 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Multilabel Imbalance with an Efficiency-Focused Approach Using Diffusion Model-Generated Synthetic Samples
Jan 18, 2025Predictive models trained on imbalanced data tend to produce biased results. This problem is exacerbated when there is not just one output label, but a set of them. This is the case for multilabel learning (MLL) algorithms used to classify patterns, rank labels, or learn the distribution of outputs. Many solutions have been proposed in the literature. The one that can be applied universally, independent of the algorithm used to build the model, is data resampling. The generation of new instances associated with minority labels, so that empty areas of the feature space are filled, helps to improve the obtained models. The quality of these new instances depends on the algorithm used to generate them. In this paper, a diffusion model tailored to produce new instances for MLL data, called MLDM (\textit{MultiLabel Diffusion Model}), is proposed. Diffusion models have been mainly used to generate artificial images and videos. Our proposed MLDM is based on this type of models. The experiments conducted compare MLDM with several other MLL resampling algorithms. The results show that MLDM is competitive while it improves efficiency.
PARDINUS: Weakly supervised discarding of photo-trapping empty images based on autoencoders
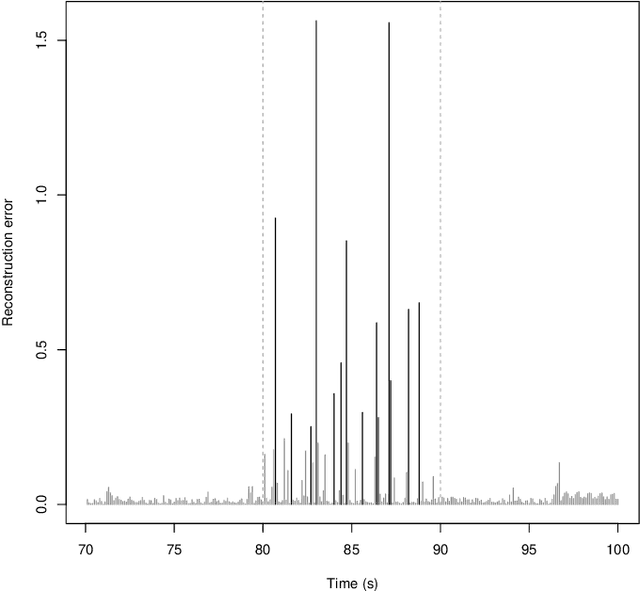
Dec 22, 2023Photo-trapping cameras are widely employed for wildlife monitoring. Those cameras take photographs when motion is detected to capture images where animals appear. A significant portion of these images are empty - no wildlife appears in the image. Filtering out those images is not a trivial task since it requires hours of manual work from biologists. Therefore, there is a notable interest in automating this task. Automatic discarding of empty photo-trapping images is still an open field in the area of Machine Learning. Existing solutions often rely on state-of-the-art supervised convolutional neural networks that require the annotation of the images in the training phase. PARDINUS (Weakly suPervised discARDINg of photo-trapping empty images based on aUtoencoderS) is constructed on the foundation of weakly supervised learning and proves that this approach equals or even surpasses other fully supervised methods that require further labeling work.
mldr.resampling: Efficient Reference Implementations of Multilabel Resampling Algorithms
May 30, 2023Resampling algorithms are a useful approach to deal with imbalanced learning in multilabel scenarios. These methods have to deal with singularities in the multilabel data, such as the occurrence of frequent and infrequent labels in the same instance. Implementations of these methods are sometimes limited to the pseudocode provided by their authors in a paper. This Original Software Publication presents mldr.resampling, a software package that provides reference implementations for eleven multilabel resampling methods, with an emphasis on efficiency since these algorithms are usually time-consuming.
EvoAAA: An evolutionary methodology for automated eural autoencoder architecture search
Jan 15, 2023Machine learning models work better when curated features are provided to them. Feature engineering methods have been usually used as a preprocessing step to obtain or build a proper feature set. In late years, autoencoders (a specific type of symmetrical neural network) have been widely used to perform representation learning, proving their competitiveness against classical feature engineering algorithms. The main obstacle in the use of autoencoders is finding a good architecture, a process that most experts confront manually. An automated autoencoder architecture search procedure, based on evolutionary methods, is proposed in this paper. The methodology is tested against nine heterogeneous data sets. The obtained results show the ability of this approach to find better architectures, able to concentrate most of the useful information in a minimized coding, in a reduced time.
Reducing Data Complexity using Autoencoders with Class-informed Loss Functions
Nov 11, 2021

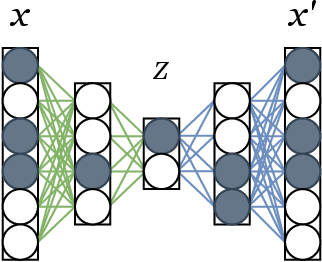
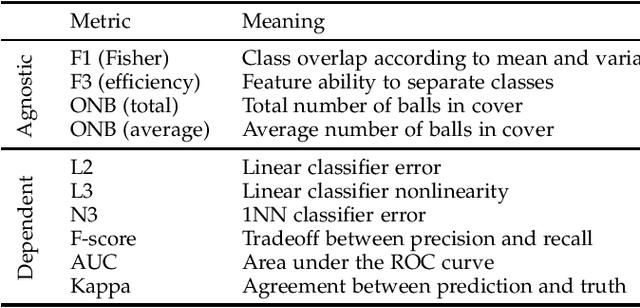
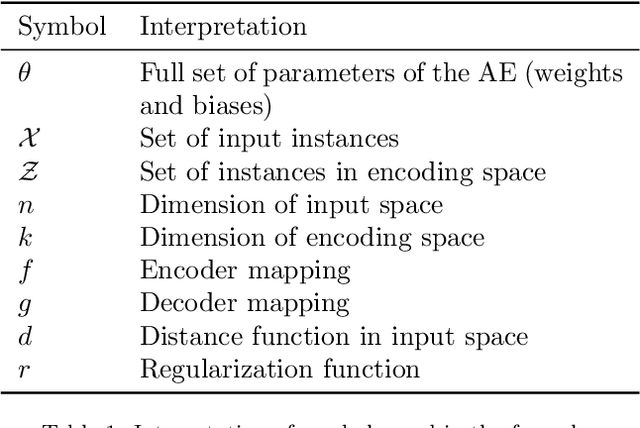
Available data in machine learning applications is becoming increasingly complex, due to higher dimensionality and difficult classes. There exists a wide variety of approaches to measuring complexity of labeled data, according to class overlap, separability or boundary shapes, as well as group morphology. Many techniques can transform the data in order to find better features, but few focus on specifically reducing data complexity. Most data transformation methods mainly treat the dimensionality aspect, leaving aside the available information within class labels which can be useful when classes are somehow complex. This paper proposes an autoencoder-based approach to complexity reduction, using class labels in order to inform the loss function about the adequacy of the generated variables. This leads to three different new feature learners, Scorer, Skaler and Slicer. They are based on Fisher's discriminant ratio, the Kullback-Leibler divergence and least-squares support vector machines, respectively. They can be applied as a preprocessing stage for a binary classification problem. A thorough experimentation across a collection of 27 datasets and a range of complexity and classification metrics shows that class-informed autoencoders perform better than 4 other popular unsupervised feature extraction techniques, especially when the final objective is using the data for a classification task.
An analysis on the use of autoencoders for representation learning: fundamentals, learning task case studies, explainability and challenges
May 21, 2020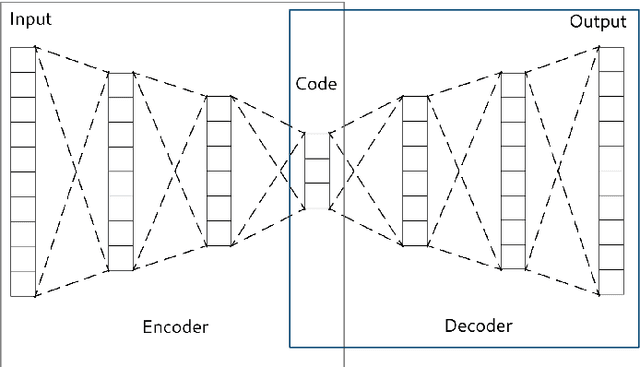
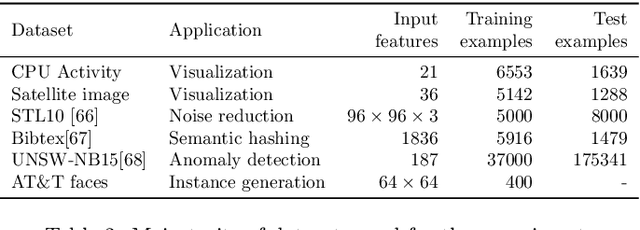
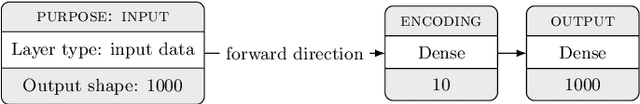
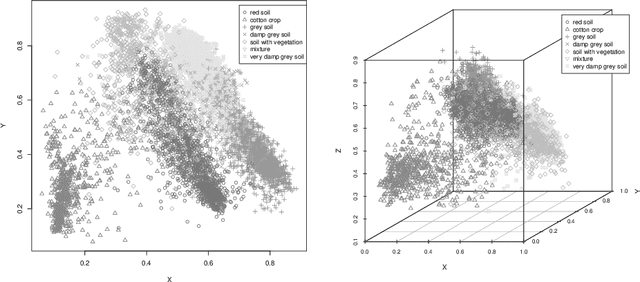
In many machine learning tasks, learning a good representation of the data can be the key to building a well-performant solution. This is because most learning algorithms operate with the features in order to find models for the data. For instance, classification performance can improve if the data is mapped to a space where classes are easily separated, and regression can be facilitated by finding a manifold of data in the feature space. As a general rule, features are transformed by means of statistical methods such as principal component analysis, or manifold learning techniques such as Isomap or locally linear embedding. From a plethora of representation learning methods, one of the most versatile tools is the autoencoder. In this paper we aim to demonstrate how to influence its learned representations to achieve the desired learning behavior. To this end, we present a series of learning tasks: data embedding for visualization, image denoising, semantic hashing, detection of abnormal behaviors and instance generation. We model them from the representation learning perspective, following the state of the art methodologies in each field. A solution is proposed for each task employing autoencoders as the only learning method. The theoretical developments are put into practice using a selection of datasets for the different problems and implementing each solution, followed by a discussion of the results in each case study and a brief explanation of other six learning applications. We also explore the current challenges and approaches to explainability in the context of autoencoders. All of this helps conclude that, thanks to alterations in their structure as well as their objective function, autoencoders may be the core of a possible solution to many problems which can be modeled as a transformation of the feature space.
A Showcase of the Use of Autoencoders in Feature Learning Applications
May 08, 2020

Autoencoders are techniques for data representation learning based on artificial neural networks. Differently to other feature learning methods which may be focused on finding specific transformations of the feature space, they can be adapted to fulfill many purposes, such as data visualization, denoising, anomaly detection and semantic hashing. This work presents these applications and provides details on how autoencoders can perform them, including code samples making use of an R package with an easy-to-use interface for autoencoder design and training, \texttt{ruta}. Along the way, the explanations on how each learning task has been achieved are provided with the aim to help the reader design their own autoencoders for these or other objectives.
* This manuscript was accepted as conference paper in IWINAC 2019. The final authenticated publication is available online at https://doi.org/10.1007/978-3-030-19651-6_40
A snapshot on nonstandard supervised learning problems: taxonomy, relationships and methods
Nov 29, 2018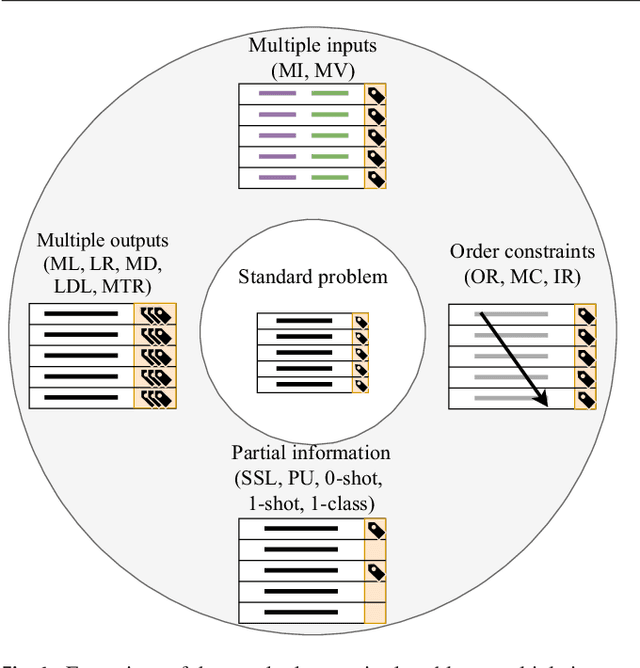


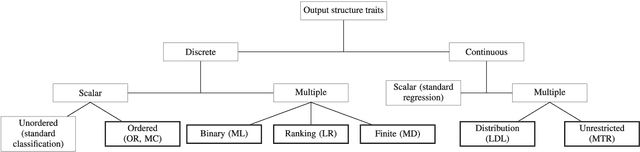
Machine learning is a field which studies how machines can alter and adapt their behavior, improving their actions according to the information they are given. This field is subdivided into multiple areas, among which the best known are supervised learning (e.g. classification and regression) and unsupervised learning (e.g. clustering and association rules). Within supervised learning, most studies and research are focused on well known standard tasks, such as binary classification, multiclass classification and regression with one dependent variable. However, there are many other less known problems. These are what we generically call nonstandard supervised learning problems. The literature about them is much more sparse, and each study is directed to a specific task. Therefore, the definitions, relations and applications of this kind of learners are hard to find. The goal of this paper is to provide the reader with a broad view on the distinct variations of nonstandard supervised problems. A comprehensive taxonomy summarizing their traits is proposed. A review of the common approaches followed to accomplish them and their main applications is provided as well.
AEkNN: An AutoEncoder kNN-based classifier with built-in dimensionality reduction
Mar 09, 2018


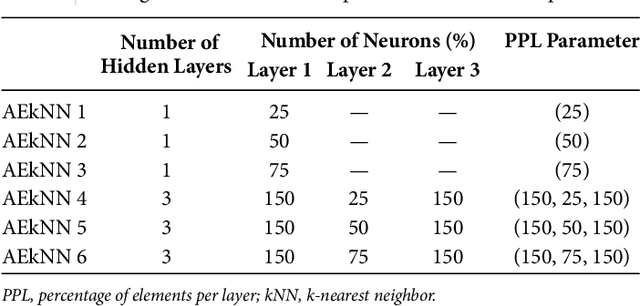
High dimensionality, i.e. data having a large number of variables, tends to be a challenge for most machine learning tasks, including classification. A classifier usually builds a model representing how a set of inputs explain the outputs. The larger is the set of inputs and/or outputs, the more complex would be that model. There is a family of classification algorithms, known as lazy learning methods, which does not build a model. One of the best known members of this family is the kNN algorithm. Its strategy relies on searching a set of nearest neighbors, using the input variables as position vectors and computing distances among them. These distances loss significance in high-dimensional spaces. Therefore kNN, as many other classifiers, tends to worse its performance as the number of input variables grows. In this work AEkNN, a new kNN-based algorithm with built-in dimensionality reduction, is presented. Aiming to obtain a new representation of the data, having a lower dimensionality but with more informational features, AEkNN internally uses autoencoders. From this new feature vectors the computed distances should be more significant, thus providing a way to choose better neighbors. A experimental evaluation of the new proposal is conducted, analyzing several configurations and comparing them against the classical kNN algorithm. The obtained conclusions demonstrate that AEkNN offers better results in predictive and runtime performance.
Dealing with Difficult Minority Labels in Imbalanced Mutilabel Data Sets
Feb 14, 2018
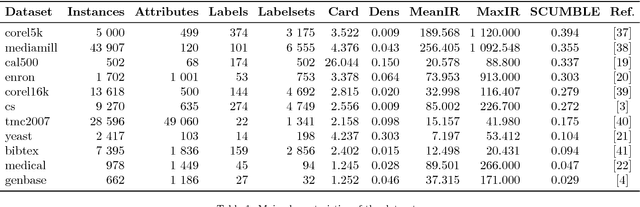
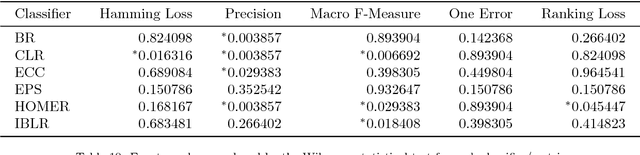

Multilabel classification is an emergent data mining task with a broad range of real world applications. Learning from imbalanced multilabel data is being deeply studied latterly, and several resampling methods have been proposed in the literature. The unequal label distribution in most multilabel datasets, with disparate imbalance levels, could be a handicap while learning new classifiers. In addition, this characteristic challenges many of the existent preprocessing algorithms. Furthermore, the concurrence between imbalanced labels can make harder the learning from certain labels. These are what we call \textit{difficult} labels. In this work, the problem of difficult labels is deeply analyzed, its influence in multilabel classifiers is studied, and a novel way to solve this problem is proposed. Specific metrics to assess this trait in multilabel datasets, called \textit{SCUMBLE} (\textit{Score of ConcUrrence among iMBalanced LabEls}) and \textit{SCUMBLELbl}, are presented along with REMEDIAL (\textit{REsampling MultilabEl datasets by Decoupling highly ImbAlanced Labels}), a new algorithm aimed to relax label concurrence. How to deal with this problem using the R mldr package is also outlined.