 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGold Exploration using Representations from a Multispectral Autoencoder
Feb 06, 2026Satellite imagery is employed for large-scale prospectivity mapping due to the high cost and typically limited availability of on-site mineral exploration data. In this work, we present a proof-of-concept framework that leverages generative representations learned from multispectral Sentinel-2 imagery to identify gold-bearing regions from space. An autoencoder foundation model, called Isometric, which is pretrained on the large-scale FalconSpace-S2 v1.0 dataset, produces information-dense spectral-spatial representations that serve as inputs to a lightweight XGBoost classifier. We compare this representation-based approach with a raw spectral input baseline using a dataset of 63 Sentinel-2 images from known gold and non-gold locations. The proposed method improves patch-level accuracy from 0.51 to 0.68 and image-level accuracy from 0.55 to 0.73, demonstrating that generative embeddings capture transferable mineralogical patterns even with limited labeled data. These results highlight the potential of foundation-model representations to make mineral exploration more efficient, scalable, and globally applicable.
MAGNETO: Edge AI for Human Activity Recognition -- Privacy and Personalization
Feb 14, 2024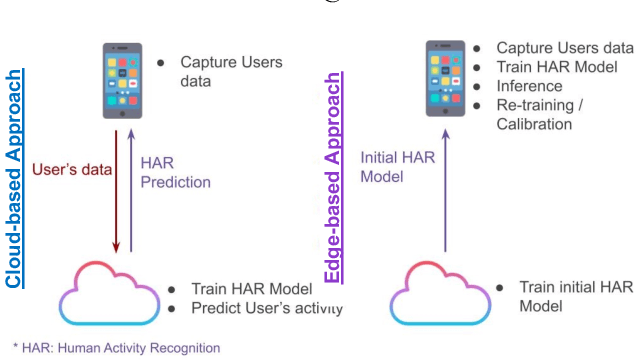
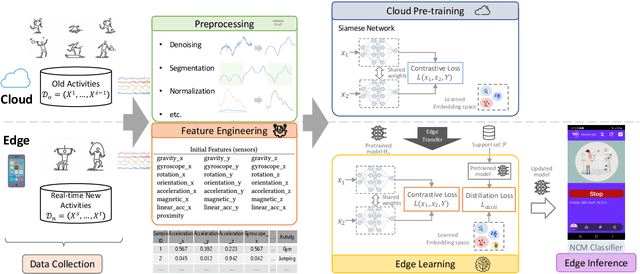
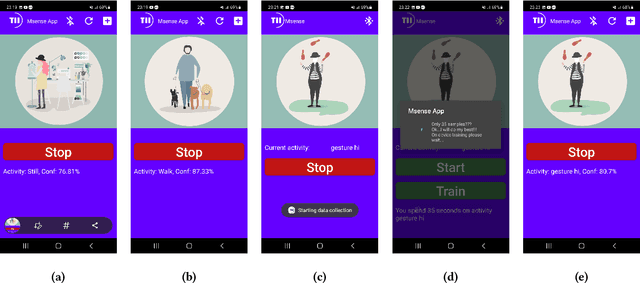
Human activity recognition (HAR) is a well-established field, significantly advanced by modern machine learning (ML) techniques. While companies have successfully integrated HAR into consumer products, they typically rely on a predefined activity set, which limits personalizations at the user level (edge devices). Despite advancements in Incremental Learning for updating models with new data, this often occurs on the Cloud, necessitating regular data transfers between cloud and edge devices, thus leading to data privacy issues. In this paper, we propose MAGNETO, an Edge AI platform that pushes HAR tasks from the Cloud to the Edge. MAGNETO allows incremental human activity learning directly on the Edge devices, without any data exchange with the Cloud. This enables strong privacy guarantees, low processing latency, and a high degree of personalization for users. In particular, we demonstrate MAGNETO in an Android device, validating the whole pipeline from data collection to result visualization.
A Latent Space Metric for Enhancing Prediction Confidence in Earth Observation Data
Jan 30, 2024This study presents a new approach for estimating confidence in machine learning model predictions, specifically in regression tasks utilizing Earth Observation (EO) data, with a particular focus on mosquito abundance (MA) estimation. We take advantage of a Variational AutoEncoder architecture, to derive a confidence metric by the latent space representations of EO datasets. This methodology is pivotal in establishing a correlation between the Euclidean distance in latent representations and the Absolute Error (AE) in individual MA predictions. Our research focuses on EO datasets from the Veneto region in Italy and the Upper Rhine Valley in Germany, targeting areas significantly affected by mosquito populations. A key finding is a notable correlation of 0.46 between the AE of MA predictions and the proposed confidence metric. This correlation signifies a robust, new metric for quantifying the reliability and enhancing the trustworthiness of the AI model's predictions in the context of both EO data analysis and mosquito abundance studies.
Practical Insights on Incremental Learning of New Human Physical Activity on the Edge
Aug 22, 2023Edge Machine Learning (Edge ML), which shifts computational intelligence from cloud-based systems to edge devices, is attracting significant interest due to its evident benefits including reduced latency, enhanced data privacy, and decreased connectivity reliance. While these advantages are compelling, they introduce unique challenges absent in traditional cloud-based approaches. In this paper, we delve into the intricacies of Edge-based learning, examining the interdependencies among: (i) constrained data storage on Edge devices, (ii) limited computational power for training, and (iii) the number of learning classes. Through experiments conducted using our MAGNETO system, that focused on learning human activities via data collected from mobile sensors, we highlight these challenges and offer valuable perspectives on Edge ML.
On Handling Catastrophic Forgetting for Incremental Learning of Human Physical Activity on the Edge
Feb 18, 2023



Human activity recognition (HAR) has been a classic research problem. In particular, with recent machine learning (ML) techniques, the recognition task has been largely investigated by companies and integrated into their products for customers. However, most of them apply a predefined activity set and conduct the learning process on the cloud, hindering specific personalizations from end users (i.e., edge devices). Even though recent progress in Incremental Learning allows learning new-class data on the fly, the learning process is generally conducted on the cloud, requiring constant data exchange between cloud and edge devices, thus leading to data privacy issues. In this paper, we propose PILOTE, which pushes the incremental learning process to the extreme edge, while providing reliable data privacy and practical utility, e.g., low processing latency, personalization, etc. In particular, we consider the practical challenge of extremely limited data during the incremental learning process on edge, where catastrophic forgetting is required to be handled in a practical way. We validate PILOTE with extensive experiments on human activity data collected from mobile sensors. The results show PILOTE can work on edge devices with extremely limited resources while providing reliable performance.
The Price of Local Fairness in Multistage Selection
Jun 15, 2019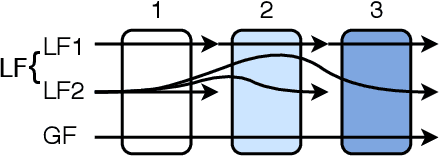
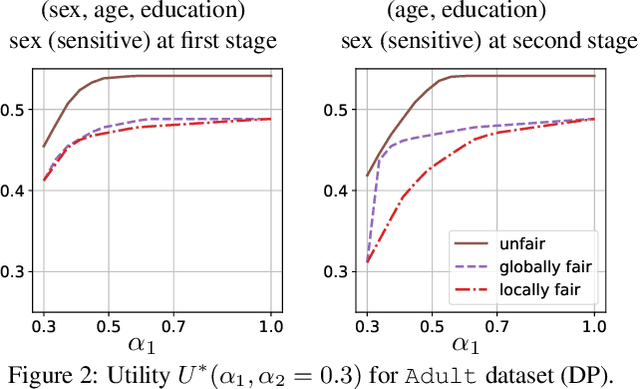
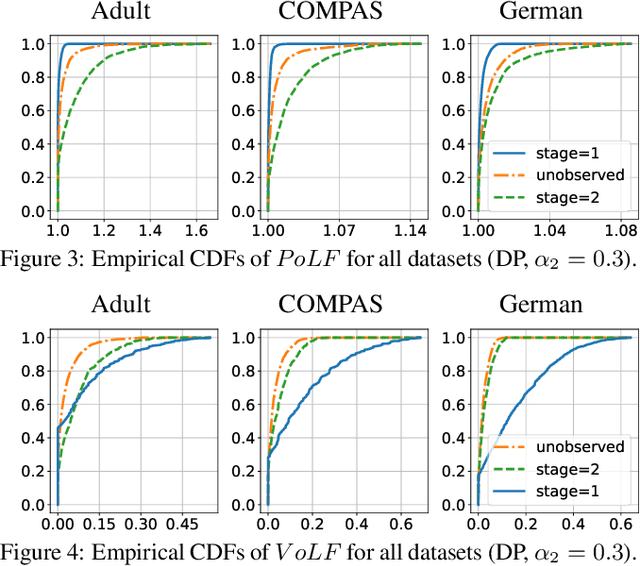
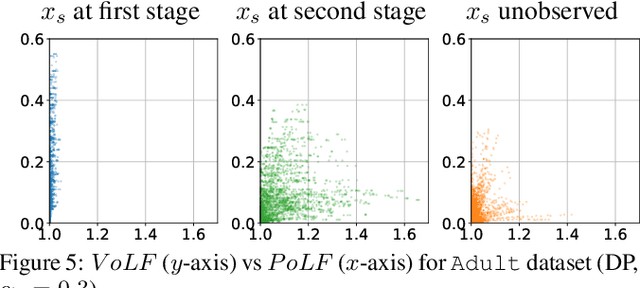
The rise of algorithmic decision making led to active researches on how to define and guarantee fairness, mostly focusing on one-shot decision making. In several important applications such as hiring, however, decisions are made in multiple stage with additional information at each stage. In such cases, fairness issues remain poorly understood. In this paper we study fairness in $k$-stage selection problems where additional features are observed at every stage. We first introduce two fairness notions, local (per stage) and global (final stage) fairness, that extend the classical fairness notions to the $k$-stage setting. We propose a simple model based on a probabilistic formulation and show that the locally and globally fair selections that maximize precision can be computed via a linear program. We then define the price of local fairness to measure the loss of precision induced by local constraints; and investigate theoretically and empirically this quantity. In particular, our experiments show that the price of local fairness is generally smaller when the sensitive attribute is observed at the first stage; but globally fair selections are more locally fair when the sensitive attribute is observed at the second stage---hence in both cases it is often possible to have a selection that has a small price of local fairness and is close to locally fair.
Variational Information Bottleneck for Unsupervised Clustering: Deep Gaussian Mixture Embedding
May 28, 2019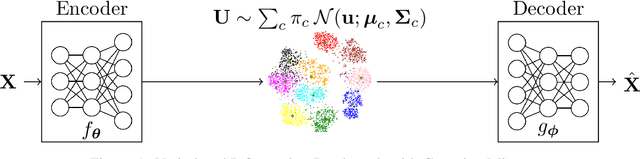
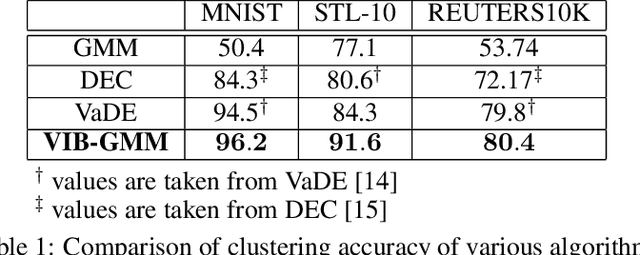
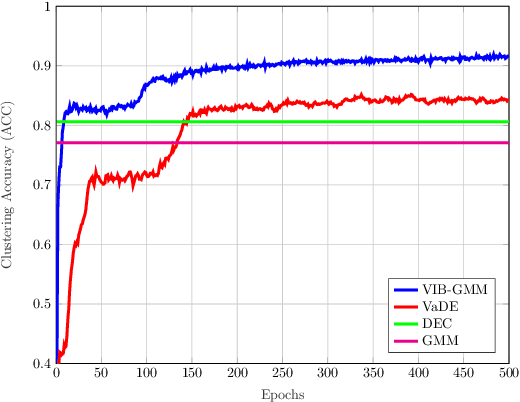
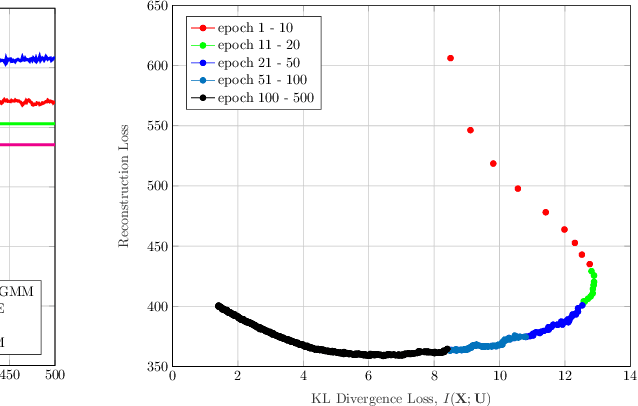
In this paper, we develop an unsupervised generative clustering framework that combines variational information bottleneck and the Gaussian Mixture Model. Specifically, in our approach we use the variational information bottleneck method and model the latent space as a mixture of Gaussians. We derive a bound on the cost function of our model that generalizes the evidence lower bound (ELBO); and provide a variational inference type algorithm that allows to compute it. In the algorithm, the coders' mappings are parametrized using neural networks and the bound is approximated by Markov sampling and optimized with stochastic gradient descent. Numerical results on real datasets are provided to support the efficiency of our method.