 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoShotXAI: Using Prototypical Few-Shot Architecture for Explainable AI
Paper and Code
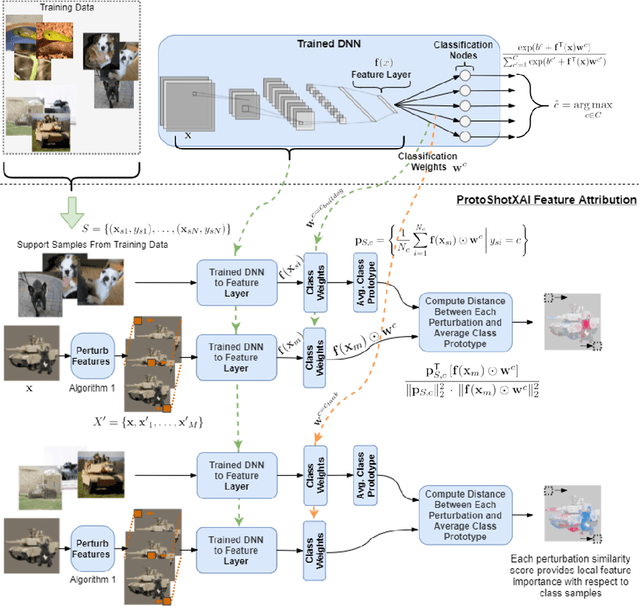



Unexplainable black-box models create scenarios where anomalies cause deleterious responses, thus creating unacceptable risks. These risks have motivated the field of eXplainable Artificial Intelligence (XAI) to improve trust by evaluating local interpretability in black-box neural networks. Unfortunately, the ground truth is unavailable for the model's decision, so evaluation is limited to qualitative assessment. Further, interpretability may lead to inaccurate conclusions about the model or a false sense of trust. We propose to improve XAI from the vantage point of the user's trust by exploring a black-box model's latent feature space. We present an approach, ProtoShotXAI, that uses a Prototypical few-shot network to explore the contrastive manifold between nonlinear features of different classes. A user explores the manifold by perturbing the input features of a query sample and recording the response for a subset of exemplars from any class. Our approach is the first locally interpretable XAI model that can be extended to, and demonstrated on, few-shot networks. We compare ProtoShotXAI to the state-of-the-art XAI approaches on MNIST, Omniglot, and ImageNet to demonstrate, both quantitatively and qualitatively, that ProtoShotXAI provides more flexibility for model exploration. Finally, ProtoShotXAI also demonstrates novel explainabilty and detectabilty on adversarial samples.