poisoned samples, such as mislabeled samples from previously learned tasks, or intentional adversarial perturbed samples, into the training datasets, which can drastically reduce the model's performance. In this work, we demonstrate that continual learning systems can be manipulated by malicious misinformation and present a new category of data poisoning attacks specific for continual learners, which we refer to as {\em Poisoning Attacks Against Continual Learners} (PACOL). The effectiveness of labeling flipping attacks inspires PACOL; however, PACOL produces attack samples that do not change the sample's label and produce an attack that causes catastrophic forgetting. A comprehensive set of experiments shows the vulnerability of commonly used generative replay and regularization-based continual learning approaches against attack methods. We evaluate the ability of label-flipping and a new adversarial poison attack, namely PACOL proposed in this work, to force the continual learning system to forget the knowledge of a learned task(s). More specifically, we compared the performance degradation of continual learning systems trained on benchmark data streams with and without poisoning attacks. Moreover, we discuss the stealthiness of the attacks in which we test the success rate of data sanitization defense and other outlier detection-based defenses for filtering out adversarial samples.
Knowledge Distillation Under Ideal Joint Classifier Assumption
Apr 19, 2023



Knowledge distillation is a powerful technique to compress large neural networks into smaller, more efficient networks. Softmax regression representation learning is a popular approach that uses a pre-trained teacher network to guide the learning of a smaller student network. While several studies explored the effectiveness of softmax regression representation learning, the underlying mechanism that provides knowledge transfer is not well understood. This paper presents Ideal Joint Classifier Knowledge Distillation (IJCKD), a unified framework that provides a clear and comprehensive understanding of the existing knowledge distillation methods and a theoretical foundation for future research. Using mathematical techniques derived from a theory of domain adaptation, we provide a detailed analysis of the student network's error bound as a function of the teacher. Our framework enables efficient knowledge transfer between teacher and student networks and can be applied to various applications.
A Maximum Log-Likelihood Method for Imbalanced Few-Shot Learning Tasks
Dec 07, 2022Few-shot learning is a rapidly evolving area of research in machine learning where the goal is to classify unlabeled data with only one or "a few" labeled exemplary samples. Neural networks are typically trained to minimize a distance metric between labeled exemplary samples and a query set. Early few-shot approaches use an episodic training process to sub-sample the training data into few-shot batches. This training process matches the sub-sampling done on evaluation. Recently, conventional supervised training coupled with a cosine distance has achieved superior performance for few-shot. Despite the diversity of few-shot approaches over the past decade, most methods still rely on the cosine or Euclidean distance layer between the latent features of the trained network. In this work, we investigate the distributions of trained few-shot features and demonstrate that they can be roughly approximated as exponential distributions. Under this assumption of an exponential distribution, we propose a new maximum log-likelihood metric for few-shot architectures. We demonstrate that the proposed metric achieves superior performance accuracy w.r.t. conventional similarity metrics (e.g., cosine, Euclidean, etc.), and achieve state-of-the-art inductive few-shot performance. Further, additional gains can be achieved by carefully combining multiple metrics and neither of our methods require post-processing feature transformations, which are common to many algorithms. Finally, we demonstrate a novel iterative algorithm designed around our maximum log-likelihood approach that achieves state-of-the-art transductive few-shot performance when the evaluation data is imbalanced. We have made our code publicly available at https://github.com/samuelhess/MLL_FSL/.
Shadows Aren't So Dangerous After All: A Fast and Robust Defense Against Shadow-Based Adversarial Attacks
Aug 18, 2022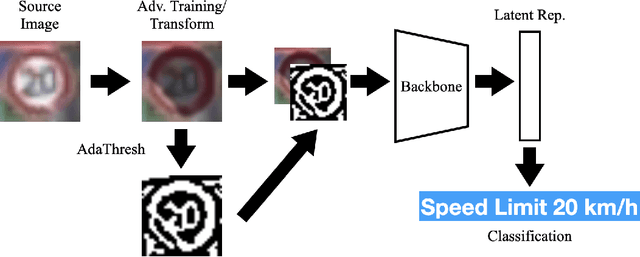


Robust classification is essential in tasks like autonomous vehicle sign recognition, where the downsides of misclassification can be grave. Adversarial attacks threaten the robustness of neural network classifiers, causing them to consistently and confidently misidentify road signs. One such class of attack, shadow-based attacks, causes misidentifications by applying a natural-looking shadow to input images, resulting in road signs that appear natural to a human observer but confusing for these classifiers. Current defenses against such attacks use a simple adversarial training procedure to achieve a rather low 25\% and 40\% robustness on the GTSRB and LISA test sets, respectively. In this paper, we propose a robust, fast, and generalizable method, designed to defend against shadow attacks in the context of road sign recognition, that augments source images with binary adaptive threshold and edge maps. We empirically show its robustness against shadow attacks, and reformulate the problem to show its similarity $\varepsilon$ perturbation-based attacks. Experimental results show that our edge defense results in 78\% robustness while maintaining 98\% benign test accuracy on the GTSRB test set, with similar results from our threshold defense. Link to our code is in the paper.
DeScoD-ECG: Deep Score-Based Diffusion Model for ECG Baseline Wander and Noise Removal
Jul 31, 2022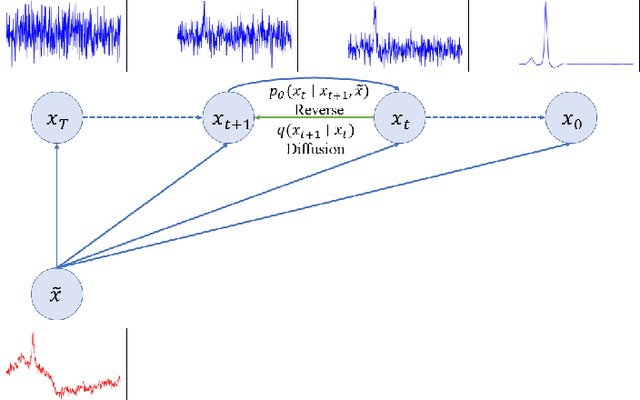
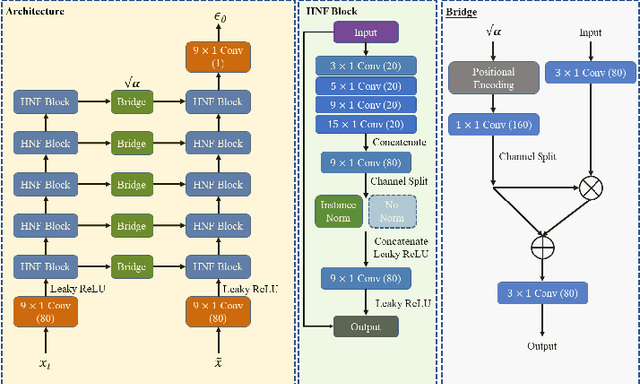
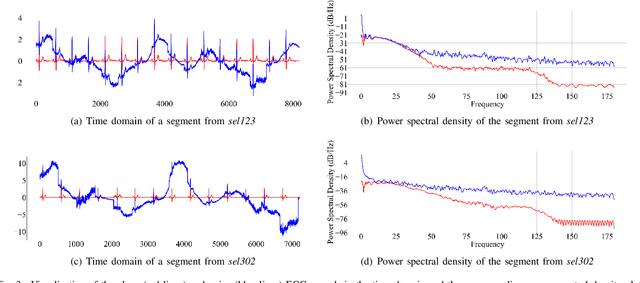
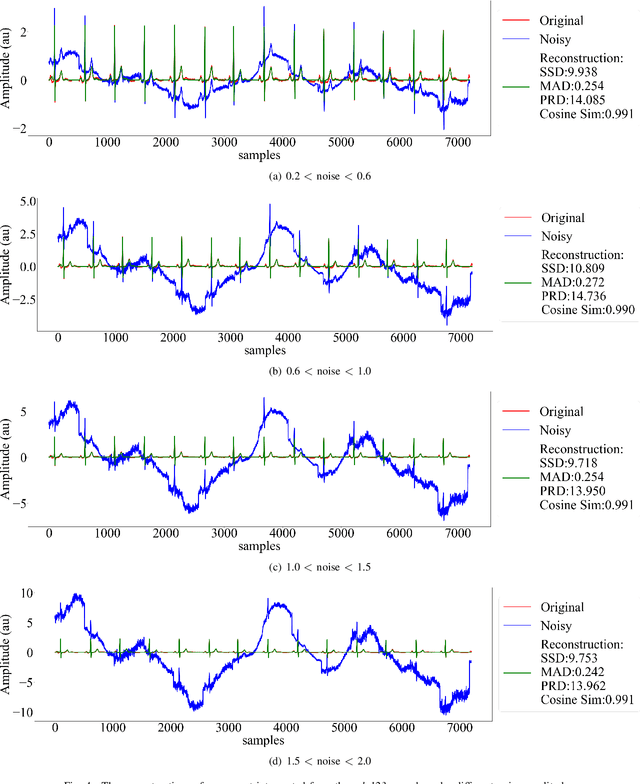
Objective: Electrocardiogram (ECG) signals commonly suffer noise interference, such as baseline wander. High-quality and high-fidelity reconstruction of the ECG signals is of great significance to diagnosing cardiovascular diseases. Therefore, this paper proposes a novel ECG baseline wander and noise removal technology. Methods: We extended the diffusion model in a conditional manner that was specific to the ECG signals, namely the Deep Score-Based Diffusion model for Electrocardiogram baseline wander and noise removal (DeScoD-ECG). Moreover, we deployed a multi-shots averaging strategy that improved signal reconstructions. We conducted the experiments on the QT Database and the MIT-BIH Noise Stress Test Database to verify the feasibility of the proposed method. Baseline methods are adopted for comparison, including traditional digital filter-based and deep learning-based methods. Results: The quantities evaluation results show that the proposed method obtained outstanding performance on four distance-based similarity metrics (the sum of squared distance, maximum absolute square, percentage of root distance, and cosine similarity) with 3.771 $\pm$ 5.713 au, 0.329 $\pm$ 0.258 au, 40.527 $\pm$ 26.258 \%, and 0.926 $\pm$ 0.087. This led to at least 20\% overall improvement compared with the best baseline method. Conclusion: This paper demonstrates the state-of-the-art performance of the DeScoD-ECG for ECG noise removal, which has better approximations of the true data distribution and higher stability under extreme noise corruptions. Significance: This study is one of the first to extend the conditional diffusion-based generative model for ECG noise removal, and the DeScoD-ECG has the potential to be widely used in biomedical applications.
ProtoShotXAI: Using Prototypical Few-Shot Architecture for Explainable AI
Oct 22, 2021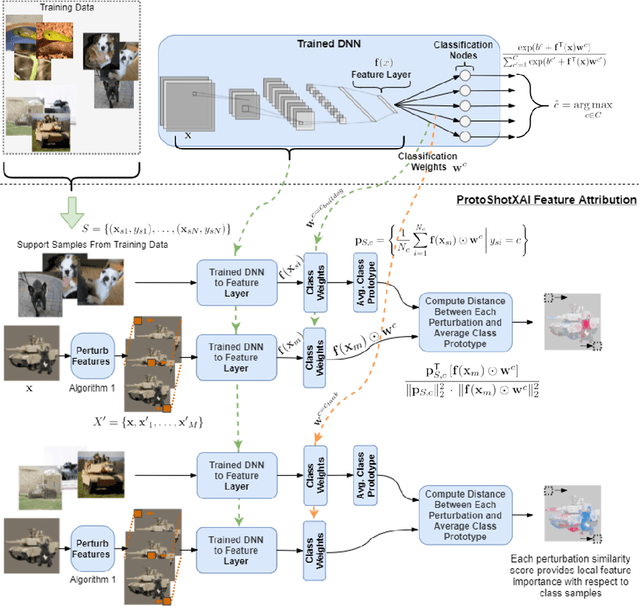



Unexplainable black-box models create scenarios where anomalies cause deleterious responses, thus creating unacceptable risks. These risks have motivated the field of eXplainable Artificial Intelligence (XAI) to improve trust by evaluating local interpretability in black-box neural networks. Unfortunately, the ground truth is unavailable for the model's decision, so evaluation is limited to qualitative assessment. Further, interpretability may lead to inaccurate conclusions about the model or a false sense of trust. We propose to improve XAI from the vantage point of the user's trust by exploring a black-box model's latent feature space. We present an approach, ProtoShotXAI, that uses a Prototypical few-shot network to explore the contrastive manifold between nonlinear features of different classes. A user explores the manifold by perturbing the input features of a query sample and recording the response for a subset of exemplars from any class. Our approach is the first locally interpretable XAI model that can be extended to, and demonstrated on, few-shot networks. We compare ProtoShotXAI to the state-of-the-art XAI approaches on MNIST, Omniglot, and ImageNet to demonstrate, both quantitatively and qualitatively, that ProtoShotXAI provides more flexibility for model exploration. Finally, ProtoShotXAI also demonstrates novel explainabilty and detectabilty on adversarial samples.
Adversarial Filters for Secure Modulation Classification
Aug 15, 2020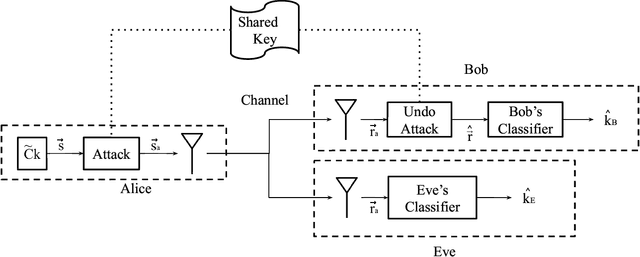
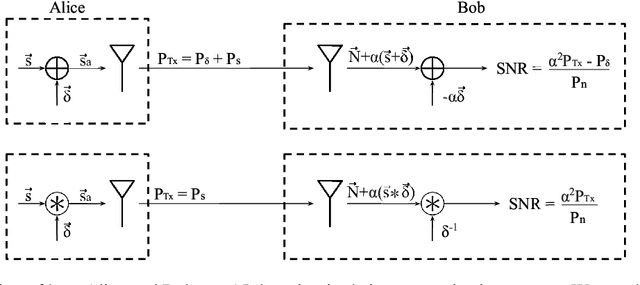
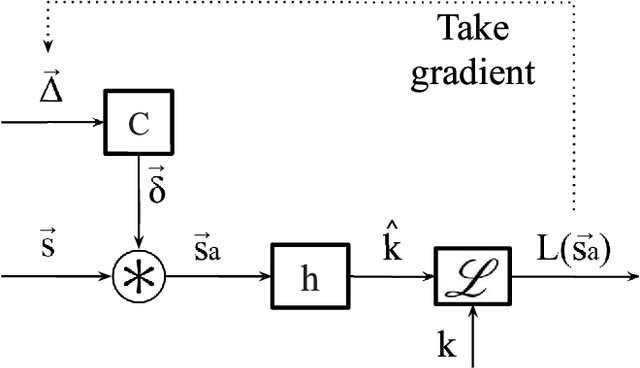

Modulation Classification (MC) refers to the problem of classifying the modulation class of a wireless signal. In the wireless communications pipeline, MC is the first operation performed on the received signal and is critical for reliable decoding. This paper considers the problem of secure modulation classification, where a transmitter (Alice) wants to maximize MC accuracy at a legitimate receiver (Bob) while minimizing MC accuracy at an eavesdropper (Eve). The contribution of this work is to design novel adversarial learning techniques for secure MC. In particular, we present adversarial filtering based algorithms for secure MC, in which Alice uses a carefully designed adversarial filter to mask the transmitted signal, that can maximize MC accuracy at Bob while minimizing MC accuracy at Eve. We present two filtering based algorithms, namely gradient ascent filter (GAF), and a fast gradient filter method (FGFM), with varying levels of complexity. Our proposed adversarial filtering based approaches significantly outperform additive adversarial perturbations (used in the traditional ML community and other prior works on secure MC) and also have several other desirable properties. In particular, GAF and FGFM algorithms are a) computational efficient (allow fast decoding at Bob), b) power-efficient (do not require excessive transmit power at Alice); and c) SNR efficient (i.e., perform well even at low SNR values at Bob).
Edge-Guided Occlusion Fading Reduction for a Light-Weighted Self-Supervised Monocular Depth Estimation
Nov 26, 2019



Self-supervised monocular depth estimation methods generally suffer the occlusion fading issue due to the lack of supervision by the per pixel ground truth. Although a post-processing method was proposed by Godard et. al. to reduce the occlusion fading, the compensated results have a severe halo effect. In this paper, we propose a novel Edge-Guided post-processing to reduce the occlusion fading issue for self-supervised monocular depth estimation. We further introduce Atrous Spatial Pyramid Pooling (ASPP) into the network to reduce the computational costs and improve the inference performance. The proposed ASPP-based network is lighter, faster, and better than current commonly used depth estimation networks. This light-weight network only needs 8.1 million parameters and can achieve up to 40 frames per second for $256\times512$ input in the inference stage using a single nVIDIA GTX1080 GPU. The proposed network also outperforms the current state-of-the-art on the KITTI benchmarks. The ASPP-based network and Edge-Guided post-processing produce better results either quantitatively and qualitatively than the competitors.