 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Constrained Cross-Resolution Enhancement Network for Optics-Guided Thermal UAV Image Super-Resolution
Jan 07, 2026Optics-guided thermal UAV image super-resolution has attracted significant research interest due to its potential in all-weather monitoring applications. However, existing methods typically compress optical features to match thermal feature dimensions for cross-modal alignment and fusion, which not only causes the loss of high-frequency information that is beneficial for thermal super-resolution, but also introduces physically inconsistent artifacts such as texture distortions and edge blurring by overlooking differences in the imaging physics between modalities. To address these challenges, we propose PCNet to achieve cross-resolution mutual enhancement between optical and thermal modalities, while physically constraining the optical guidance process via thermal conduction to enable robust thermal UAV image super-resolution. In particular, we design a Cross-Resolution Mutual Enhancement Module (CRME) to jointly optimize thermal image super-resolution and optical-to-thermal modality conversion, facilitating effective bidirectional feature interaction across resolutions while preserving high-frequency optical priors. Moreover, we propose a Physics-Driven Thermal Conduction Module (PDTM) that incorporates two-dimensional heat conduction into optical guidance, modeling spatially-varying heat conduction properties to prevent inconsistent artifacts. In addition, we introduce a temperature consistency loss that enforces regional distribution consistency and boundary gradient smoothness to ensure generated thermal images align with real-world thermal radiation principles. Extensive experiments on VGTSR2.0 and DroneVehicle datasets demonstrate that PCNet significantly outperforms state-of-the-art methods on both reconstruction quality and downstream tasks including semantic segmentation and object detection.
Improve Contrastive Clustering Performance by Multiple Fusing-Augmenting ViT Blocks
Nov 12, 2025



In the field of image clustering, the widely used contrastive learning networks improve clustering performance by maximizing the similarity between positive pairs and the dissimilarity of negative pairs of the inputs. Extant contrastive learning networks, whose two encoders often implicitly interact with each other by parameter sharing or momentum updating, may not fully exploit the complementarity and similarity of the positive pairs to extract clustering features from input data. To explicitly fuse the learned features of positive pairs, we design a novel multiple fusing-augmenting ViT blocks (MFAVBs) based on the excellent feature learning ability of Vision Transformers (ViT). Firstly, two preprocessed augmentions as positive pairs are separately fed into two shared-weight ViTs, then their output features are fused to input into a larger ViT. Secondly, the learned features are split into a pair of new augmented positive samples and passed to the next FAVBs, enabling multiple fusion and augmention through MFAVBs operations. Finally, the learned features are projected into both instance-level and clustering-level spaces to calculate the cross-entropy loss, followed by parameter updates by backpropagation to finalize the training process. To further enhance ability of the model to distinguish between similar images, our input data for the network we propose is preprocessed augmentions with features extracted from the CLIP pretrained model. Our experiments on seven public datasets demonstrate that MFAVBs serving as the backbone for contrastive clustering outperforms the state-of-the-art techniques in terms of clustering performance.
DeepFaceLIFT: Interpretable Personalized Models for Automatic Estimation of Self-Reported Pain
Aug 09, 2017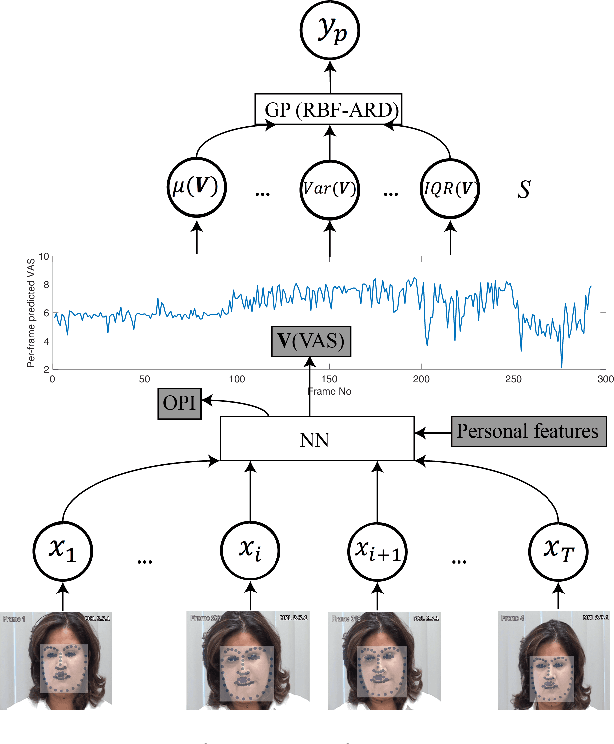
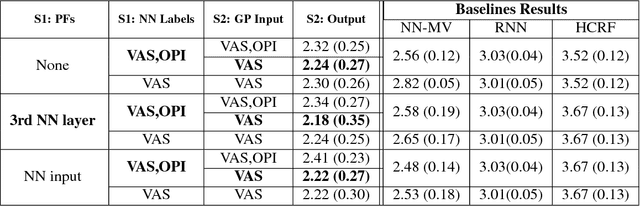
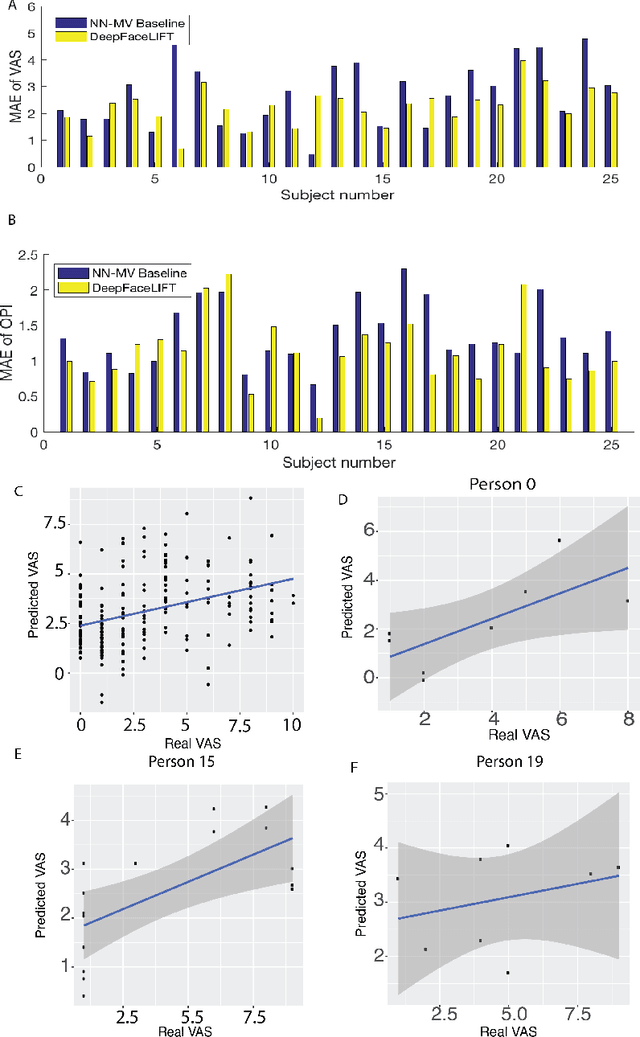
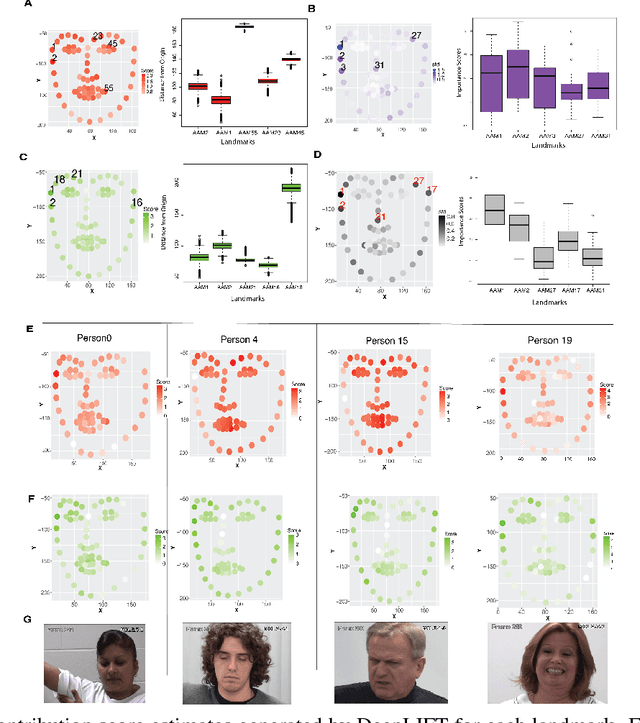
Previous research on automatic pain estimation from facial expressions has focused primarily on "one-size-fits-all" metrics (such as PSPI). In this work, we focus on directly estimating each individual's self-reported visual-analog scale (VAS) pain metric, as this is considered the gold standard for pain measurement. The VAS pain score is highly subjective and context-dependent, and its range can vary significantly among different persons. To tackle these issues, we propose a novel two-stage personalized model, named DeepFaceLIFT, for automatic estimation of VAS. This model is based on (1) Neural Network and (2) Gaussian process regression models, and is used to personalize the estimation of self-reported pain via a set of hand-crafted personal features and multi-task learning. We show on the benchmark dataset for pain analysis (The UNBC-McMaster Shoulder Pain Expression Archive) that the proposed personalized model largely outperforms the traditional, unpersonalized models: the intra-class correlation improves from a baseline performance of 19\% to a personalized performance of 35\% while also providing confidence in the model\textquotesingle s estimates -- in contrast to existing models for the target task. Additionally, DeepFaceLIFT automatically discovers the pain-relevant facial regions for each person, allowing for an easy interpretation of the pain-related facial cues.