 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDealing with Difficult Minority Labels in Imbalanced Mutilabel Data Sets
Paper and Code
Feb 14, 2018
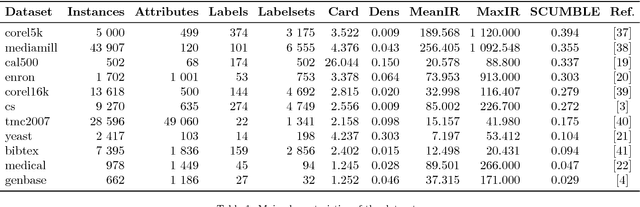
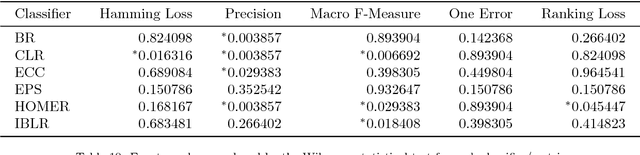

Multilabel classification is an emergent data mining task with a broad range of real world applications. Learning from imbalanced multilabel data is being deeply studied latterly, and several resampling methods have been proposed in the literature. The unequal label distribution in most multilabel datasets, with disparate imbalance levels, could be a handicap while learning new classifiers. In addition, this characteristic challenges many of the existent preprocessing algorithms. Furthermore, the concurrence between imbalanced labels can make harder the learning from certain labels. These are what we call \textit{difficult} labels. In this work, the problem of difficult labels is deeply analyzed, its influence in multilabel classifiers is studied, and a novel way to solve this problem is proposed. Specific metrics to assess this trait in multilabel datasets, called \textit{SCUMBLE} (\textit{Score of ConcUrrence among iMBalanced LabEls}) and \textit{SCUMBLELbl}, are presented along with REMEDIAL (\textit{REsampling MultilabEl datasets by Decoupling highly ImbAlanced Labels}), a new algorithm aimed to relax label concurrence. How to deal with this problem using the R mldr package is also outlined.