 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile asymmetric multi-legged locomotion: contact planning via geometric mechanics and spin model duality
Feb 09, 2026Legged robot research is presently focused on bipedal or quadrupedal robots, despite capabilities to build robots with many more legs to potentially improve locomotion performance. This imbalance is not necessarily due to hardware limitations, but rather to the absence of principled control frameworks that explain when and how additional legs improve locomotion performance. In multi-legged systems, coordinating many simultaneous contacts introduces a severe curse of dimensionality that challenges existing modeling and control approaches. As an alternative, multi-legged robots are typically controlled using low-dimensional gaits originally developed for bipeds or quadrupeds. These strategies fail to exploit the new symmetries and control opportunities that emerge in higher-dimensional systems. In this work, we develop a principled framework for discovering new control structures in multi-legged locomotion. We use geometric mechanics to reduce contact-rich locomotion planning to a graph optimization problem, and propose a spin model duality framework from statistical mechanics to exploit symmetry breaking and guide optimal gait reorganization. Using this approach, we identify an asymmetric locomotion strategy for a hexapod robot that achieves a forward speed of 0.61 body lengths per cycle (a 50% improvement over conventional gaits). The resulting asymmetry appears at both the control and hardware levels. At the control level, the body orientation oscillates asymmetrically between fast clockwise and slow counterclockwise turning phases for forward locomotion. At the hardware level, two legs on the same side remain unactuated and can be replaced with rigid parts without degrading performance. Numerical simulations and robophysical experiments validate the framework and reveal novel locomotion behaviors that emerge from symmetry reforming in high-dimensional embodied systems.
Automatic Environment Shaping is the Next Frontier in RL
Jul 23, 2024Many roboticists dream of presenting a robot with a task in the evening and returning the next morning to find the robot capable of solving the task. What is preventing us from achieving this? Sim-to-real reinforcement learning (RL) has achieved impressive performance on challenging robotics tasks, but requires substantial human effort to set up the task in a way that is amenable to RL. It's our position that algorithmic improvements in policy optimization and other ideas should be guided towards resolving the primary bottleneck of shaping the training environment, i.e., designing observations, actions, rewards and simulation dynamics. Most practitioners don't tune the RL algorithm, but other environment parameters to obtain a desirable controller. We posit that scaling RL to diverse robotic tasks will only be achieved if the community focuses on automating environment shaping procedures.
Learning Force Control for Legged Manipulation
May 02, 2024Controlling contact forces during interactions is critical for locomotion and manipulation tasks. While sim-to-real reinforcement learning (RL) has succeeded in many contact-rich problems, current RL methods achieve forceful interactions implicitly without explicitly regulating forces. We propose a method for training RL policies for direct force control without requiring access to force sensing. We showcase our method on a whole-body control platform of a quadruped robot with an arm. Such force control enables us to perform gravity compensation and impedance control, unlocking compliant whole-body manipulation. The learned whole-body controller with variable compliance makes it intuitive for humans to teleoperate the robot by only commanding the manipulator, and the robot's body adjusts automatically to achieve the desired position and force. Consequently, a human teleoperator can easily demonstrate a wide variety of loco-manipulation tasks. To the best of our knowledge, we provide the first deployment of learned whole-body force control in legged manipulators, paving the way for more versatile and adaptable legged robots.
Learning to See Physical Properties with Active Sensing Motor Policies
Nov 02, 2023



Knowledge of terrain's physical properties inferred from color images can aid in making efficient robotic locomotion plans. However, unlike image classification, it is unintuitive for humans to label image patches with physical properties. Without labeled data, building a vision system that takes as input the observed terrain and predicts physical properties remains challenging. We present a method that overcomes this challenge by self-supervised labeling of images captured by robots during real-world traversal with physical property estimators trained in simulation. To ensure accurate labeling, we introduce Active Sensing Motor Policies (ASMP), which are trained to explore locomotion behaviors that increase the accuracy of estimating physical parameters. For instance, the quadruped robot learns to swipe its foot against the ground to estimate the friction coefficient accurately. We show that the visual system trained with a small amount of real-world traversal data accurately predicts physical parameters. The trained system is robust and works even with overhead images captured by a drone despite being trained on data collected by cameras attached to a quadruped robot walking on the ground.
DribbleBot: Dynamic Legged Manipulation in the Wild
Apr 03, 2023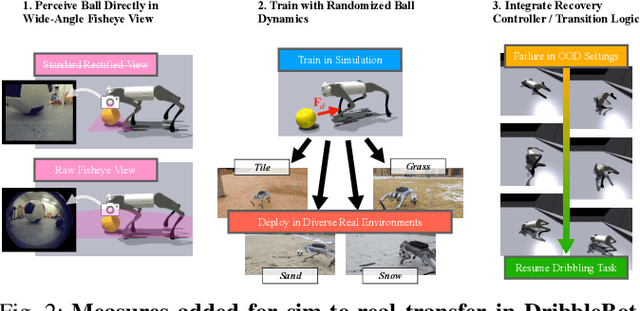
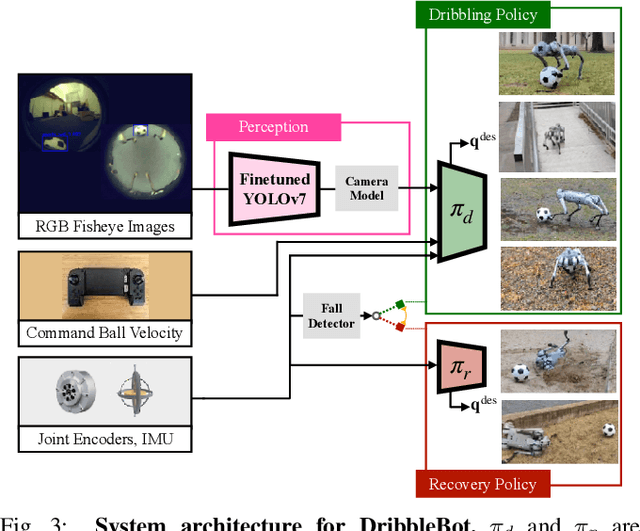
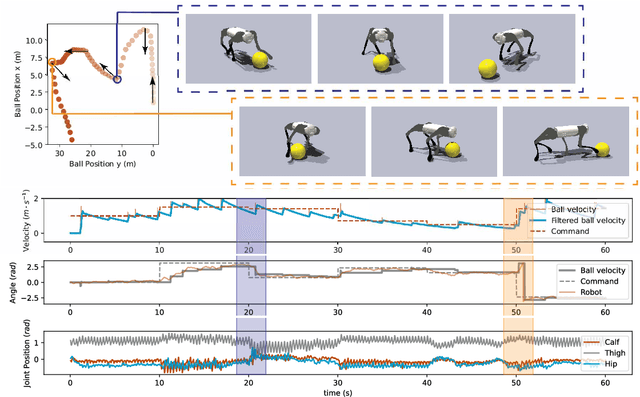
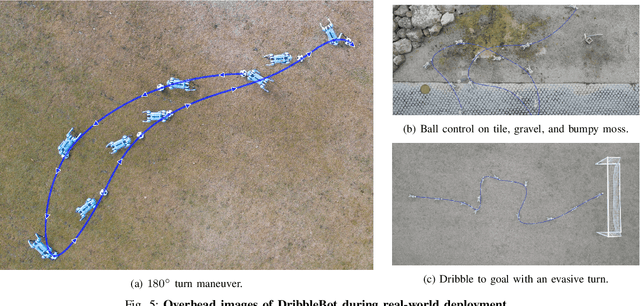
DribbleBot (Dexterous Ball Manipulation with a Legged Robot) is a legged robotic system that can dribble a soccer ball under the same real-world conditions as humans (i.e., in-the-wild). We adopt the paradigm of training policies in simulation using reinforcement learning and transferring them into the real world. We overcome critical challenges of accounting for variable ball motion dynamics on different terrains and perceiving the ball using body-mounted cameras under the constraints of onboard computing. Our results provide evidence that current quadruped platforms are well-suited for studying dynamic whole-body control problems involving simultaneous locomotion and manipulation directly from sensory observations.
Learning to Jump from Pixels
Oct 28, 2021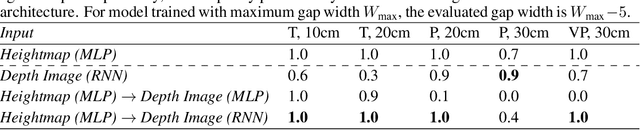
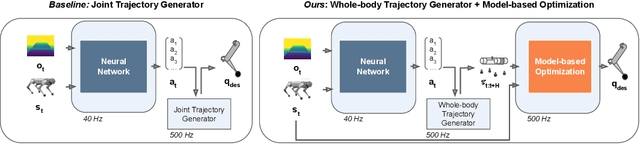
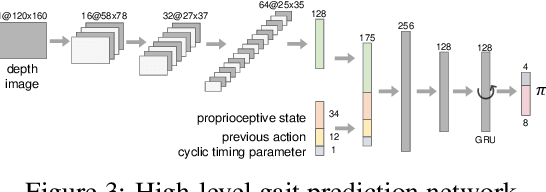
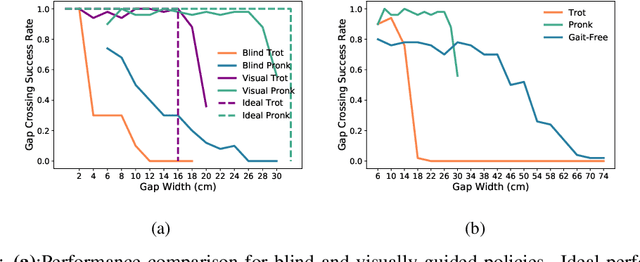
Today's robotic quadruped systems can robustly walk over a diverse range of rough but continuous terrains, where the terrain elevation varies gradually. Locomotion on discontinuous terrains, such as those with gaps or obstacles, presents a complementary set of challenges. In discontinuous settings, it becomes necessary to plan ahead using visual inputs and to execute agile behaviors beyond robust walking, such as jumps. Such dynamic motion results in significant motion of onboard sensors, which introduces a new set of challenges for real-time visual processing. The requirement for agility and terrain awareness in this setting reinforces the need for robust control. We present Depth-based Impulse Control (DIC), a method for synthesizing highly agile visually-guided locomotion behaviors. DIC affords the flexibility of model-free learning but regularizes behavior through explicit model-based optimization of ground reaction forces. We evaluate the proposed method both in simulation and in the real world.