 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemldr.resampling: Efficient Reference Implementations of Multilabel Resampling Algorithms
May 30, 2023Resampling algorithms are a useful approach to deal with imbalanced learning in multilabel scenarios. These methods have to deal with singularities in the multilabel data, such as the occurrence of frequent and infrequent labels in the same instance. Implementations of these methods are sometimes limited to the pseudocode provided by their authors in a paper. This Original Software Publication presents mldr.resampling, a software package that provides reference implementations for eleven multilabel resampling methods, with an emphasis on efficiency since these algorithms are usually time-consuming.
EvoAAA: An evolutionary methodology for automated eural autoencoder architecture search
Jan 15, 2023Machine learning models work better when curated features are provided to them. Feature engineering methods have been usually used as a preprocessing step to obtain or build a proper feature set. In late years, autoencoders (a specific type of symmetrical neural network) have been widely used to perform representation learning, proving their competitiveness against classical feature engineering algorithms. The main obstacle in the use of autoencoders is finding a good architecture, a process that most experts confront manually. An automated autoencoder architecture search procedure, based on evolutionary methods, is proposed in this paper. The methodology is tested against nine heterogeneous data sets. The obtained results show the ability of this approach to find better architectures, able to concentrate most of the useful information in a minimized coding, in a reduced time.
AEkNN: An AutoEncoder kNN-based classifier with built-in dimensionality reduction
Mar 09, 2018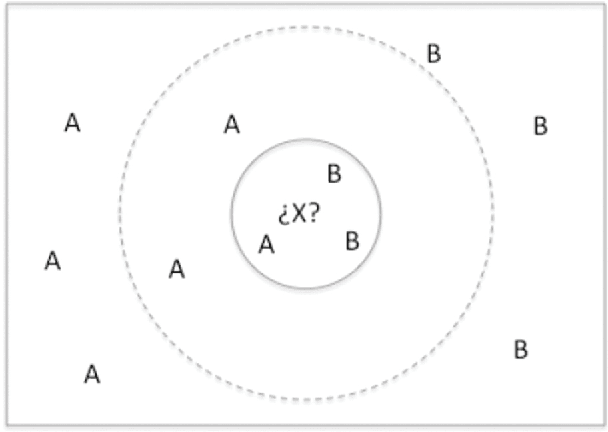


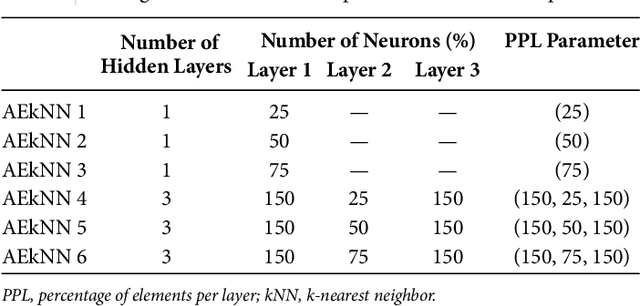
High dimensionality, i.e. data having a large number of variables, tends to be a challenge for most machine learning tasks, including classification. A classifier usually builds a model representing how a set of inputs explain the outputs. The larger is the set of inputs and/or outputs, the more complex would be that model. There is a family of classification algorithms, known as lazy learning methods, which does not build a model. One of the best known members of this family is the kNN algorithm. Its strategy relies on searching a set of nearest neighbors, using the input variables as position vectors and computing distances among them. These distances loss significance in high-dimensional spaces. Therefore kNN, as many other classifiers, tends to worse its performance as the number of input variables grows. In this work AEkNN, a new kNN-based algorithm with built-in dimensionality reduction, is presented. Aiming to obtain a new representation of the data, having a lower dimensionality but with more informational features, AEkNN internally uses autoencoders. From this new feature vectors the computed distances should be more significant, thus providing a way to choose better neighbors. A experimental evaluation of the new proposal is conducted, analyzing several configurations and comparing them against the classical kNN algorithm. The obtained conclusions demonstrate that AEkNN offers better results in predictive and runtime performance.
Dealing with Difficult Minority Labels in Imbalanced Mutilabel Data Sets
Feb 14, 2018
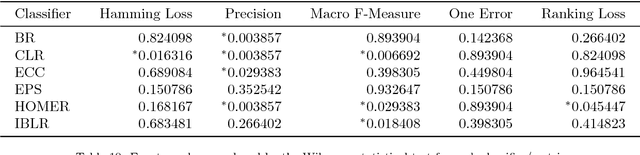

Multilabel classification is an emergent data mining task with a broad range of real world applications. Learning from imbalanced multilabel data is being deeply studied latterly, and several resampling methods have been proposed in the literature. The unequal label distribution in most multilabel datasets, with disparate imbalance levels, could be a handicap while learning new classifiers. In addition, this characteristic challenges many of the existent preprocessing algorithms. Furthermore, the concurrence between imbalanced labels can make harder the learning from certain labels. These are what we call \textit{difficult} labels. In this work, the problem of difficult labels is deeply analyzed, its influence in multilabel classifiers is studied, and a novel way to solve this problem is proposed. Specific metrics to assess this trait in multilabel datasets, called \textit{SCUMBLE} (\textit{Score of ConcUrrence among iMBalanced LabEls}) and \textit{SCUMBLELbl}, are presented along with REMEDIAL (\textit{REsampling MultilabEl datasets by Decoupling highly ImbAlanced Labels}), a new algorithm aimed to relax label concurrence. How to deal with this problem using the R mldr package is also outlined.
Tackling Multilabel Imbalance through Label Decoupling and Data Resampling Hybridization
Feb 14, 2018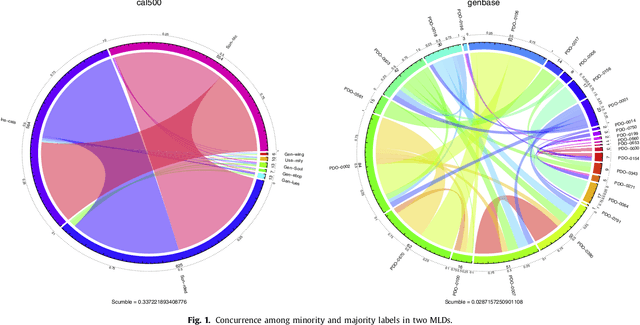
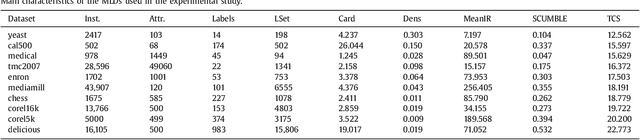
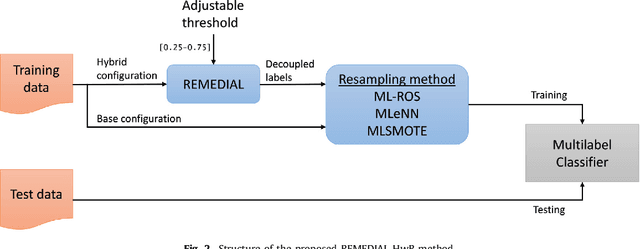
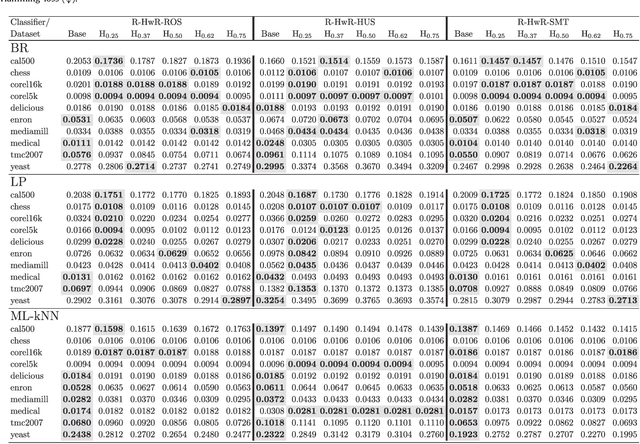
The learning from imbalanced data is a deeply studied problem in standard classification and, in recent times, also in multilabel classification. A handful of multilabel resampling methods have been proposed in late years, aiming to balance the labels distribution. However these methods have to face a new obstacle, specific for multilabel data, as is the joint appearance of minority and majority labels in the same data patterns. We proposed recently a new algorithm designed to decouple imbalanced labels concurring in the same instance, called REMEDIAL (\textit{REsampling MultilabEl datasets by Decoupling highly ImbAlanced Labels}). The goal of this work is to propose a procedure to hybridize this method with some of the best resampling algorithms available in the literature, including random oversampling, heuristic undersampling and synthetic sample generation techniques. These hybrid methods are then empirically analyzed, determining how their behavior is influenced by the label decoupling process. As a result, a noteworthy set of guidelines on the combined use of these techniques can be drawn from the conducted experimentation.
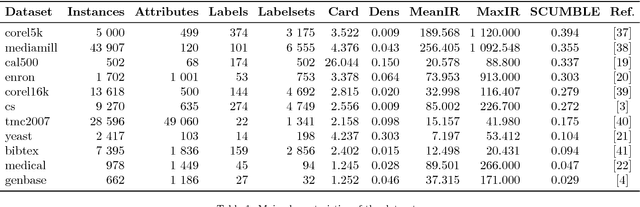
Tips, guidelines and tools for managing multi-label datasets: the mldr.datasets R package and the Cometa data repository
Feb 10, 2018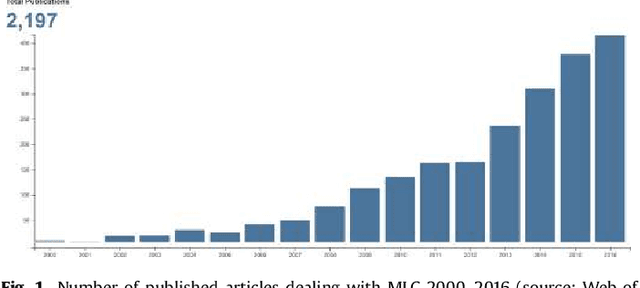

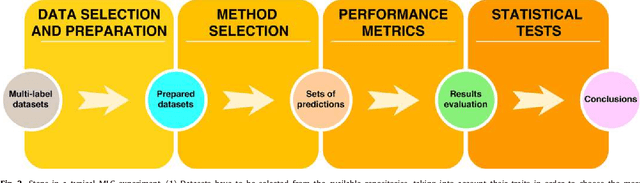
New proposals in the field of multi-label learning algorithms have been growing in number steadily over the last few years. The experimentation associated with each of them always goes through the same phases: selection of datasets, partitioning, training, analysis of results and, finally, comparison with existing methods. This last step is often hampered since it involves using exactly the same datasets, partitioned in the same way and using the same validation strategy. In this paper we present a set of tools whose objective is to facilitate the management of multi-label datasets, aiming to standardize the experimentation procedure. The two main tools are an R package, mldr.datasets, and a web repository with datasets, Cometa. Together, these tools will simplify the collection of datasets, their partitioning, documentation and export to multiple formats, among other functions. Some tips, recommendations and guidelines for a good experimental analysis of multi-label methods are also presented.