 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTUM Autonomous Motorsport: An Autonomous Racing Software for the Indy Autonomous Challenge
May 31, 2022
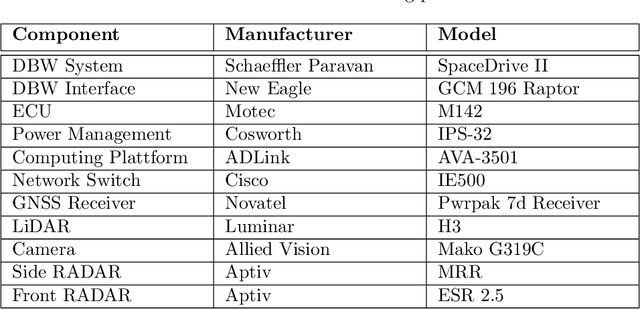
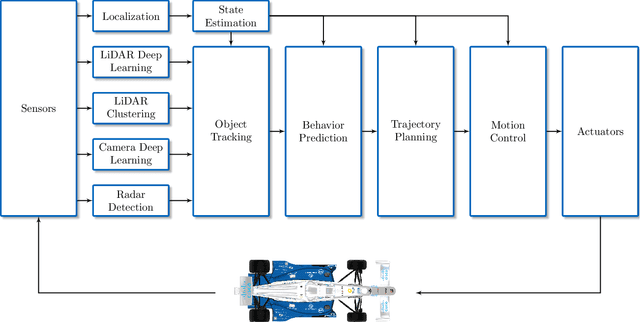
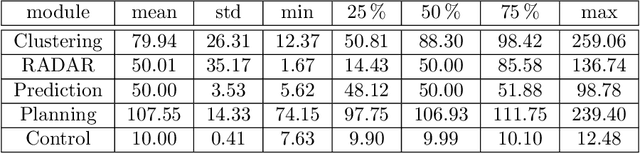
For decades, motorsport has been an incubator for innovations in the automotive sector and brought forth systems like disk brakes or rearview mirrors. Autonomous racing series such as Roborace, F1Tenth, or the Indy Autonomous Challenge (IAC) are envisioned as playing a similar role within the autonomous vehicle sector, serving as a proving ground for new technology at the limits of the autonomous systems capabilities. This paper outlines the software stack and approach of the TUM Autonomous Motorsport team for their participation in the Indy Autonomous Challenge, which holds two competitions: A single-vehicle competition on the Indianapolis Motor Speedway and a passing competition at the Las Vegas Motor Speedway. Nine university teams used an identical vehicle platform: A modified Indy Lights chassis equipped with sensors, a computing platform, and actuators. All the teams developed different algorithms for object detection, localization, planning, prediction, and control of the race cars. The team from TUM placed first in Indianapolis and secured second place in Las Vegas. During the final of the passing competition, the TUM team reached speeds and accelerations close to the limit of the vehicle, peaking at around 270 km/h and 28 ms2. This paper will present details of the vehicle hardware platform, the developed algorithms, and the workflow to test and enhance the software applied during the two-year project. We derive deep insights into the autonomous vehicle's behavior at high speed and high acceleration by providing a detailed competition analysis. Based on this, we deduce a list of lessons learned and provide insights on promising areas of future work based on the real-world evaluation of the displayed concepts.
Indy Autonomous Challenge -- Autonomous Race Cars at the Handling Limits
Feb 08, 2022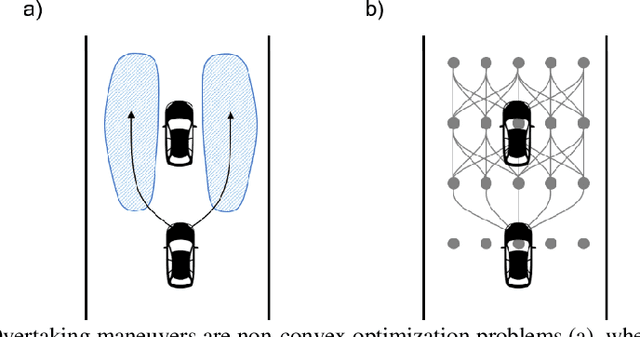
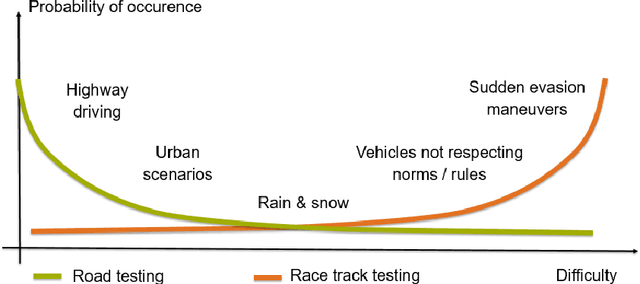

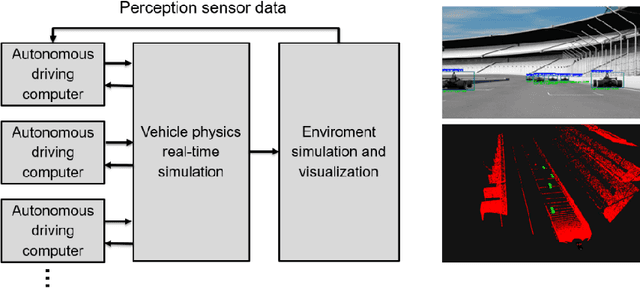
Motorsport has always been an enabler for technological advancement, and the same applies to the autonomous driving industry. The team TUM Auton-omous Motorsports will participate in the Indy Autonomous Challenge in Octo-ber 2021 to benchmark its self-driving software-stack by racing one out of ten autonomous Dallara AV-21 racecars at the Indianapolis Motor Speedway. The first part of this paper explains the reasons for entering an autonomous vehicle race from an academic perspective: It allows focusing on several edge cases en-countered by autonomous vehicles, such as challenging evasion maneuvers and unstructured scenarios. At the same time, it is inherently safe due to the motor-sport related track safety precautions. It is therefore an ideal testing ground for the development of autonomous driving algorithms capable of mastering the most challenging and rare situations. In addition, we provide insight into our soft-ware development workflow and present our Hardware-in-the-Loop simulation setup. It is capable of running simulations of up to eight autonomous vehicles in real time. The second part of the paper gives a high-level overview of the soft-ware architecture and covers our development priorities in building a high-per-formance autonomous racing software: maximum sensor detection range, relia-ble handling of multi-vehicle situations, as well as reliable motion control under uncertainty.
Radar Voxel Fusion for 3D Object Detection
Jun 26, 2021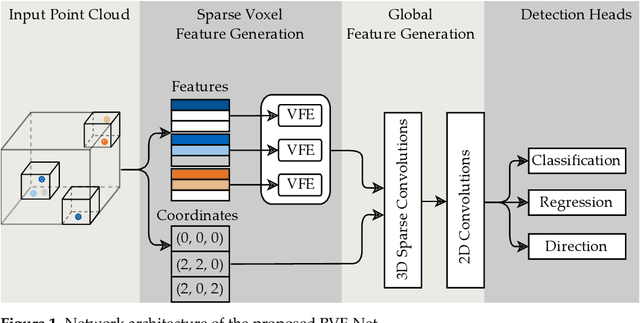

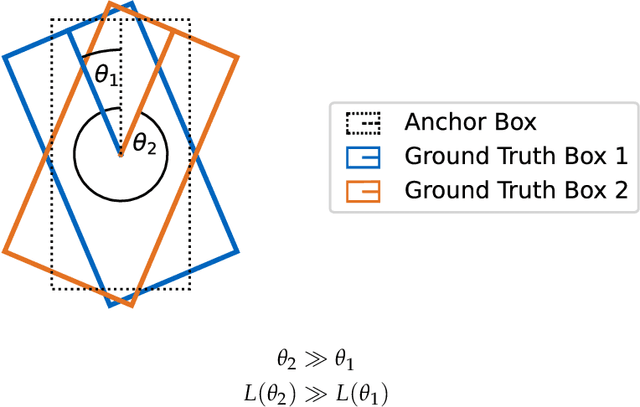

Automotive traffic scenes are complex due to the variety of possible scenarios, objects, and weather conditions that need to be handled. In contrast to more constrained environments, such as automated underground trains, automotive perception systems cannot be tailored to a narrow field of specific tasks but must handle an ever-changing environment with unforeseen events. As currently no single sensor is able to reliably perceive all relevant activity in the surroundings, sensor data fusion is applied to perceive as much information as possible. Data fusion of different sensors and sensor modalities on a low abstraction level enables the compensation of sensor weaknesses and misdetections among the sensors before the information-rich sensor data are compressed and thereby information is lost after a sensor-individual object detection. This paper develops a low-level sensor fusion network for 3D object detection, which fuses lidar, camera, and radar data. The fusion network is trained and evaluated on the nuScenes data set. On the test set, fusion of radar data increases the resulting AP (Average Precision) detection score by about 5.1% in comparison to the baseline lidar network. The radar sensor fusion proves especially beneficial in inclement conditions such as rain and night scenes. Fusing additional camera data contributes positively only in conjunction with the radar fusion, which shows that interdependencies of the sensors are important for the detection result. Additionally, the paper proposes a novel loss to handle the discontinuity of a simple yaw representation for object detection. Our updated loss increases the detection and orientation estimation performance for all sensor input configurations. The code for this research has been made available on GitHub.
A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection
May 15, 2020

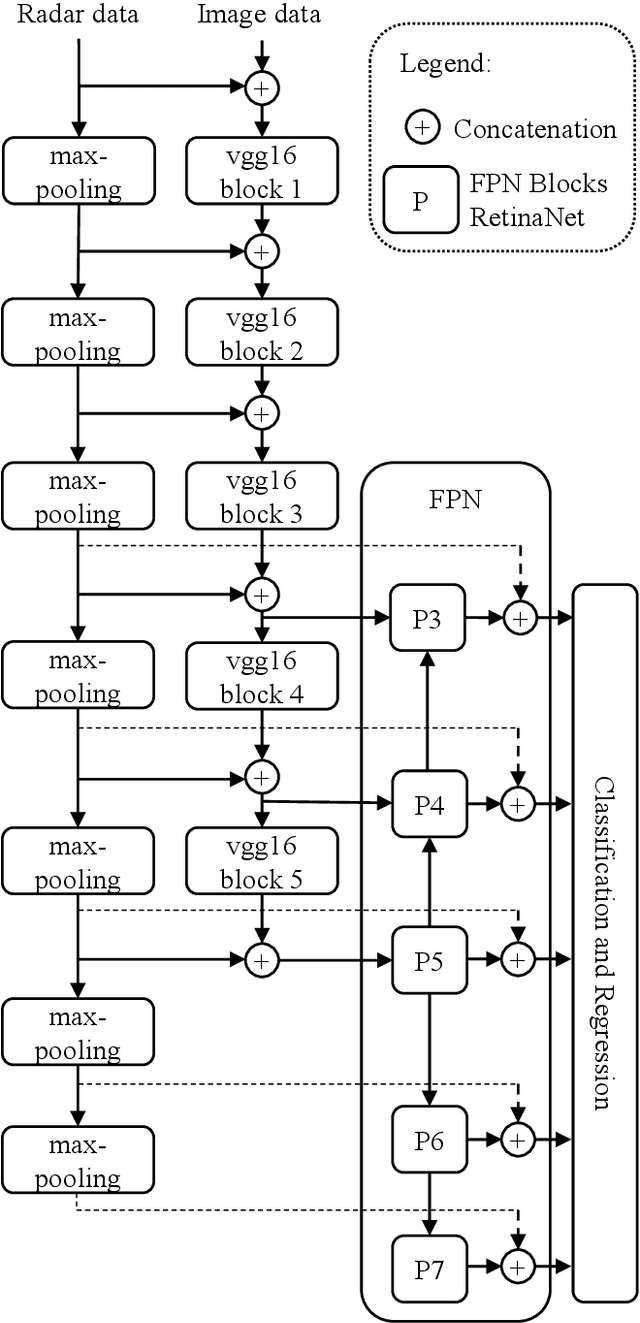

Object detection in camera images, using deep learning has been proven successfully in recent years. Rising detection rates and computationally efficient network structures are pushing this technique towards application in production vehicles. Nevertheless, the sensor quality of the camera is limited in severe weather conditions and through increased sensor noise in sparsely lit areas and at night. Our approach enhances current 2D object detection networks by fusing camera data and projected sparse radar data in the network layers. The proposed CameraRadarFusionNet (CRF-Net) automatically learns at which level the fusion of the sensor data is most beneficial for the detection result. Additionally, we introduce BlackIn, a training strategy inspired by Dropout, which focuses the learning on a specific sensor type. We show that the fusion network is able to outperform a state-of-the-art image-only network for two different datasets. The code for this research will be made available to the public at: https://github.com/TUMFTM/CameraRadarFusionNet.
Persistent Map Saving for Visual Localization for Autonomous Vehicles: An ORB-SLAM Extension
May 15, 2020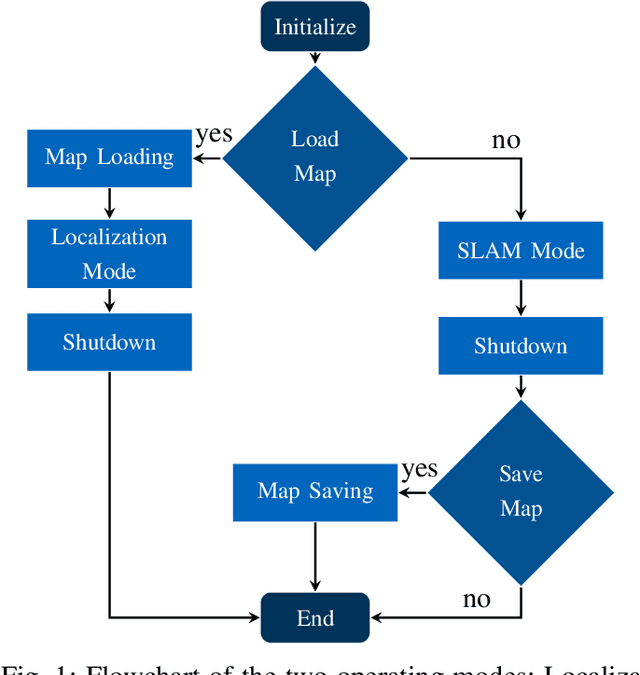


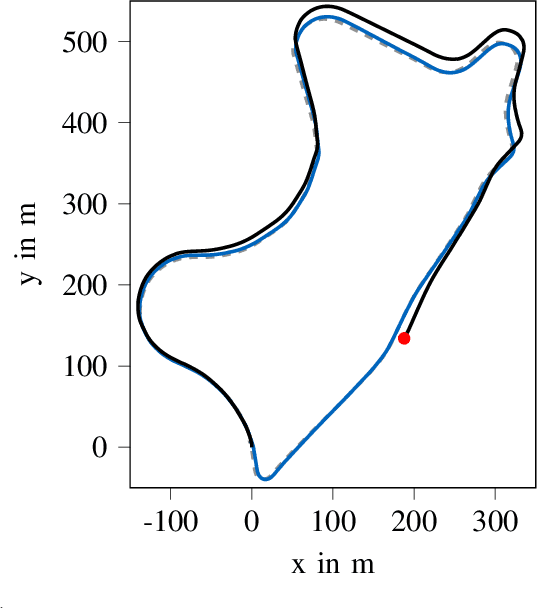
Electric vhicles and autonomous driving dominate current research efforts in the automotive sector. The two topics go hand in hand in terms of enabling safer and more environmentally friendly driving. One fundamental building block of an autonomous vehicle is the ability to build a map of the environment and localize itself on such a map. In this paper, we make use of a stereo camera sensor in order to perceive the environment and create the map. With live Simultaneous Localization and Mapping (SLAM), there is a risk of mislocalization, since no ground truth map is used as a reference and errors accumulate over time. Therefore, we first build up and save a map of visual features of the environment at low driving speeds with our extension to the ORB-SLAM\,2 package. In a second run, we reload the map and then localize on the previously built-up map. Loading and localizing on a previously built map can improve the continuous localization accuracy for autonomous vehicles in comparison to a full SLAM. This map saving feature is missing in the original ORB-SLAM\,2 implementation. We evaluate the localization accuracy for scenes of the KITTI dataset against the built up SLAM map. Furthermore, we test the localization on data recorded with our own small scale electric model car. We show that the relative translation error of the localization stays under 1\% for a vehicle travelling at an average longitudinal speed of 36 m/s in a feature-rich environment. The localization mode contributes to a better localization accuracy and lower computational load compared to a full SLAM. The source code of our contribution to the ORB-SLAM2 will be made public at: https://github.com/TUMFTM/orbslam-map-saving-extension.
Exploring the Capabilities and Limits of 3D Monocular Object Detection -- A Study on Simulation and Real World Data
May 15, 2020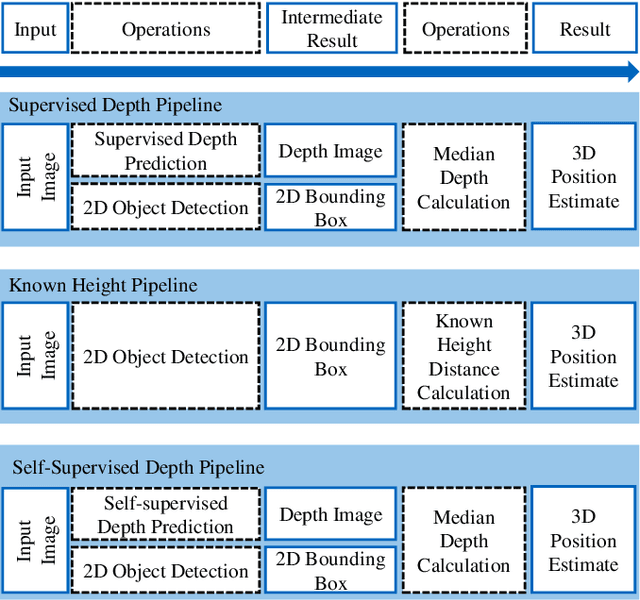

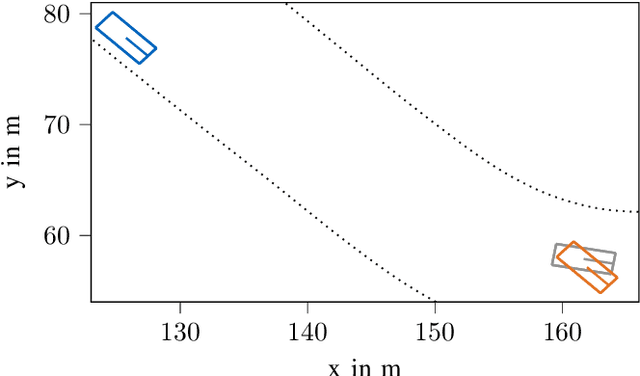
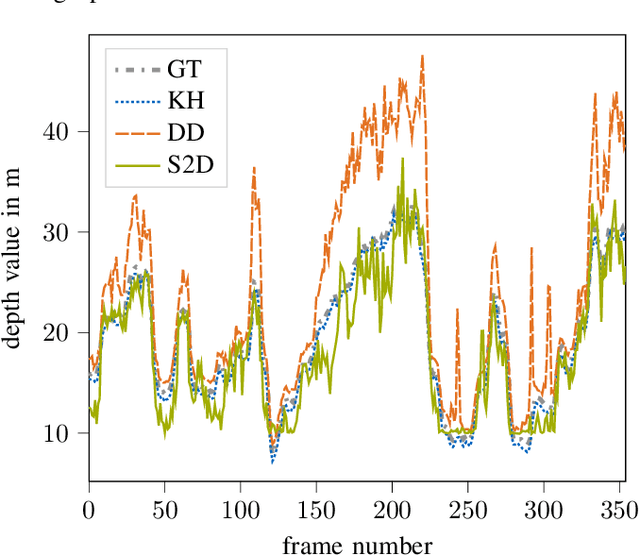
3D object detection based on monocular camera data is a key enabler for autonomous driving. The task however, is ill-posed due to lack of depth information in 2D images. Recent deep learning methods show promising results to recover depth information from single images by learning priors about the environment. Several competing strategies tackle this problem. In addition to the network design, the major difference of these competing approaches lies in using a supervised or self-supervised optimization loss function, which require different data and ground truth information. In this paper, we evaluate the performance of a 3D object detection pipeline which is parameterizable with different depth estimation configurations. We implement a simple distance calculation approach based on camera intrinsics and 2D bounding box size, a self-supervised, and a supervised learning approach for depth estimation. Ground truth depth information cannot be recorded reliable in real world scenarios. This shifts our training focus to simulation data. In simulation, labeling and ground truth generation can be automatized. We evaluate the detection pipeline on simulator data and a real world sequence from an autonomous vehicle on a race track. The benefit of simulation training to real world application is investigated. Advantages and drawbacks of the different depth estimation strategies are discussed.