 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Multilabel Imbalance through Label Decoupling and Data Resampling Hybridization
Paper and Code
Feb 14, 2018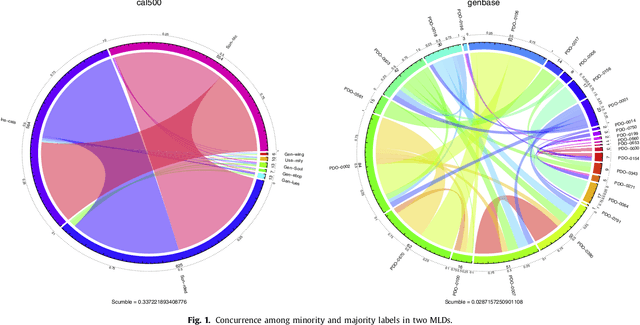
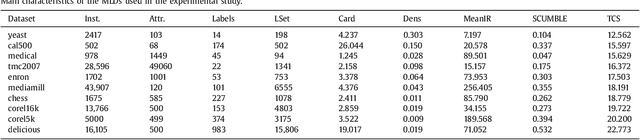
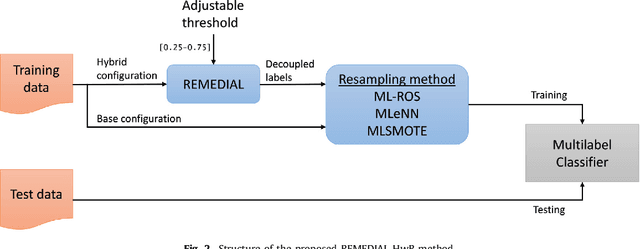
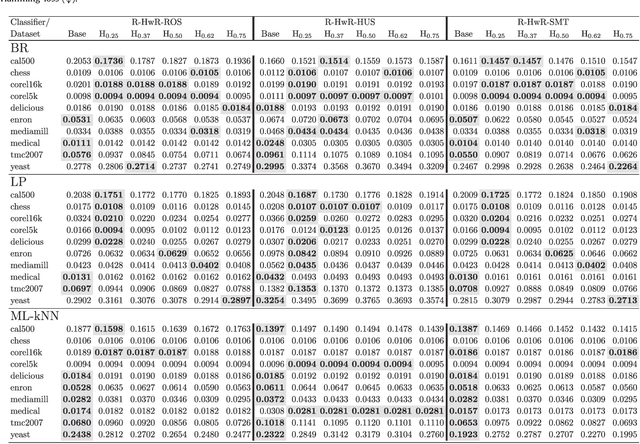
The learning from imbalanced data is a deeply studied problem in standard classification and, in recent times, also in multilabel classification. A handful of multilabel resampling methods have been proposed in late years, aiming to balance the labels distribution. However these methods have to face a new obstacle, specific for multilabel data, as is the joint appearance of minority and majority labels in the same data patterns. We proposed recently a new algorithm designed to decouple imbalanced labels concurring in the same instance, called REMEDIAL (\textit{REsampling MultilabEl datasets by Decoupling highly ImbAlanced Labels}). The goal of this work is to propose a procedure to hybridize this method with some of the best resampling algorithms available in the literature, including random oversampling, heuristic undersampling and synthetic sample generation techniques. These hybrid methods are then empirically analyzed, determining how their behavior is influenced by the label decoupling process. As a result, a noteworthy set of guidelines on the combined use of these techniques can be drawn from the conducted experimentation.