 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTips, guidelines and tools for managing multi-label datasets: the mldr.datasets R package and the Cometa data repository
Paper and Code
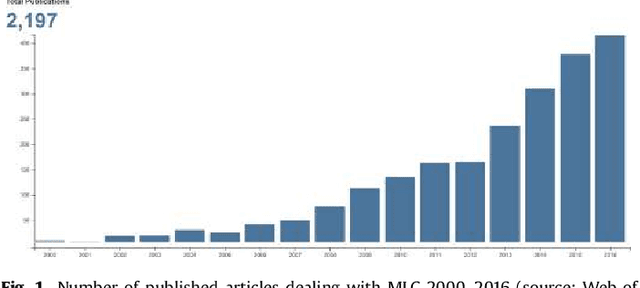

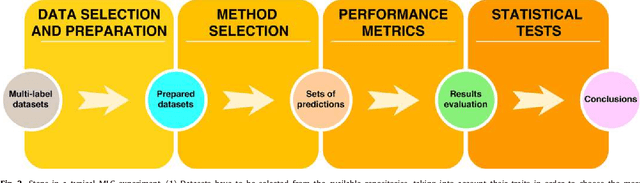
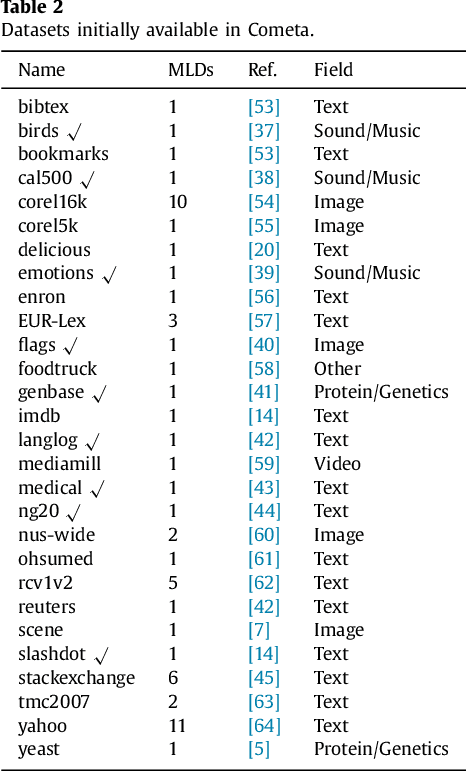
New proposals in the field of multi-label learning algorithms have been growing in number steadily over the last few years. The experimentation associated with each of them always goes through the same phases: selection of datasets, partitioning, training, analysis of results and, finally, comparison with existing methods. This last step is often hampered since it involves using exactly the same datasets, partitioned in the same way and using the same validation strategy. In this paper we present a set of tools whose objective is to facilitate the management of multi-label datasets, aiming to standardize the experimentation procedure. The two main tools are an R package, mldr.datasets, and a web repository with datasets, Cometa. Together, these tools will simplify the collection of datasets, their partitioning, documentation and export to multiple formats, among other functions. Some tips, recommendations and guidelines for a good experimental analysis of multi-label methods are also presented.